
ZooKeeper學習第四期---構建ZooKeeper應用
一、配置服務
配置服務是分散式應用所需要的基本服務之一,它使叢集中的機器可以共享配置資訊中那些公共的部分。簡單地說,ZooKeeper可以作為一個具有高可用性的配置儲存器,允許分散式應用的參與者檢索和更新配置檔案。使用ZooKeeper中的觀察機制,可以建立一個活躍的配置服務,使那些感興趣的客戶端能夠獲得配置資訊修改的通知。
下面來編寫一個這樣的服務。我們通過兩個假設來簡化所需實現的服務(稍加修改就可以取消這兩個假設)。
第一,我們唯一需要儲存的配置資料是字串,關鍵字是znode的路徑,因此我們在每個znode上儲存了一個鍵/值對。
第二,在任何時候只有一個客戶端會執行更新操作。
除此之外,這個模型看起來就像是有一個主人(類似於HDFS中的namenode)在更新資訊,而他的工人則需要遵循這些資訊。
在名為ActiveKeyValueStore的類中編寫了如下程式碼:

package org.zk;
import java.nio.charset.Charset;
import org.apache.zookeeper.CreateMode;
import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.ZooDefs.Ids;
import org.apache.zookeeper.data.Stat;
public class ActiveKeyValueStore extends ConnectionWatcher {
private static final Charset CHARSET=Charset.forName("UTF-8");
public void write(String path,String value) throws KeeperException, InterruptedException {
Stat stat = zk.exists(path, false);
if(stat==null){
zk.create(path, value.getBytes(CHARSET),Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
}else{
zk.setData(path, value.getBytes(CHARSET),-1);
}
}
public String read(String path,Watcher watch) throws KeeperException, InterruptedException{
byte[] data = zk.getData(path, watch, null);
return new String(data,CHARSET);
}
}
write()方法的任務是將一個關鍵字及其值寫到ZooKeeper。它隱藏了建立一個新的znode和用一個新值更新現有znode之間的區 別,而是使用exists操作來檢測znode是否存在,然後再執行相應的操作。其他值得一提的細節是需要將字串值轉換為位元組陣列,因為我們只用了 UTF-8編碼的getBytes()方法。☆☆☆
read()方法的任務是讀取一個節點的配置屬性。ZooKeeper的getData()方法有三個引數:
(1)路徑
(2)一個觀察物件
(3)一個Stat物件
Stat物件由getData()方法返回的值填充,用來將資訊回傳給呼叫者。通過這個方法,呼叫者可以獲得一個znode的資料和元資料,但在這個例子中,由於我們對元資料不感興趣,因此將Stat引數設為null。
為了說明ActiveKeyValueStore的用法,我們編寫了一個用來更新配置屬性值的類ConfigUpdater,如程式碼1.1所示。
程式碼1.1 用於隨機更新ZooKeeper中的屬性
package org.zk;
import java.io.IOException;
import java.util.Random;
import java.util.concurrent.TimeUnit;
import org.apache.zookeeper.KeeperException;
public class ConfigUpdater {
public static final String PATH="/config";
private ActiveKeyValueStore store;
private Random random=new Random();
public ConfigUpdater(String hosts) throws IOException, InterruptedException {
store = new ActiveKeyValueStore();
store.connect(hosts);
}
public void run() throws InterruptedException, KeeperException{
while(true){
String value=random.nextInt(100)+"";
store.write(PATH, value);
System.out.printf("Set %s to %s\n",PATH,value);
TimeUnit.SECONDS.sleep(random.nextInt(100));
}
}
public static void main(String[] args) throws IOException, InterruptedException, KeeperException {
ConfigUpdater configUpdater = new ConfigUpdater(args[0]);
configUpdater.run();
}
}
這個程式很簡單,ConfigUpdater中定義了一個ActiveKeyValueStore,它在ConfigUpdater的建構函式中連線到ZooKeeper。run()方法永遠在迴圈,在隨機時間以隨機值更新/config znode。
作為配置服務的使用者,ConfigWatcher建立了一個ActiveKeyValueStore物件store,並且在啟動之後通過 displayConfig()呼叫了store的read()方法,顯示它所讀到的配置資訊的初始值,並將自身作為觀察傳遞給store。當節點狀態發 生變化時,再次通過displayConfig()顯示配置資訊,並再次將自身作為觀察傳遞給store,參見程式碼1.2:
例1.2 該用應觀察ZooKeeper中屬性的更新情況,並將其列印到控制檯
package org.zk;
import java.io.IOException;
import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.Watcher.Event.EventType;
