
21.Bayesian Saliency via Low and Mid Level Cues
低階和中級線索的貝葉斯顯著性
摘要
視覺顯著性檢測是計算機視覺領域中一個具有挑戰性的問題,同時也是一個重要的應用領域。在本文中,我們通過利用中低層次線索,在貝葉斯框架內提出了一種自下而上顯著性的新模型。與直接在低水平線索上操作的大多數現有方法相比,我們提出了一種演算法,首先通過最優點的凸包獲得粗糙的顯著區域。我們還通過超畫素分析中級視覺線索的顯著性資訊。我們提出了一種拉普拉斯稀疏子空間聚類方法,用於對具有區域性特徵的超畫素進行分組,並分析關於粗顯著區域的結果,以計算先前的顯著圖。我們使用基於凸包的低階視覺線索來計算觀測可能性,從而有助於推斷每個畫素的貝葉斯顯著性。對大型資料集進行的大量實驗表明,我們的貝葉斯顯著性模型對最先進的演算法表現出色。
Ⅰ.引言
生物視覺系統傾向於自然地在場景中找到資訊最豐富的區域,然後進一步處理該區域的豐富視覺內容。近年來,已經提出了許多計算顯著性模型來模擬用於解決資訊過載問題的生物視覺系統。計算機視覺中的許多工,例如影象分類[1],興趣區域檢測[2],影象壓縮[3],[4]和目標定位[5]也受益於顯著性檢測作為關注該區域的預處理步驟非常重要。
顯著性測量與我們如何感知和處理視覺刺激密切相關,通常會得到一張對映圖,其中每個值描述畫素如何從影象的周圍環境中突出。從資訊處理的角度來看,這些演算法可以分為自下而上(刺激驅動)或自上而下(目標導向)方法。自上而下的顯著性度量涉及特定的物件類,並且該圖指示它們的例項可能在場景中發生的位置。從監督方式的包含物件例項的大量影象中學習特定類的顯著視覺資訊。相比之下,自下而上的顯著圖主要基於低階視覺刺激來制定。經常採用的原則之一是中心-環繞對比度,其通過與其鄰域的差異來計算畫素或區域的顯著性。由於沒有提供關於顯著物體的尺寸的先驗知識,因此通常以多個尺度計算對比度。此外,為了定位顯著物件,通常需要使用滑動視窗進行窮舉搜尋。另一種通常採用的自下而上的方法是資訊最大化原理,其已被應用於預測眼睛固定的位置。這一原理表明,為了有效地分析場景[6],人類視覺系統傾向於關注影象中資訊量最大的點。通常學習自然影象統計的稀疏程式碼來模擬靈長類動物的初級視覺皮層中的簡單細胞感受野[7],[8],用於計算顯著性圖譜。
雖然現有的自下而上顯著性模型已經顯示了令人印象深刻的結果,但仍有幾個問題需要解決。其中一個主要問題是,自下而上的方法通常比雜亂背景中的感興趣物件更多地響應於許多不相關的低階視覺刺激。另一個問題在於它們無法均勻地突出顯著性物件,因為中心環繞方法通常突出物體邊界,並且資訊最大化顯著性模型傾向於關注眼睛注視點。最後,一些自下而上的演算法在計算上是昂貴的,因為它們通常需要在多個尺度和鄰域處進行窮舉搜尋以計算每個畫素處的顯著性度量。
在本文中,我們利用貝葉斯顯著性模型通過利用中低水平線索來生成基於中心環繞原理的顯著性圖來解決這些問題。首先,我們計算興趣點的凸包,用於顯著物件的粗略區域估計。基於粗顯著區域和拉普拉斯稀疏子空間聚類方法計算所提出的貝葉斯顯著性模型的先驗圖。與通過掃描視窗和周圍區域的對比來衡量顯著性的[9]不同,我們的公式通過利用中層線索和更好的[10]指標來更加高效和有效。我們的聚類方法擴充套件了稀疏子空間聚類[11]通過在超畫素級引入具有拉普拉斯矩陣的正則化項。該正則化項進一步強制將類似的超畫素聚集到同一組中。此外,我們利用凸包內外的低水平視覺線索來計算每個畫素點的觀測概率,從而計算出貝葉斯顯著性測度。我們廣泛地評估了所提出的貝葉斯模型在所提出的聚類演算法,先驗概率和對公共可用基準資料集的顯著性度量方面的效能以及標籤註釋。與最先進的顯著性方法相比,我們的貝葉斯模型顯示出優於現有方法的顯著改進,具有更高的查準率和查全率。
