
隱馬爾科夫模型(前向後向演算法、鮑姆-韋爾奇演算法、維特比演算法)
概率圖模型是一類用圖來表達變數相關關係的概率模型。它以圖為表示工具,最常見的是用一個結點表示一個或一組隨機變數,結點之間的變表是變數間的概率相關關係。根據邊的性質不同,可以將概率圖模型分為兩類:一類是使用有向無環圖表示變數間的依賴關係,稱為有向圖模型或貝葉斯網;另一類是使用無向圖表示變數間的相關關係,稱為無向圖模型或馬爾科夫網。
隱馬爾科夫模型(簡稱HMM)是結構最簡單的動態貝葉斯網,是一種著名的有向圖模型,主要用於時間序資料建模,在語音識別,自然語言處理,生物資訊,模式識別中有著廣泛的應用,雖說隨著RNN和LSTM的崛起,HMM的地位有所下降,但很多時候依然是處理序列問題的好用的演算法。
1、隱馬爾科夫模型
隱馬爾科夫模型的圖結構如下
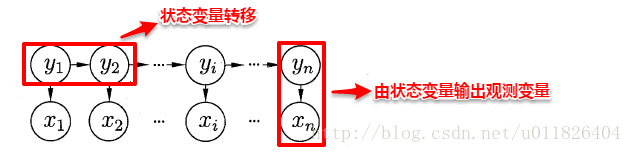
從上圖中主要有兩個資訊:一是觀測變數xi 僅僅與與之對應的狀態變數yi 有關;二是當前的狀態變數yi 僅僅與它的前一個狀態變數yi-1 有關。
隱馬爾科夫模型是由初始概率分佈,狀態轉移概率分佈,以及觀測概率分佈確定的。設Q是所有可能的狀態的集合,V是所有可能的觀測的集合(注意:這裡的狀態集合和觀測集合中的個數和序列的長度T是不一樣的,每個時間端的狀態和觀測值都是依照概率生成的,也就意味著在一個序列裡面會存在狀態和觀測值相同的情況)。具體集合表示式如下,其中N是可能的狀態數,M是可能的觀測數:
![]()
假設此時存在一個長度為T的序列,I為其狀態序列,O為其觀測序列(在HMM模型中每個序列都會包含狀態序列和觀測序列),序列的表示式如下:
![]()
在這裡我們引入三組引數來描述我們的模型:
狀態轉移概率矩陣,,狀態轉移概率矩陣A的表示式如下(矩陣的維度和狀態集合的個數是一樣的)
![]()
其中aij 描述的是在t 時刻從狀態qi 轉移到t+1 時刻的狀態qj 的概率,其條件概率表示式如下
![]()
觀測概率矩陣,觀測概率矩陣B的表示式如下(矩陣的行數和狀態集合的個數相等,列數和觀測集合的個數相等)
![]()
其中bj(k) 描述的是在t 時刻處於狀態qj 的條件下生成觀測值vk 的概率(在某一時刻下,從狀態輸出觀測值的可能性有k種
![]()
初始狀態概率,初始狀態概率π 的表示式如下(整個模型的入口是從確定狀態i1 開始的,因此需要初始化該值)
![]()
![]()
其中πi 就是在t = 1 時刻處於狀態qi 的概率
給出了上述三個引數之後,隱馬爾科夫模型λ 就可以用它們來表示
![]()
在隱馬爾科夫模型中作出了兩個假設來簡化模型:
1)齊次馬爾科夫性假設,即假設隱藏的馬爾科夫鏈在任意時刻t 的狀態只和前一時刻狀態有關,與其他時刻的狀態無關(而在深度模型中都會假設和前面多個時刻的狀態有關,如LSTM;或者和之前的所有狀態相關,如RNN。事實上很多應用場景中都不止是和前一個狀態相關),這也就簡化了模型的複雜度,因此我們可以獲得如下的表示式
![]()
2)觀測獨立性假設,即假設任意時刻的觀測只依賴於該時刻的馬爾科夫鏈的狀態,與其他觀測和狀態無關,因此可以獲得如下表達式
![]()
結合上面兩個假設,我們可以將我們的模型中所有變數的聯合概率分佈給出,這就是所謂的 “馬爾科夫鏈”
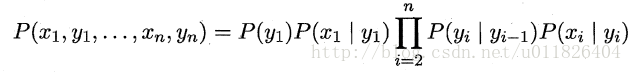
當確定了模型的三個引數後,我們可以按照如下規則生成觀測值序列
輸入的是HMM的模型λ=(A, B, π),觀測序列的長度T
輸出是觀測序列O={o1, o2, ... oT}
生成的過程如下:
1)根據初始狀態概率分佈π,生成隱藏狀態i1
2) 令 t = 1
3)按照隱藏狀態it 的觀測狀態分佈生成觀察狀態ot
4)按照隱藏狀態it 的狀態轉移概率分佈產生隱藏狀態it+1
5)令t = t + 1;如果t < T,則轉至第3 步,否則終止。所有的ot 一起形成觀測序列O={o1, o2, ...oT}
隱馬爾科夫模型的三個基本問題
1) 評估觀察序列概率。即給定模型λ = (A, B, π)和觀測序列O={o1, o2,... oT},計算在模型λ下觀測序列O出現的概率P(O|λ)。這個問題的求解需要用到基於動態規劃的前向後向演算法。