public class ConfigWatcher implements Watcher{
private ActiveKeyValueStore store;
@Override
public void process(WatchedEvent event) {
if(event.getType()==EventType.NodeDataChanged){
try{
dispalyConfig();
}catch(InterruptedException e){
System.err.println("Interrupted. exiting. ");
Thread.currentThread().interrupt();
}catch(KeeperException e){
System.out.printf("KeeperException錛?s. Exiting.\n", e);
}
}
}
public ConfigWatcher(String hosts) throws IOException, InterruptedException {
store=new ActiveKeyValueStore();
store.connect(hosts);
}
public void dispalyConfig() throws KeeperException, InterruptedException{
String value=store.read(ConfigUpdater.PATH, this);
System.out.printf("Read %s as %s\n",ConfigUpdater.PATH,value);
}
public static void main(String[] args) throws IOException, InterruptedException, KeeperException {
ConfigWatcher configWatcher = new ConfigWatcher(args[0]);
configWatcher.dispalyConfig();
//stay alive until process is killed or Thread is interrupted
Thread.sleep(Long.MAX_VALUE);
}
}
當ConfigUpdater更新znode時,ZooKeeper產生一個型別為EventType.NodeDataChanged的 事件,從而觸發觀察。ConfigWatcher在它的process()方法中對這個事件做出反應,讀取並顯示配置的最新版本。由於觀察僅傳送單次信 號,因此每次我們呼叫ActiveKeyValueStore的read()方法時,都將一個新的觀察告知ZooKeeper來確保我們可以看到將來的更 新。但是,我們還是不能保證接收到每一個更新,因為在收到觀察事件通知與下一次讀之間,znode可能已經被更新過,而且可能是很多次,由於客戶端在這段 時間沒有註冊任何觀察,因此不會收到通知。對於示例中的配置服務,這不是問題,因為客戶端只關心屬性的最新值,最新值優先於之前的值。但是,一般情況下, 這個潛在的問題是不容忽視的。
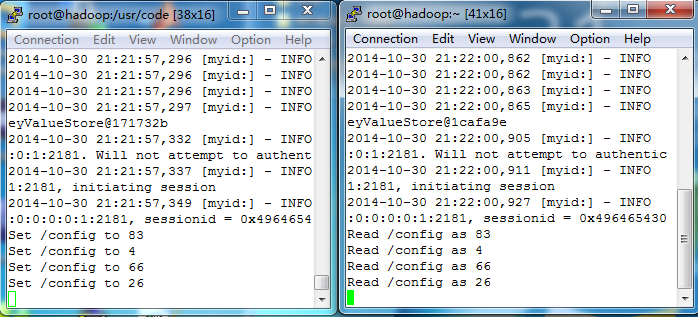
讓我們看看如何使用這個程式。在一個終端視窗中執行ConfigUpdater,然後在另一個客戶端執行ConfigWatcher,我們可以預先 分別在兩個客戶端輸入命令,先不按回車,等兩個客戶端的命令輸入好後,先在執行ConfigUpdater的客戶端按回車,再在另一個客戶端按回車,執行 結果如下:
二、可恢復的ZooKeeper應用
關於分散式計算的第一個誤區是“網路是可靠的”。按照他們的觀點,程式總是有一個可靠的網路,因此當程式執行在真正的網路中時,往往會出現各種備樣的故障。讓我們看看各種可能的故障模式,以及能夠解決故障的措施,使我們的程式在面對故障時能夠及時復原。
2.1 ZooKeeper異常
在Java API中的每一個ZooKeeper操作都在其throws子句中聲明瞭兩種型別的異常,分別是InterruptedException和KeeperException。
(一)InterruptedException異常
如果操作被中斷,則會有一個InterruptedException異常被丟擲。在Java語言中有一個取消阻塞方法的標準機制,即針對存在阻塞方法的執行緒呼叫interrupt()。一個成功的取消操作將產生一個InterruptedException異常。
ZooKeeper也遵循這一機制,因此你可以使用這種方法來取消一個ZooKeeper操作。使用了ZooKeeper的類或庫通常會傳播 InterruptedException異常,使客戶端能夠取消它們的操作。InterruptedException異常並不意味著有故障,而是表明相應的操作已經被取消,所以在配置服務的示例中,可以通過傳播異常來中止應用程式的執行。
(二)KeeperException異常
(1) 如果ZooKeeper伺服器發出一個錯誤訊號或與伺服器存在通訊問題,丟擲的則是KeeperException異常。
①針對不同的錯誤情況,KeeperException異常存在不同的子類。
例如: KeeperException.NoNodeException是KeeperException的一個子類,如果你試圖針對一個不存在的znode執行操作,丟擲的則是該異常。
②每一個KeeperException異常的子類都對應一個關於錯誤型別資訊的程式碼。
例如: KeeperException.NoNodeException異常的程式碼是KeeperException.Code.NONODE
(2) 有兩種方法被用來處理KeeperException異常:
①捕捉KeeperException異常,並且通過檢測它的程式碼來決定採取何種補救措施;
②另一種是捕捉等價的KeeperException子類,並且在每段捕捉程式碼中執行相應的操作。
(3) KeeperException異常分為三大類
① 狀態異常
當一個操作因不能被應用於znode樹而導致失敗時,就會出現狀態異常。狀態異常產生的原因通常是在同一時間有另外一個程序正在修改znode。例如,如果一個znode先被另外一個程序更新了,根據版本號執行setData操作的程序就會失敗,並收到一個KeeperException.BadVersionException異常,這是因為版本號不匹配。程式設計師通常都知道這種衝突總是存在的,也都會編寫程式碼來進行處理。
一些狀態異常會指出程式中的錯誤,例如KeeperException.NoChildrenForEphemeralsException異常,試圖在短暫znode下建立子節點時就會丟擲該異常。
② 可恢復異常