Ⅱ.相關工作
近年來,[9]、[12]-[29]、[30]-[33]等視覺顯著模型的研究取得了顯著進展。為了解釋基於不同數學原理的視覺注意力,已經提出了許多自下而上的模型。Itti等[16]提出了一種自下而上的方法,其中輸入影象用三個特徵表示,包括不同尺度的顏色,強度和方向。通過兩個尺度之間的濾波器響應的差異來實現中心環繞操作,以獲得給定特徵的一組特徵圖。然後將特徵圖歸一化併線性組合以構建最終顯著圖。Kadir和Brady[20]基於區域性鄰域內影象內容的夏農熵定義顯著性,與Gilles[19]不同,考慮了多尺度鄰域表示。布魯斯和茨沃斯[21]開發一種方法,通過獨立分量分析來最大化本地影象內容的自資訊,以推斷顯著性圖。在[22]中,Harel等人在影象上定義圖形並使用隨機遊走來計算視覺顯著性。一個點的顯著性測量值與隨機遊動平衡點的訪問頻率成正比。與自下而上的顯著性模型不同,它只處理輸入影象,張等人[24]提出了一種利用自然影象統計資料的自下而上的顯著性度量。當受試者自由地觀察影象時(即,不主動搜尋特定目標),它們的顯著性模型在預測人眼固定方面表現良好。在[25]中,Achanta等利用中心環繞原理,通過比較每個畫素的顏色特徵和整個影象的平均值來計算顯著性。雖然這種方法簡單而有效,但對於背景雜亂的影象卻無效。此外,由於缺乏先驗知識,在中心環繞原理中通常採用多尺度對比[9],[27]或多線索積分[34]技術來增強顯著性圖以突出顯示真正的顯著物件。
中等水平線索包含豐富的影象結構資訊,有助於高水平的視覺感知和影象分析[35]。類似於視覺皮層中V1細胞的功能,中等水平線索將定位,對比度,視差,顏色,空間頻率的區域性測量考慮為推斷影象結構。已經提出了許多演算法來利用中等水平線索進行視覺任務[36]-[40]。最近,Cheng等人[28]提出了一種基於區域對比度的顯著性提取演算法,該演算法具有中等水平線索,同時評估全域性對比度差異和空間連續性。在[29],開發了三個基於區域性,區域和全域性特徵的特徵圖,並與訓練的條件隨機場模型整合。馮等人[41]提出了一種基於分段的方法,其中視覺顯著性是通過用影象的其餘部分組成視窗補丁的成本來測量的。
自上而下的演算法通過考慮特定物件的視覺資訊來提出顯著性檢測問題。張等人[24]提出了一種貝葉斯框架來檢測潛在物件,其中已知目標類別的自上而下的資訊由似然函式建模。在[42]中,Barlow的推理原理被用於特徵選擇和自上而下的顯著性檢測。該顯著性檢測器在選擇用於在雜波中定位物件的辨別特徵方面表現良好。Marchesotti等人[43]利用影象之間的視覺相似性來計算顯著性圖。給定一個測試影象,他們首先從資料庫中檢索一些最相似的影象,然後學習一個帶有Fisher核心的簡單分類器來分離顯著(前景)和非顯著(背景)區域。然而,由於視覺影象搜尋和線上分類器訓練,該方法不可避免地需要大量的計算負荷。
Ⅲ.提出的演算法
在本節中,我們使用低階和中級線索提出了一種高效且有效的貝葉斯顯著性模型。我們首先介紹貝葉斯公式的基本符號,然後介紹基於凸包的粗略區域粗略估計方法,其中包括來自低級別線索的所有檢測到的興趣點。接下來,基於具有由超畫素和粗顯著區域表示的中等水平線索的新型聚類演算法來估計先驗分佈。最後,基於具有粗顯著區域的中心環繞原理並因此針對影象的貝葉斯視覺顯著性圖譜來計算觀察似然性(後驗概率)。