2)模型引數學習問題。即給定觀測序列O={o1, o2,... oT},估計模型λ=(A, B π)的引數,使該模型下觀測序列的條件概率P(O|λ)最大。這個問題的求解需要用到基於EM演算法的鮑姆-韋爾奇演算法。
3)預測問題,也稱為解碼問題。即給定模型λ=(A, B, π)和觀測序列O={o1, o2,... oT},求給定觀測序列條件下,最可能出現的對應的狀態序列,這個問題的求解需要用到基於動態規劃的維特比演算法。
2、前向後向演算法
首先來回顧我們前面提出的隱馬爾科夫模型的三個基本問題中的第一個問題 — 評估觀察序列概率。即給定模型λ = (A, B, π)和觀測序列O={o1, o2,... oT},計算在模型λ下觀測序列O出現的概率P(O|λ)。在知道模型引數和觀測序列的情況下,我們只需要列出所有可能的狀態序列,然後求每個狀態序列下的得到觀察序列O的概率,再將這些概率相加起來就是我們最終要求的概率。然而類似這種窮舉法的時間複雜度是非常高的,假定狀態集Q的個數是N,序列長度是T,則可以列舉出的狀態序列的個數為NT,時間複雜度就是O(TNT)。
我們來看下這種窮舉法的具體數學過程,先列舉出所有可能的狀態序列,每個狀態序列發生的概率表示式如下
![]()
對於固定的狀態序列,觀測序列O的概率表示式如下
![]()
對所有可能的狀態序列和觀測序列的聯合概率求和,就得到我們問題的解,具體表達式如下
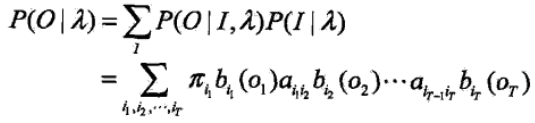
由於上述方法的時間複雜度過高,因此在這裡我們引入前向後向演算法 — 一種動態規劃演算法。首先介紹前向演算法,我們引入前向概率的概念,其表示式為
![]()
αt(i) 表示在t 時刻,觀測序列為o1,o2,...,ot,狀態為qi 的概率。假設序列的長度為T,則我們要計算的觀測序列的概率為
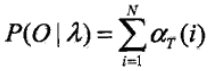
這個演算法的核心是採用遞迴的形式,凡是遞迴的形式都可以用歸納法來描述,現在我們來歸納我們的結果
當t = 1,此時的子序列長度為1:
P(o1|λ) = π1b1(o1) + π2b2(o1) + ...... + πNbN(o1),在這裡 bi(o1) 表示從狀態qi 輸出o1 的概率
= α1(1) + α1(2) + ...... + α1(N)
當t = 2,此時的子序列長度為2:
P(o1o2|λ) = P(o1o2, i2 = q1|λ) + P(o1o2, i2 = q2|λ) + ...... + P(o1o2, i2 = qN|λ) ,注意:這裡變化的只有狀態值
在這裡P(o1o2, i2 = q1|λ) = α1(1) a11 b1(o2) + α1(2) a21 b1(o2) + ...... + α1(N) aN1 b1(o2) = α2(1),注意:這裡變化的是t = 1 時刻的狀態值,因為當前的結果是序列是t = 1 和t = 2時刻的聯合序列,因此依賴與t = 1時刻的輸入值,而在這裡的α1(1) 是在之前已經計算好的,因此可以較少當前的計算量(這是一種動態規劃思想,先求解子問題,然後記住子問題的結果去一步一步的求解至整個問題)
結合上面兩個式子 可以將 P(o1o2|λ) = α2(1) + α2(2) + ...... + α2(N)
依次遞迴下去,當t = t + 1時,式子可以表示為
P(o1o2.....ot+1|λ) = αt+1(1) + αt+1(2) + ...... + αt+1(N)
其中αt+1(i) = αt(1) a1i bi(ot+1) + αt(2) a2i bi(ot+1) + ...... + αt(N) aNi bi(ot+1)
這就是我們整個前向演算法的過程,引入了前向概率,每個子序列的概率都可以用當前時刻的前向概率來表示,儲存當前的前向概率,作為計算下一時刻前向概率的輸入值(在這裡可以極大的減少計算時間複雜度),利用前向演算法計算的時間複雜度是O(N2T)。
前向演算法具體的流程如下:
1)求得初值
![]()