可恢復的異常是指那些應用程式能夠在同一個ZooKeeper會話中恢復的異常。一個可恢復的異常是通過KeeperException.ConnectionLossException來表示的,它意味著已經丟失了與ZooKeeper的連線。ZooKeeper會嘗試重新連線,並且在大多數情況下重新連線會成功,並確保會話是完整的。
但是ZooKeeper不能判斷與KeeperException.ConnectionLossException異常相關的操作是否成功執行。這種情況就是部分失敗的一個例子。這時程式設計師有責任來解決這種不確定性,並且根據應用的情況來採取適當的操作。在這一點上,就需要對“冪等”(idempotent)操作和“非冪等”(Nonidempotent)操作進行區分。冪等操作是指那些一次或多次執行都會產生相同結果的操作,例如讀請求或無條件執行的setData操作。對於冪等操作,只需要簡單地進行重試即可。對於非冪等操作,就不能盲目地進行重試,因為它們多次執行的結果與一次執行是完全不同的。程式可以通過在znode的路徑和它的資料中編碼資訊來檢測是否非冪等操怍的更新已經完成。
③不可恢復的異常
在某些情況下,ZooKeeper會話會失效——也許因為超時或因為會話被關閉,兩種情況下都會收到KeeperException.SessionExpiredException異常,或因為身份驗證失敗,KeeperException.AuthFailedException異常。無論上述哪種情況,所有與會話相關聯的短暫znode都將丟失,因此應用程式需要在重新連線到ZooKeeper之前重建它的狀態。
2.2 可靠地服務配置
首先我們先回顧一下ActivityKeyValueStore的write()的方法,他由一個exists操作緊跟著一個create操作或setData操作組成:
public class ActiveKeyValueStore extends ConnectionWatcher {
private static final Charset CHARSET=Charset.forName("UTF-8");
public void write(String path,String value) throws KeeperException, InterruptedException {
Stat stat = zk.exists(path, false);
if(stat==null){
zk.create(path, value.getBytes(CHARSET),Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
}else{
zk.setData(path, value.getBytes(CHARSET),-1);
}
}
public String read(String path,Watcher watch) throws KeeperException, InterruptedException{
byte[] data = zk.getData(path, watch, null);
return new String(data,CHARSET);
}
}
作為一個整體,write()方法是一個“冪等”操作,所以我們可以對他進行無條件重試。我們新建一個類ChangedActiveKeyValueStore,程式碼如下:
package org.zk;
import java.nio.charset.Charset;
import java.util.concurrent.TimeUnit;
import org.apache.zookeeper.CreateMode;
import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.ZooDefs.Ids;
import org.apache.zookeeper.data.Stat;
public class ChangedActiveKeyValueStore extends ConnectionWatcher{
private static final Charset CHARSET=Charset.forName("UTF-8");
private static final int MAX_RETRIES = 5;
private static final long RETRY_PERIOD_SECONDS = 5;
public void write(String path,String value) throws InterruptedException, KeeperException{
int retries=0;
while(true){
try {
Stat stat = zk.exists(path, false);
if(stat==null){
zk.create(path, value.getBytes(CHARSET),Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
}else{
zk.setData(path, value.getBytes(CHARSET),stat.getVersion());
}
} catch (KeeperException.SessionExpiredException e) {
throw e;
} catch (KeeperException e) {
if(retries++==MAX_RETRIES){
throw e;
}
//sleep then retry
TimeUnit.SECONDS.sleep(RETRY_PERIOD_SECONDS);
}
}
}
public String read(String path,Watcher watch) throws KeeperException, InterruptedException{
byte[] data = zk.getData(path, watch, null);
return new String(data,CHARSET);
}
}
在該類中,對前面的write()進行了修改,該版本的wirte()能夠迴圈執行重試。其中設定了重試的最大次數MAX_RETRIES和兩次重試之間的間隔RETRY_PERIOD_SECONDS.
我們再新建一個類ResilientConfigUpdater,該類對前面的ConfigUpdater進行了修改,程式碼如下:
package org.zk;
import java.io.IOException;
import java.nio.charset.Charset;
import java.util.Random;
import java.util.concurrent.TimeUnit;
import org.apache.zookeeper.CreateMode;