興趣點檢測器用於定位物件的突出點。接下來,計算包圍突出點的凸包以估計近似突出區域。基於估計的區域,我們將顯著性檢測表示為貝葉斯推斷問題,用於估計影象每個畫素v處的後驗概率:

其中, p(sal|v)是預測畫素突出的概率的簡寫p(sal=1|v),p(sal)是在畫素v處突出的先驗概率(第III-B節),而p(bk)是先驗概率屬於背景的畫素。 另外,p(v|sal)和p(v|bk)是觀察的可能性(p(v|sal=1)和p(v|bk = 1)的縮寫)(第III-C部分)。目標是產生顯著性圖譜,其中估計每個畫素顯著的概率。圖1顯示了兩種方法生成的一些顯著性圖。

A.通過興趣點檢測粗略顯著區域
基於中心環繞原理的現有方法通常以低水平線索操作。也就是說,相對於畫素鄰域的對比度被計算為其顯著性值。雖然這些演算法表現出有希望的結果,但是這些方法在計算上可能是昂貴的並且不使用包含在中等水平線索中的結構資訊。顯著目標通常不能被均勻地識別,因為可以基於低水平線索僅確定沿著輪廓具有高對比度的一些畫素。此外,通常引入誤報畫素,因為顯著性度量僅基於低級別線索計算。
Rahtu等介紹一種基於貝葉斯推理的方法[9],其中通過對影象應用滑動視窗並比較核心內外的畫素來計算顯著性度量。然而,該方法需要對滑動視窗進行窮舉掃描,因為不利用顯著區域的結構資訊。在本文中,我們首先使用顯著點來計算顯著物件的大致位置,然後利用該區域的屬性來計算最終顯著性圖。這種方法不僅有助於降低高計算成本,而且還使得所提出的顯著圖更具辨別力。
大多數興趣點檢測器不利用顏色資訊,並且可能對背景噪聲敏感。Weijer等[44]建議利用灰度和顏色通道的梯度資訊來測量顯著性。基於其頻率或概率計算彩色影象導數的資訊,並且開發變換函式以提高顏色顯著性。然後在影象上操作彩色Harris檢測器[45]以檢測特徵點。與基於強度的特徵檢測器相比,增強的顏色顯著點顯示更穩定和更豐富[44]。
在本文中,我們使用顏色增強的Harris點運算元[44]來檢測彩色影象中顯著區域的角點或輪廓點(圖2(b))。顯著點提供關於場景中的感興趣物件的有用空間資訊。我們消除了影象邊界附近的那些,並計算了一個凸包以包圍所有剩餘的突出點(圖2(c))。由於檢測到的興趣點通常圍繞顯著物件,因此該方法提供粗略區域估計。從這個凸包中,我們提取有用的資訊來計算先驗分佈和觀測可能性。

B.先驗分佈
與貝葉斯框架中使用統一先驗分佈[9],[46]制定的現有方法相比,我們提出了一個概率先驗圖來更好地描述顯著性度量。基於超畫素聚類的結果計算所提出的先驗圖(圖2(d)))和粗略顯著區域。在本文中,我們提出了拉普拉斯稀疏子空間聚類(LSSC)方法來分組超畫素。譜聚類的主要問題之一是如何構建有效的鄰接矩陣,準確地描述每對畫素之間的相似性。考慮全連線的圖通常是冗餘且低效的,並且現有方法使用區域性鄰域資訊(例如,高斯核)來計算矩陣。然而,這些方法通常會遇到隨之而來的規模問題,並且幾乎總是忽略具有大空間距離的點對之間的相似性。
1.稀疏子空間聚類演算法(SSC)
在[11]中,提出了一種利用稀疏相似性矩陣進行譜聚類的演算法。觀察的動機是,子空間並集中的每個資料點總是可以表示為所有其他點的線性或仿射組合。假設每個點屬於唯一子空間,它可以由該子空間的一小組點表示。因此,當考慮整組資料點時,每個點都具有稀疏表示。通過搜尋每個點的最稀疏組合,它確定位於同一子空間中的點。這導致稀疏的相似性矩陣,通過類似於[47]的方式,可以通過譜聚類來獲得分割。
給出一個新的資料點u,它可以表示為同一子空間中點的仿射組合。每個點的稀疏表示u ∈Rd可以通過以下修改後的基礎追蹤演算法[48]恢復:
![]()
其中U = {u1,u2 ,…,uN}是N個點的資料矩陣,最優解c∈RN中的非零項對應於與當前點u相同的子空間中的點。令U`i∈RD×(N-1)是通過去除其第i列ui而從矩陣U獲得的矩陣。點ui具有關於基矩陣U`i的稀疏表示:
![]()
其中ci∈R(N-1)。在實踐中,需要考慮噪聲項,並用¯ui= ui +ηi對第i個點進行建模,其中噪聲項ηi由||ηi||2≤ε限定。
可以用正則化項
![]()
來計算¯ui的稀疏表示。但是,由於η通常是未知的,因此通過以下方法解決了最佳問題:
![]()
其中γ是一個小常數。固定γ後,(5)可以轉換為:
![]()
其中λ是一個小常數(我們在實驗中根據經驗將λ設定為0.01)。利用每個點的最稀疏表示,獲得描述點之間的連線的關聯矩陣。
2.拉普拉斯稀疏子空間聚類(LSSC)
雖然SSC方法在聚類中表現良好,但它僅使用低級別的視覺提示。在這項工作中,我們通過超畫素利用中級視覺資訊進行聚類。此外,已經表明,由於過度完整的字典(資料矩陣U),兩個相似資料點(即,該工作中的超畫素)的小變化可能導致對碼本基礎的顯著性不同的響應。鑑於此,我們計算約束矩陣,以類似於[49]的方式編碼每對超畫素之間的關係。在(6)中引入了基於約束矩陣的拉普拉斯正則化項,以強制類似的超畫素應該具有相似的稀疏係數。將約束(關聯)矩陣表示為W,由此產生的優化問題是:

其中L是拉普拉斯矩陣,定義為L = H - W,H是具有行和的對角矩陣,Hii =∑j Wij. 引數α是平衡約束正則化項的影響的權重(我們在實驗中根據經驗將其設定為α),並且我們通過求解(5)來初始化ci。通過在ci的第i行插入零向量,我們獲得N維向量,`ci∈RN。
由於超畫素包含相似的畫素並保留了顯著物件的結構資訊,因此該表示由於其穩定性和效率而被用於聚類。在該工作中,使用SLIC演算法[50]將影象分割成N(例如,在該工作中N = 200)超畫素,儘管也可以採用其他方法。我們將這N個超畫素視為從n個獨立線性子空間的並集中繪製的資料點的集合,表示為 {ui} Ni=1,ui∈RD,並應用所提出的LSSC演算法將它們聚類成n個組。
對於超畫素內的每個影象畫素,我們用九維特徵向量s表示它,
![]()
其中l,a和b是CIELab顏色空間中的畫素值,Ix,Iy,Ixx,Iyy是x和y軸上影象強度相應的一階或二階導數,x,y是影象的畫素。引數β是顏色,影象梯度和空間特徵之間的折衷。與顏色和影象漸變特徵的操作類似,我們將空間資訊x,y標準化為[0,1]。基本原理是屬於顯著目標的畫素傾向於在空間距離方面更接近,而非顯著目標的畫素通常在影象中展開。然而,如果我們對空間特徵使用相等權重(β= 1),則屬於非顯著目標畫素的聚類結果通常不準確(例如,大物件的畫素可以被分成兩個聚類)。因此,我們根據經驗選擇β= 0.5來緩解這個問題。
得到的超畫素通常很小,並且包含的畫素非常相似。對於每個超畫素,我們計算平均特徵向量u

其中K是超畫素的大小。從每個超畫素的特徵向量u,我們得到資料矩陣
U={ui}Ni=1。我們計算協方差矩陣來描述超畫素在特徵向量s方面的關係。 對於每個超畫素,我們計算計算9×9協方差矩陣M:
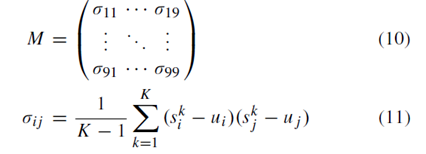
其中ski是當前超畫素的第k個畫素的第i個特徵,ui是第i個特徵的平均值(即,超畫素的特徵向量u中的第i個元素)。