import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.KeeperException.SessionExpiredException;
import org.apache.zookeeper.ZooDefs.Ids;
import org.apache.zookeeper.data.Stat;
public class ResilientConfigUpdater extends ConnectionWatcher{
public static final String PATH="/config";
private ChangedActiveKeyValueStore store;
private Random random=new Random();
public ResilientConfigUpdater(String hosts) throws IOException, InterruptedException {
store=new ChangedActiveKeyValueStore();
store.connect(hosts);
}
public void run() throws InterruptedException, KeeperException{
while(true){
String value=random.nextInt(100)+"";
store.write(PATH,value);
System.out.printf("Set %s to %s\n",PATH,value);
TimeUnit.SECONDS.sleep(random.nextInt(10));
}
}
public static void main(String[] args) throws Exception {
while(true){
try {
ResilientConfigUpdater configUpdater = new ResilientConfigUpdater(args[0]);
configUpdater.run();
}catch (KeeperException.SessionExpiredException e) {
// start a new session
}catch (KeeperException e) {
// already retried ,so exit
e.printStackTrace();
break;
}
}
}
}
在這段程式碼中沒有對KeepException.SeeionExpiredException異常進行重試,因為一個會話過期 時,ZooKeeper物件會進入CLOSED狀態,此狀態下它不能進行重試連線。我們只能將這個異常簡單丟擲並讓擁有著建立一個新例項,以重試整個 write()方法。一個簡單的建立新例項的方法是建立一個新的ResilientConfigUpdater用於恢復過期會話。
處理會話過期的另一種方法是在觀察中(在這個例子中應該是ConnectionWatcher)尋找型別為ExpiredKeepState,然後 再找到的時候建立一個新連線。即使我們收到KeeperException.SessionExpiredEception異常,這種方法還是可以讓我們 在write()方法內不斷重試,因為連線最終是能夠重新建立的。不管我們採用何種機制從過期會話中恢復,重要的是,這種不同於連線丟失的故障型別,需要 進行不同的處理。
注意:實際上,這裡忽略了另一種故障模式。當ZooKeeper物件被建立時,他會嘗試連線另一個ZooKeeper伺服器。如果連線失敗或超時, 那麼他會嘗試連線集合體中的另一臺伺服器。如果在嘗試集合體中的所有伺服器之後仍然無法建立連線,它會丟擲一個IOException異常。由於所有的 ZooKeeper伺服器都不可用的可能性很小,所以某些應用程式選擇迴圈重試操作,直到ZooKeeper服務為止。
這僅僅是一種重試處理策略,還有許多其他處理策略,例如使用“指數返回”,每次將重試的間隔乘以一個常數。Hadoop核心中 org.apache.hadoop.io.retry包是一組工具,用於可以重用的方式將重試邏輯加入程式碼,因此他對於構建ZooKeeper應用非常 有用。
三、鎖服務
3.1分散式鎖概述
分散式鎖在一組程序之間提供了一種互斥機制。在任何時刻,在任何時刻只有一個程序可以持有鎖。分散式鎖可以在大型分散式系統中實現領導者選舉,在任何時間點,持有鎖的那個程序就是系統的領導者。
注意:不要將ZooKeeper自己的領導者選舉和使用了ZooKeeper基本操作實現的一般領導者選混為一談。ZooKeeper自己的領導者選舉機制是對外不公開的,我們這裡所描述的一般領導者選舉服務則不同,他是對那些需要與主程序保持一致的分散式系統所設計的。
(1) 為了使用ZooKeeper來實現分散式鎖服務,我們使用順序znode來為那些競爭鎖的程序強制排序。
思路很簡單:
① 首先指定一個作為鎖的znode,通常用它來描述被鎖定的實體,稱為/leader;
② 然後希望獲得鎖的客戶端建立一些短暫順序znode,作為鎖znode的子節點。
③ 在任何時間點,順序號最小的客戶端將持有鎖。
例如,有兩個客戶端差不多同時建立znode,分別為/leader/lock-1和/leader/lock-2,那麼建立/leader/lock-1的客戶端將會持有鎖,因為它的znode順序號最小。ZooKeeper服務是順序的仲裁者,因為它負責分配順序號。
④ 通過刪除znode /leader/lock-l即可簡單地將鎖釋放;
⑤ 另外,如果客戶端程序死亡,對應的短暫znode也會被刪除。
⑥ 接下來,建立/leader/lock-2的客戶端將持有鎖,因為它順序號緊跟前一個。
⑦ 通過建立一個關於znode刪除的觀察,可以使客戶端在獲得鎖時得到通知。
(2) 如下是申請獲取鎖的虛擬碼。
①在鎖znode下建立一個名為lock-的短暫順序znode,並且記住它的實際路徑名(create操作的返回值)。
②查詢鎖znode的子節點並且設定一個觀察。
③如果步驟l中所建立的znode在步驟2中所返回的所有子節點中具有最小的順序號,則獲取到鎖。退出。
④等待步驟2中所設觀察的通知並且轉到步驟2。
3.2 當前問題與方案
3.2.1 羊群效應
(1) 問題
雖然這個演算法是正確的,但還是存在一些問題。第一個問題是這種實現會受到“羊群效應”(herd effect)的影響。考慮有成百上千客戶端的情況,所有的客戶端都在嘗試獲得鎖,每個客戶端都會在鎖znode上設定一個觀察,用於捕捉子節點的變化。 每次鎖被釋放或另外一個程序開始申請獲取鎖的時候,觀察都會被觸發並且每個客戶端都會收到一個通知。 “羊群效應“就是指大量客戶端收到同一事件的通知,但實際上只有很少一部分需要處理這一事件。在這種情況下,只有一個客戶端會成功地獲取鎖,但是維護過程及向所有客戶端傳送觀察事件會產生峰值流量,這會對ZooKeeper伺服器造成壓力。