給定兩個超畫素,我們根據相應的協方差矩陣M1和M2計算它們的距離,以測量不相似性[10]:
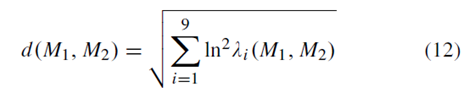
其中{λi(M1,M2)}9i=1是|λM1 - M2 |=0的廣義特徵值。這個距離測量服從所有度量公理[10]。基於該距離,我們計算約束矩陣W的每個元素,其通過以下方式測量兩個超畫素的相似性:
![]()
其中ρ是一個小常數(例如,在這項工作中ρ= 0.5)。
我們從約束矩陣W計算拉普拉斯矩陣L,用資料矩陣U求解(7),其中我們以類似於[49]的方法迭代優化每個稀疏編碼ci。然後我們得到一個稀疏係數矩陣C =[`c1,`c2,…,`cn]∈RN×N,不一定是對稱的。用於譜聚類的對稱相似性矩陣由`Cij = |Cij+Cji|。如果`Cij非零,該對稱矩陣`C用於定義圖G =(V,E),其中頂點V是N個超畫素,並且邊緣(vi,vj)∈E。矩陣`C是圖G的鄰接矩陣。圖G的拉普拉斯矩陣A由鄰接矩陣A=B-`C構成,其中B是具有行和的對角矩陣,Bii=Σj`Cij。我們應用K-means演算法聚類拉普拉斯矩陣A的特徵向量以推斷分割。圖3(b)(e)顯示了使用我們的方法的一些聚類結果。

3.先驗對映
我們的聚類方法可以將影象正確地聚類到n個分割槽中,從中可以很好地分割顯著目標。然而,在不知道目標物件的情況下以無監督的方式執行聚類演算法。我們使用凸包來解決這個問題。鑑於第III-A節中描述的檢測到的突出點,我們發現一個凸包將它們包圍起來。我們基於屬於凸包的畫素數量來測量聚類(片段)的顯著性。因此,我們定義了叢集畫素顯著性的先驗概率

其中cluster表示一個簇,hull表示包含突出點的凸包,|·|表示集合中元素的總數。對於不與凸包重疊的簇(即,顯著物件的粗略估計),先驗概率為零。 對於與凸包相交的簇的畫素,相應的先驗概率是相同的。先驗顯著性圖譜的一些結果顯示在圖3(c)(f)中,其顯示所提出的先驗圖與聚類結果密切相關。
C.觀察似然性(後驗概率)
我們基於中心環繞原理計算(2)的似然概率p(v|sal)。如圖4(a)所示,基於核心及其邊界的顏色分佈計算畫素的觀察似然性。[9]中的方法比現有方法產生更多的判別式顯著性對映,但由於視窗的詳盡掃描考慮了多個尺度的鄰域,因此它在計算上是昂貴的。相反,如圖4(b)所示,使用凸包來估計粗略顯著區域顯著地減少了計算負荷。給定興趣點的凸包,我們只需要計算每個畫素相對於顯著區域的顯著性。

凸包將影象分成兩個不相交的區域:內部區域I和外面區域的O。由於所有突出點都分佈在區域I中,因此I中的畫素傾向於顯著,而O中的畫素更可能是背景的一部分。該假設在[9],[51]中得到了成功應用。單個畫素的顯著性由其與I畫素的相似性以及與使用顏色直方圖的O的相似性確定。使用CIELab顏色空間,因為它被設計用於模擬人類視覺感知,並同時保留亮度和顏色資訊。對於由[l(v),a(v),b(v)]表示的每個畫素v,我們計算區域I和O的顏色直方圖。設NI為I中的畫素數和NI(f(v))f∈{l,a,b}是區域I包含f(v)的個數。同樣,我們用O表示O中畫素的顏色直方圖,NO(NO(f(v))f∈{l,a,b}。 為了提高效率,假設CIELab顏色空間的三個通道是獨立的。以與[9]相同的方式計算畫素v處的觀察似然
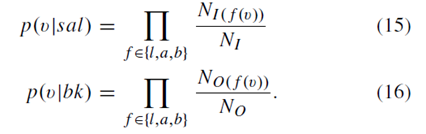
將先驗(14)和觀測似然函式(15)和(16)插入(2),我們獲得貝葉斯顯著性圖譜,其為影象的每個畫素分配概率。
Ⅳ. . 實驗
我們提出了經驗評估和分析所提出的貝葉斯顯著性模型與MSRA顯著物件資料庫[52]上最先進的方法和標記的基礎事實[25]。MSRA資料集包括兩組25,000個影象,其中每個顯著物件用矩形手動標記。從這個集合中,1000個影象的顯著物件被手動分割[25]以獲得具有畫素精度的地面實況資料。MATLAB原始碼可從http://faculty.ucmerced.edu/mhyang/code獲得。
- 凸包和聚類演算法的評估
對於每個影象,我們提取30個興趣點並移除影象邊界附近的那些(例如,在影象邊界的26個畫素內)。基於實驗中使用的1,000個影象,檢測到的興趣點的平均數量是25並且標準偏差是4。我們測量檢測到的興趣點的凸包和包含有標籤的顯著性區域的重疊區域(即,|hull∩GF|/|hull|)。平均比率超過60%,因此凸包提供了對顯著物體的良好估計。
在提出的演算法中,我們利用聚類結果來計算先前的顯著性圖譜。由於這是我們方法的重要一步,我們使用其他聚類方法評估結果。為了繪製PR曲線,我們使用固定閾值來確定畫素是否顯著。如[25]中所述,我們通過將閾值Tf從0變為255來對具有標籤的1,000個影象進行實驗。精度P和召回R值由下式定義
![]()
其中SF表示具有特定閾值的二進位制分割之後的分割前景畫素集合,GF表示該組標籤的前景畫素。曲線展示了這些先驗圖譜如何突出影象中的顯著區域,並提供對兩種聚類演算法的公平評估。
為了證明拉普拉斯關係項的有效性,我們使用建議的LSSC方法將每個影象分割成n個叢集(其中,n的變化在從4到9)並獲得先驗圖譜。圖5中顯示了1000張影象的結果,我們將簇數n設定為7,以便在查準率和查全率之間進行最佳權衡。
我們使用基於SSC方法和提出的LSSC演算法的先驗圖譜來比較顯著性檢測結果。PR曲線如圖5(b)所示,一些聚類結果如圖5(c)所示。建議的LSSC方法優於SSC,因為它不僅可以更精確地聚類每個顯著物件(例如,標誌,游泳者和鴨子),而且還可以更好地保留邊界。請注意,我們的LSSC方法的目標是儘可能精確地對顯著物件進行聚類,因此非顯著區域是否分組良好並不重要。總的來說,基於我們的LSSC方法的先驗圖譜實現了更高的精度和召回率。我們的演算法相對於SSC方法的效能增益可歸因於所提出的正則化項。

B.先驗圖譜的評估
為了證明我們先驗圖譜的有效性,我們進行了一個比較實驗,該實驗使用統一概率進行顯著性檢測,並將其稱為常數先驗概率模型(CPPM)。CPPM方法是貝葉斯模型,其將恆定先驗概率和所提出的觀察似然(後驗概率)相結合以獲得顯著性圖。也就是說,CPPM和RA10[9]方法都使用相同的先驗概率但具有不同的觀測似然函式(前者基於檢測到的興趣點的凸包,而後者基於滑動視窗)。CPPM方法和我們的顯著性模型都利用第III-C節中描述的觀察似然,但是一個具有所提出的先驗對映(即,每個畫素處的先驗概率p(sal))而另一個具有針對每個畫素的均勻分佈,如[9]所示。這三個顯著圖的一些結果如圖6所示,PR曲線如圖8所示。由於CPPM和RA10方法使用相同的統一先驗概率但具有不同的觀察似然函式,結果表明所提出的似然函式的有效性。此外,我們的方法優於使用每個畫素的均勻先驗的CPPM和RA10方法,這證明了將所提出的先驗圖譜結合到貝葉斯顯著性檢測中的有效性。

- 顯著圖譜模型的評估