(2) 方案解決方案
為了避免出現羊群效應,我們需要優化通知的條件。關鍵在於只有在前一個順序號的子節點消失時才需要通知下一個客戶端,而不是刪除(或建立)任何子節點時都需要通知。在我們的例子中,如果客戶端建立了znode /leader/lock-1、/leader/lock-2和/leader/lock-3,那麼只有當/leader/lock-2消失時才需要通知/leader/lock-3對照的客戶端;/leader/lock-1消失或有新的znode /leader/lock-4加入時,不需要通知該客戶端。
3.2.2 可恢復的異常
(1) 問題
這個申請鎖的演算法目前還存在另一個問題,就是不能處理因連線丟失而導致的create操作失敗。如前所述,在這種情況下,我們不知道操作是成功還是失敗。由於建立一個順序znode是非冪等操作,所以我們不能簡單地重試,因為如果第一次建立已經成功,重試會使我們多出一個永遠刪不掉的孤兒zriode(至少到客戶端會話結束前)。不幸的結果是將會出現死鎖。
(2) 解決方案
問題在於,在重新連線之後客戶端不能夠判斷它是否已經建立過子節點。解決方案是在znode的名稱中嵌入一個ID,如果客戶端出現連線丟失的情況, 重新連線之後它便可以對鎖節點的所有於節點進行檢查,看看是否有子節點的名稱中包含其ID。如果有一個子節點的名稱包含其ID,它便知道建立操作已經成 功,不需要再建立子節點。如果沒有子節點的名稱中包含其ID,則客戶端可以安全地建立一個新的順序子節點。
客戶端會話的ID是一個長整數,並且在ZooKeeper服務中是唯一的,因此非常適合在連線丟失後用於識別客戶端。可以通過呼叫Java ZooKeeper類的getSessionld()方法來獲得會話的ID。
在建立短暫順序znode時應當採用lock-<sessionld>-這樣的命名方式,ZooKeeper在其尾部新增順序號之後,znode的名稱會形如lock-<sessionld>-<sequenceNumber>。由於順序號對於父節點來說是唯一的,但對於子節點名並不唯一,因此採用這樣的命名方式可以詿子節點在保持建立順序的同時能夠確定自己的建立者。
3.2.3 不可恢復的異常
如果一個客戶端的ZooKeeper會話過期,那麼它所建立的短暫znode將會被刪除,已持有的鎖會被釋放,或是放棄了申請鎖的位置。使用鎖的應 用程式應當意識到它已經不再持有鎖,應當清理它的狀態,然後通過建立並嘗試申請一個新的鎖物件來重新啟動。注意,這個過程是由應用程式控制的,而不是鎖, 因為鎖是不能預知應用程式需要如何清理自己的狀態。
四、ZooKeeper實現共享鎖
實現正確地實現一個分散式鎖是一件棘手的事,因為很難對所有型別的故障都進行正確的解釋處理。ZooKeeper帶有一個 JavaWriteLock,客戶端可以很方便地使用它。更多分散式資料結構和協議例如“屏障”(bafrier)、佇列和兩階段提交協議。有趣的是它們 都是同步協議,即使我們使用非同步ZooKeeper基本操作(如通知)來實現它們。使用ZooKeeper可以實現很多不同的分散式資料結構和協 議,ZooKeeper網站(http://hadoop.apache.org/zookeeper/)提供了一些用於實現分散式資料結構和協議的虛擬碼。ZooKeeper本身也帶有一些棕準方法的實現,放在安裝位置下的recipes目錄中。
4.1 場景描述
大家也許都很熟悉了多個執行緒或者多個程序間的共享鎖的實現方式了,但是在分散式場景中我們會面臨多個Server之間的鎖的問題。
假設有這樣一個場景:兩臺server :serverA,serverB需要在C機器上的/usr/local/a.txt文 件上進行寫操作,如果兩臺機器同時寫該檔案,那麼該檔案的最終結果可能會產生亂序等問題。最先能想到的是serverA在寫檔案前告訴ServerB “我要開始寫檔案了,你先別寫”,等待收到ServerB的確認回覆後ServerA開始寫檔案,寫完檔案後再通知ServerB“我已經寫完了”。假設 在我們場景中有100臺機器呢,中間任意一臺機器通訊中斷了又該如何處理?容錯和效能問題呢?要能健壯,穩定,高可用並保持高效能,系統實現的複雜度比較 高,從頭開發這樣的系統代價也很大。幸運的是,我們有了基於googlechubby原理開發的開源的ZooKeeper系統。接下來本文將介紹兩種 ZooKeeper實現分散式共享鎖的方法。
4.2 利用節點名稱的唯一性來實現共享鎖
ZooKeeper表面上的節點結構是一個和unix檔案系統類似的小型的樹狀的目錄結構,ZooKeeper機制規定:同一個目錄下只能有一個唯一的檔名。
例如:我們在Zookeeper目錄/test目錄下建立,兩個客戶端建立一個名為lock節點,只有一個能夠成功。
(1) 演算法思路:利用名稱唯一性,加鎖操作時,只需要所有客戶端一起建立/Leader/lock節點,只有一個建立成功,成功者獲得鎖。解鎖時,只需刪除/test/Lock節點,其餘客戶端再次進入競爭建立節點,直到所有客戶端都獲得鎖。
基於以上機制,利用節點名稱唯一性機制的共享鎖演算法流程如圖所示:

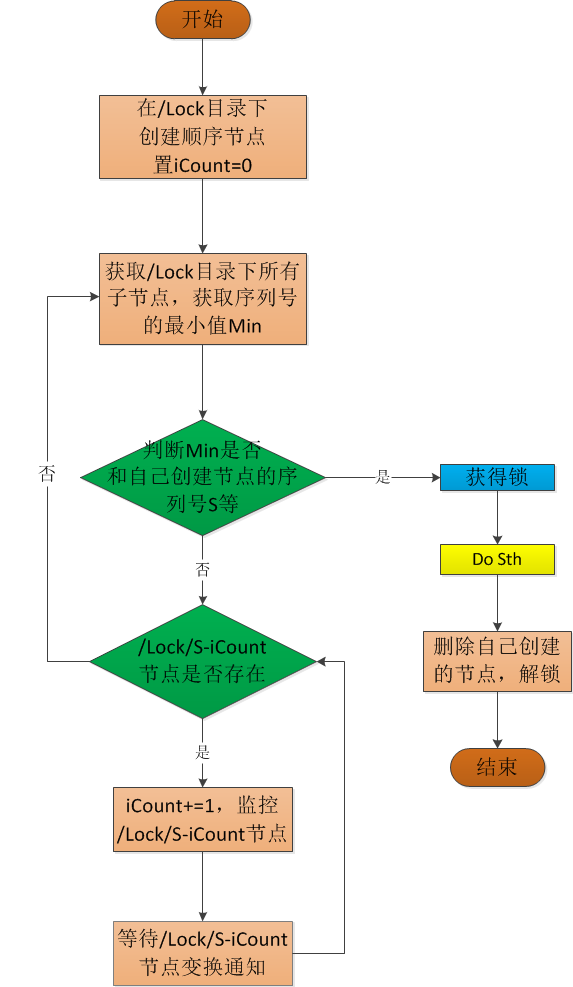
4.3 利用順序節點實現共享鎖
首先介紹一下,Zookeeper中有一種節點叫做順序節點,故名思議,假如我們在/lock/目錄下建立節3個點,ZooKeeper叢集會按照提起建立的順序來建立節點,節點分別為/lock/0000000001、/lock/0000000002、/lock/0000000003。
ZooKeeper中還有一種名為臨時節點的節點,臨時節點由某個客戶端建立,當客戶端與ZooKeeper叢集斷開連線,。則該節點自動被刪除。
演算法思路:對於加鎖操作,可以讓所有客戶端都去/lock目錄下建立臨時、順序節點,如果建立的客戶端發現自身建立節點序列號是/lock/目錄下最小的節點,則獲得鎖。否則,監視比自己建立節點的序列號小的節點(當前序列在自己前面一個的節點),進入等待。解鎖操作,只需要將自身建立的節點刪除即可。具體演算法流程如下圖所示:
4.4 ZooKeeper提供的一個寫鎖實現
按照ZooKeeper提供的分散式鎖的虛擬碼,實現了一個分散式鎖的簡單測試程式碼如下:
(1)分散式鎖,實現了Lock介面 DistributedLock.java
package com.concurrent;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.Lock;
import org.apache.zookeeper.CreateMode;
import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.ZooDefs;
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.data.Stat;
/**