我們使用幾種最先進的方法評估提出的顯著性模型:IT98[16],GB06[22],AC09[25],RA10[9]和GC11[28]。為了公平評估,我們使用作者提供的原始碼。IT98和GB06模型不生成全解析度顯著圖,我們將圖譜縮放到與輸入影象相同的尺寸以進行比較。
圖7顯示了一些樣本結果,其中較亮的畫素表示較高的顯著概率。在大多數情況下,IT98和GB06模型能夠定位顯著物件,但顯著性圖以低解析度生成,並傾向於突出邊界併為物件內的畫素分配相對較低的概率。AC09方法通過其與整個影象平均值的顏色對比來估計每個畫素的顯著性,並且當顯著區域和背景具有相似顏色或感興趣物件相對較大時,它不能很好地工作。另一方面,AC09方法僅使用CIELab中的顏色特徵對複雜場景效果較差的空間。RA10模型比IT98和AC09方法更精確地定位顯著物件,但由於使用掃描視窗,它傾向於突出顯示背景畫素。GC11演算法根據顏色和空間對比計算區域顯著性,並且在突出顯示小顯著物件時表現良好。但是,它也不可避免地錯誤地識別小背景色塊,並且不能標記顯著物件內的所有畫素。我們的方法優於RA10模型,特別是當突出物體的尺寸很大時。對於具有雜色物件的場景,例如圖7的最後兩行中的鮮花和氣球,GC11模型不能正確估計顯著性圖。

總的來說,我們的模型能夠更好地估計雜亂背景中物體輪廓內和輪廓上的畫素級別的顯著性圖。此外,如圖7的前兩行所示,我們的顯著性度量不假設場景中只有一個顯著物件。當影象中存在多個物件時,突出點檢測器確定包含它們的最大顯著區域的邊界,然後我們的模型使用所提出的先驗圖譜以及觀察似然函式來定位各個區域。
為了進一步評估這些方法和第IV-B節中討論的CPPM方法,我們基於這些顯著性圖譜分割顯著物件並評估分割結果。我們將閾值從0更改為255以獲得不同的分段並計算PR曲線。如圖8(a)所示,我們的顯著模型達到了最佳效能,精度高於0.9。CPPM方法比RA10模型表現更好,這表明了所提出的先驗概率TUPU
的有效性。

當閾值Tf接近255,IT98,GB06,AC09和GC11模型的召回值減少到0,因為它們的顯著性圖譜不響應注意物件,如圖7(b)(c)(d)所示和(f)。所提出的方法和RA10模型的最小召回值不會降至零,因為相應的顯著圖能夠有效地檢測具有強響應的顯著區域。此外,我們方法的最小召回值高於RA10模型,這表明我們的顯著圖更精確並且對顯著區域有響應。
- 視覺注意和影象分割的應用
許多顯著性圖譜模型已應用於視覺注意和目標分割。Ma和Zhang[54]在其顯著圖上使用區域增長和模糊理論來定位矩形的注意物件。韓等人[55]採用馬爾可夫隨機場基於其顯著性圖和諸如顏色,紋理和邊緣的低階特徵對突出物件的畫素進行分組。Achanta等[25]從平均移位聚類演算法獲得的片段內的平均顯著性值和用於物件分割的靈活閾值。在[28],Cheng等人應用顯著性圖結果來初始化用於目標分割的迭代抓取演算法[56],而我們使用圖切割演算法[53]在這項工作中。設L表示影象的二進位制分割,Lv是每個畫素的標號v∈V,可以是前景obj或背景bkg。 能量函式E定義為
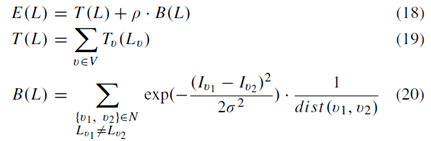
其中dist(v1,v2)是兩個畫素之間的歐幾里德距離。邊界項B(L)描述了分段L的邊界屬性,終端項Tv(Lv)是將標籤Lv分配給畫素v的代價。我們使用我們的顯著性圖譜來將終端項Tv(Lv)初始化為
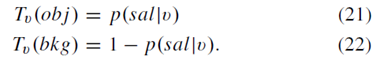
一些分割結果如圖9所示。邊界項B(L)通過我們的顯著性圖譜與終端項T(L)互補,以獲得更好的分割結果。圖形切割演算法適當地移除在顯著性圖譜中錯誤地檢測到的非顯著畫素並描繪突出物件的邊界。