DistributedLock lock = null;
try {
lock = new DistributedLock("127.0.0.1:2182","test");
lock.lock();
//do something...
} catch (Exception e) {
e.printStackTrace();
}
finally {
if(lock != null)
lock.unlock();
}
* @author xueliang
*
*/
public class DistributedLock implements Lock, Watcher{
private ZooKeeper zk;
private String root = "/locks";//根
private String lockName;//競爭資源的標誌
private String waitNode;//等待前一個鎖
private String myZnode;//當前鎖
private CountDownLatch latch;//計數器
private int sessionTimeout = 30000;
private List<Exception> exception = new ArrayList<Exception>();
/**
* 建立分散式鎖,使用前請確認config配置的zookeeper服務可用
* @param config 127.0.0.1:2181
* @param lockName 競爭資源標誌,lockName中不能包含單詞lock
*/
public DistributedLock(String config, String lockName){
this.lockName = lockName;
// 建立一個與伺服器的連線
try {
zk = new ZooKeeper(config, sessionTimeout, this);
Stat stat = zk.exists(root, false);
if(stat == null){
// 建立根節點
zk.create(root, new byte[0], ZooDefs.Ids.OPEN_ACL_UNSAFE,CreateMode.PERSISTENT);
}
} catch (IOException e) {
exception.add(e);
} catch (KeeperException e) {
exception.add(e);
} catch (InterruptedException e) {
exception.add(e);
}
}
/**
* zookeeper節點的監視器
*/
public void process(WatchedEvent event) {
if(this.latch != null) {
this.latch.countDown();
}
}
public void lock() {
if(exception.size() > 0){
throw new LockException(exception.get(0));
}
try {
if(this.tryLock()){
System.out.println("Thread " + Thread.currentThread().getId() + " " +myZnode + " get lock true");
return;
}
else{
waitForLock(waitNode, sessionTimeout);//等待鎖
}
} catch (KeeperException e) {
throw new LockException(e);
} catch (InterruptedException e) {
throw new LockException(e);
}
}
public boolean tryLock() {
try {
String splitStr = "_lock_";
if(lockName.contains(splitStr))
throw new LockException("lockName can not contains \\u000B");
//建立臨時子節點
myZnode = zk.create(root + "/" + lockName + splitStr, new byte[0], ZooDefs.Ids.OPEN_ACL_UNSAFE,CreateMode.EPHEMERAL_SEQUENTIAL);
System.out.println(myZnode + " is created ");
//取出所有子節點
List<String> subNodes = zk.getChildren(root, false);
//取出所有lockName的鎖
List<String> lockObjNodes = new ArrayList<String>();
for (String node : subNodes) {
String _node = node.split(splitStr)[0];
if(_node.equals(lockName)){
lockObjNodes.add(node);
}
}
Collections.sort(lockObjNodes);
System.out.println(myZnode + "==" + lockObjNodes.get(0));
if(myZnode.equals(root+"/"+lockObjNodes.get(0))){
//如果是最小的節點,則表示取得鎖
return true;
}
//如果不是最小的節點,找到比自己小1的節點
String subMyZnode = myZnode.substring(myZnode.lastIndexOf("/") + 1);
waitNode = lockObjNodes.get(Collections.binarySearch(lockObjNodes, subMyZnode) - 1);
} catch (KeeperException e) {
throw new LockException(e);
} catch (InterruptedException e) {
throw new LockException(e);
}
return false;
}
public boolean tryLock(long time, TimeUnit unit) {
try {
if(this.tryLock()){
return true;
}
return waitForLock(waitNode,time);
} catch (Exception e) {
e.printStackTrace();
}
return false;
}