我們將圖切割演算法應用於具有不同顯著性圖的影象分割以進行評估。對於每個分割的影象,我們使用標籤計算精度,召回率和F-度量。F-measure定義為

其中P和R表示精確度和召回率。在我們的實驗中,我們將β2設定為0.3,以便比[25]中建議的更高的召回率進行稱重。基於顯著性圖譜的每個分割的精確度,召回率和F-度量被平均超過1,000個影象,結果顯示在圖8(b)中。在所有方法中,我們的演算法以更高的召回率(0.87)和最佳的F測量值之一(0.75)實現最佳準確度。我們注意到報告的值與[28]中報告的值不同,因為在實驗中使用了不同的圖切割演算法(即,我們使用從[28]生成的顯著性圖譜和圖切割演算法[53])。均勻顯著性圖譜方法和GC11模型獲得了更好的精度分數,但它們的召回值遠低於我們的方法。請注意,AC09模型在分割中表現較差,因為其顯著性圖譜不是如圖7所示的尖銳,並且沒有很好地描繪顯著性區域(即,其終端項T(L)無效)。可以在http://faculty.ucmerced.edu/mhyang/saliency-map12.html找到1,000張影象的分割結果。
E.失敗案例
我們的貝葉斯顯著性模型對現有演算法表現出色,具有更高的精度和召回率。然而,由於先驗圖譜和觀測似然都是基於包圍突出點的凸包,如果興趣點沒有出現在顯著區域周圍或者點在相當大的區域上散佈,則所提出的方法不能很好地工作,如圖10(b)所示。另外,當聚類結果不精確時,一些背景畫素可能被錯誤地包括在所提出的先驗圖譜中(圖10(c))。在這種情況下,最終顯著性圖僅最小化不精確的先驗概率分佈的影響,但不完全去除背景畫素,如圖10(d)和(e)所示。另一方面,其他顯著圖模型在這種情況下表現不佳。
F.討論
在我們演算法的主要組成部分中,最重要的是提出的先驗圖譜和具有超畫素的聚類。在第IV-B節和圖6中,我們展示了我們的演算法生成的一些先驗圖譜,並對其他方法進行了評估。建議的顯著性地圖模型中最耗時的部分在於它所涉及的LSSC步驟ℓ1優化。另外,其他顏色興趣點檢測器也可以用在所提出的演算法中。此外,儘管在我們的演算法中可以使用其他分割方法(例如,[57]),但是與在超畫素中獲得的有效且有效的中間水平表示相比,是否可以獲得額外的改進尚不清楚。此類分析超出了本工作的範圍,最適合特定應用。
Ⅴ.結論
在本文中,我們使用低階和中級視覺線索在貝葉斯框架內提出了一種新穎的自下而上顯著性模型。基於資訊顯著點,引入了不需要對視窗進行窮舉掃描或選擇適當的鄰域尺度的演算法。此外,我們使用稀疏表示在超畫素級別提出了一種新的影象聚類方法,並將其應用於計算顯著性的先驗分佈。我們將先驗概率圖納入貝葉斯推理框架,並在具有標記的1,000個影象資料集上評估我們的方法。實驗結果證明了聚類方法和顯著性圖譜模型的有效性。與最先進的演算法相比,我們的方法生成更具辨別力的顯著性圖譜,具有更高的精度和召回率。此外,由於既不需要先前的學習過程也不需要特定的影象類別,我們的演算法可以很容易地與其他應用程式合併作為關鍵的初始化步驟,例如使用圖形切割的影象分割。
這裡從網上找到一篇盧湖川老師在2011年發表的文章的見解,看一看幫助理解是可以的.
Visual Saliency Detection Based on Bayesian Model, Yulin Xie, ICIP2011
https://blog.csdn.net/zzb4702/article/details/51711703