private boolean waitForLock(String lower, long waitTime) throws InterruptedException, KeeperException {
Stat stat = zk.exists(root + "/" + lower,true);
//判斷比自己小一個數的節點是否存在,如果不存在則無需等待鎖,同時註冊監聽
if(stat != null){
System.out.println("Thread " + Thread.currentThread().getId() + " waiting for " + root + "/" + lower);
this.latch = new CountDownLatch(1);
this.latch.await(waitTime, TimeUnit.MILLISECONDS);
this.latch = null;
}
return true;
}
public void unlock() {
try {
System.out.println("unlock " + myZnode);
zk.delete(myZnode,-1);
myZnode = null;
zk.close();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (KeeperException e) {
e.printStackTrace();
}
}
public void lockInterruptibly() throws InterruptedException {
this.lock();
}
public Condition newCondition() {
return null;
}
public class LockException extends RuntimeException {
private static final long serialVersionUID = 1L;
public LockException(String e){
super(e);
}
public LockException(Exception e){
super(e);
}
}
}
(2)併發測試工具 ConcurrentTest.java
package com.concurrent;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.concurrent.CopyOnWriteArrayList;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.atomic.AtomicInteger;
/**
ConcurrentTask[] task = new ConcurrentTask[5];
for(int i=0;i<task.length;i++){
task[i] = new ConcurrentTask(){
public void run() {
System.out.println("==============");
}};
}
new ConcurrentTest(task);
* @author xueliang
*
*/
public class ConcurrentTest {
private CountDownLatch startSignal = new CountDownLatch(1);//開始閥門
private CountDownLatch doneSignal = null;//結束閥門
private CopyOnWriteArrayList<Long> list = new CopyOnWriteArrayList<Long>();
private AtomicInteger err = new AtomicInteger();//原子遞增
private ConcurrentTask[] task = null;
public ConcurrentTest(ConcurrentTask... task){
this.task = task;
if(task == null){
System.out.println("task can not null");
System.exit(1);
}
doneSignal = new CountDownLatch(task.length);
start();
}
/**
* @param args
* @throws ClassNotFoundException
*/
private void start(){
//建立執行緒,並將所有執行緒等待在閥門處
createThread();
//開啟閥門
startSignal.countDown();//遞減鎖存器的計數,如果計數到達零,則釋放所有等待的執行緒
try {
doneSignal.await();//等待所有執行緒都執行完畢
} catch (InterruptedException e) {
e.printStackTrace();
}
//計算執行時間
getExeTime();
}
/**
* 初始化所有執行緒,並在閥門處等待
*/
private void createThread() {
long len = doneSignal.getCount();
for (int i = 0; i < len; i++) {
final int j = i;
new Thread(new Runnable(){
public void run() {
try {
startSignal.await();//使當前執行緒在鎖存器倒計數至零之前一直等待
long start = System.currentTimeMillis();
task[j].run();
long end = (System.currentTimeMillis() - start);
list.add(end);
} catch (Exception e) {
err.getAndIncrement();//相當於err++
}
doneSignal.countDown();
}
}).start();
}
}
/**
* 計算平均響應時間
*/
private void getExeTime() {
int size = list.size();
List<Long> _list = new ArrayList<Long>(size);
_list.addAll(list);
Collections.sort(_list);
long min = _list.get(0);
long max = _list.get(size-1);
long sum = 0L;
for (Long t : _list) {
sum += t;
}
long avg = sum/size;
System.out.println("min: " + min);
System.out.println("max: " + max);
System.out.println("avg: " + avg);
System.out.println("err: " + err.get());
}
public interface ConcurrentTask {
void run();
}
}
(3)測試 ZkTest.java
package com.concurrent;
import com.concurrent.ConcurrentTest.ConcurrentTask;
public class ZkTest {
public static void main(String[] args) {
Runnable task1 = new Runnable(){
public void run() {
DistributedLock lock = null;
try {
lock = new DistributedLock("127.0.0.1:2182","test1");
//lock = new DistributedLock("127.0.0.1:2182","test2");
lock.lock();
Thread.sleep(3000);
System.out.println("===Thread " + Thread.currentThread().getId() + " running");
} catch (Exception e) {
e.printStackTrace();
}
finally {
if(lock != null)
lock.unlock();
}
}
};
new Thread(task1).start();
try {
Thread.sleep(1000);
} catch (InterruptedException e1) {
e1.printStackTrace();
}
ConcurrentTask[] tasks = new ConcurrentTask[60];
for(int i=0;i<tasks.length;i++){
ConcurrentTask task3 = new ConcurrentTask(){
public void run() {
DistributedLock lock = null;
try {
lock = new DistributedLock("127.0.0.1:2183","test2");
lock.lock();
System.out.println("Thread " + Thread.currentThread().getId() + " running");
} catch (Exception e) {
e.printStackTrace();
}
finally {
lock.unlock();
}
}
};
tasks[i] = task3;
}
new ConcurrentTest(tasks);
}
}
4.5 更多分散式資料結構和協議
使用ZooKeeper可以實現很多不同的分散式資料結構和協議,例如“屏障”(bafrier)、佇列和兩階段提交協議。有趣的是它們都是同步協議,即使我們使用非同步ZooKeeper基本操作(如通知)來實現它們。
ZooKeeper網站(http://hadoop.apache.org/zookeeper)提供了一些用於實現分散式資料結構和協議的虛擬碼。ZooKeeper本身也帶有一些棕準方法的實現,放在安裝位置下的recipes目錄中。
五、BooKeeper
5.1 BooKeeper概述
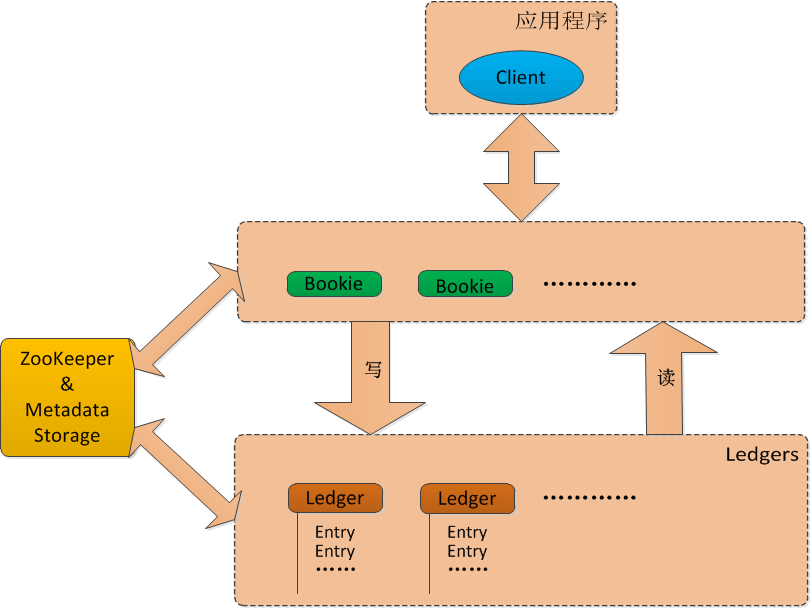
BooKeeper具有副本功能,目的是提供可靠的日誌記錄。在BooKeeper中,伺服器被稱為賬本(Bookies),在賬本之中有不同的賬戶(Ledgers),每一個賬戶由一條條記錄(Entry)組成。如果使用普通的磁碟儲存日誌資料,那麼日誌資料可能遭到破壞,當磁碟發生故障的時候,日誌也可能被丟失。BooKeeper為每一份日誌提供了分散式的儲存,並採用了大多數(quorum,相對於全體)的概念。也就是說,只要叢集中的大多數機器可用,那麼該日誌一直有效。
BooKeeper通過客戶端進行操作,客戶端可以對BooKeeper進行新增賬戶、開啟賬戶、新增賬戶記錄、讀取賬戶記錄等操作。另外,BooKeeper的服務依賴於ZooKeeper,可以說BooKeeper依賴於ZooKeeper的一致性及其分散式特點,在其之上提供另外一種可靠性服務。BooKeeper的架構如下圖所示:☆
5.2 BooKeeper角色
從上圖中可以看出,BooKeeper中總共包含四類角色:
① 賬本:Bookies
② 賬戶:Ledger
③ 客戶端:Client
④ 元資料及儲存服務:Metadata Storage Service
下面簡單介紹這四類角色的功能:
(1) 賬本 BooKies
賬本是BooKeeper的儲存伺服器,他儲存的是一個個的賬本,可以將賬本理解為一個個節點。在一個BooKeeper系統中存在多個賬本(節點),每個賬戶被不同的賬本所儲存。若要寫一條記錄到指定的賬戶中,該記錄將被寫到維護該賬戶所有帳本節點中。為了提高系統的效能,這條記錄並不是真正的被寫入到所有的節點中,而是選擇叢集的一個大多數集進行儲存。該系統獨有的特性,使得BooKeeper系統有良好的擴充套件性。即,我們可以通過簡單的新增機器節點的方法提高系統容量。☆☆
(2) 賬戶 Ledger
賬戶中儲存的是一系列記錄,每一條記錄包含一定的欄位。記錄通過寫操作一次性寫入,只能進行附加操作不能進行修改。每條記錄包含如下欄位:
當滿足下列兩個條件時,某條記錄才被認為是儲存成功:
① 之前所記錄的資料被賬本節點的大多數集所儲存。
② 該記錄被賬本節點的大多數集所儲存。
(3) 客戶端 BooKeeper Client
客戶端通常與BooKeeper應用程式進行互動,它允許應用程式在系統上進行操作,包括建立賬戶,寫賬戶等。
(4) 元資料儲存服務 Metadata Storage Service
元資料資訊儲存在ZooKeeper叢集當中,它儲存關於賬戶和賬本的資訊。例如,賬本由叢集中的哪些節點進行維護,賬戶由哪個賬本進行維護。應用 程式在使用賬本的時候,首先要建立一個賬戶。在建立賬戶時,系統首先將該賬本的Metadata資訊寫入到ZooKeeper中。每一個賬戶在某一時刻只 能有一個寫例項(分散式鎖)。在其他例項進行讀操作之前首先需要將寫例項關閉。如果寫操作例項由於故障未能正常關閉,那麼下一個嘗試開啟賬戶的例項將需要 首先對其進行恢復,並正確關閉寫操作。在進行寫操作的同時需要將最後一次的寫記錄儲存到ZooKeeper中,因此恢復程式僅需要在ZooKeeper中檢視該賬戶所對應的最後一條寫記錄,然後將其正確的寫入到賬戶中,再在正確關閉寫操作。在BooKeeper中該恢復程式有系統自動執行不需要使用者參與。