2)遞迴,當t = t + 1時刻
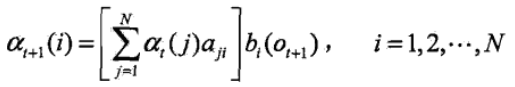
3)t = T 時刻時,終止遞迴
![]()
後向演算法,後向演算法是從後往前推,這裡和前向演算法正好相反,但核心思想是一樣的,我們首先定義後向概率,其表示式如下
![]()
描述的是在時刻t 狀態為qi 的條件下,從t+1 到T 的部分觀測序列的概率,具體歸納過程不再贅述,演算法具體流程如下
1)求得初值
![]()
2)遞迴,在t 時刻時

3)t = 1時,終止遞迴
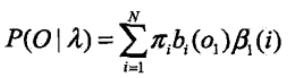
在HMM模型中可以利用前向概率和後向概率得到關於單個狀態和兩個狀態的概率公式:
1)給定模型λ和觀測序列O,在t 時刻的狀態qi 的概率可以表達為
![]()
引入前向、後向概率,表示式可以表示為

![]() (對於該表示式事實上也可以擴充套件到前後組合演算法去求觀測序列的概率上,利用前向演算法從t = 1開始,後向演算法從t = T開始)
(對於該表示式事實上也可以擴充套件到前後組合演算法去求觀測序列的概率上,利用前向演算法從t = 1開始,後向演算法從t = T開始)
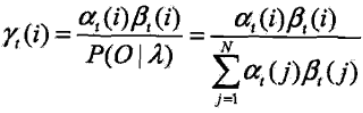
2)給定模型λ和觀測序列O,在t 時刻的狀態qi 且t+1 時刻的狀態為qj 的概率可以表達為
![]()
引入前向概率和後向概率
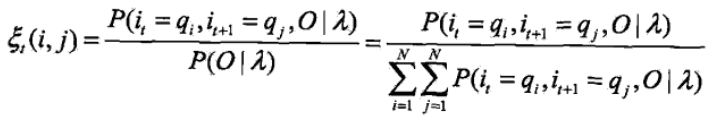
在這裡
![]()

結合上面的兩種概率,可以得到一些有用的期望:
1)在觀測序列O下狀態i出現的期望值
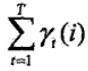
2)在觀測序列O下由狀態i轉移的期望值
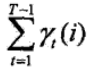
3)在觀測序列O下由狀態i 轉移到狀態j 的期望值
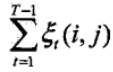
3、鮑姆-韋爾奇演算法
假定給出的訓練資料是已經標記好了狀態序列的資料,訓練資料是包含S個長度相等的觀測序列和對應的狀態序列{(O1, I1), (O2, I2), (OS, IS)},那麼可以直接估計隱馬爾科夫模型的引數,具體估計如下:
1)狀態轉移概率αij 的估計
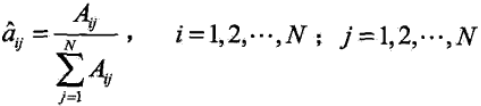
Aij 表示樣本中時刻t 處於狀態i,時刻t+1 處於狀態j 的頻數(這種狀態轉移的樣本數除以總的樣本數)
2)觀測概率bj(k) 的估計,Bjk的理解和上面一樣
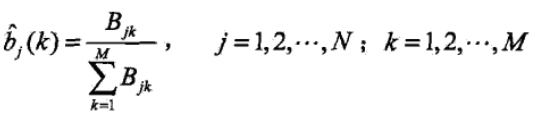
3)初始狀態概率πi 的估計為S個樣本中初始狀態為qi 的概率
上面這種求解方式是在給定了狀態序列的情況下生效的,然而在顯示中觀測序列容易獲得,但標定狀態序列卻並非易事,因此在這裡求解模型引數的時候我們採用無監督學習來求解。假定只知道觀測序列的前提下,利用極大似然估計來求解引數,然而此時含有隱變數狀態序列Q,自然而然就想到了EM演算法(基本都是用於無監督學習中)。具體演算法推導有點複雜,直接給出演算法執行流程:
輸入:觀測資料O = (o1, o2, ..., oT)
輸出:隱馬爾科夫模型引數
1)初始化模型引數
![]()
2)迭代求解
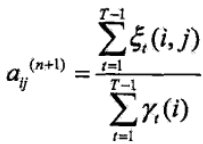
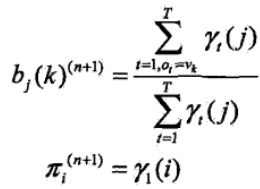
3)迭代終止,模型引數收斂,得到模型引數
![]()
4、維特比演算法
維特比演算法是一種預測演算法,在給定了模型引數λ和觀測序列O的前提下去預測最可能出現的狀態序列。關於隱馬爾科夫模型預測的演算法除了維特比演算法之外,還有一種近似演算法。
近似演算法:近似演算法的核心思想是在每個時刻t選擇在該時刻最有可能出現的狀態it*,從而得到一個近似狀態序列。這種演算法的優點是演算法簡單易理解,缺點是每次都是求解區域性最優(貪心原則),不能保證全域性最優。具體演算法流程如下:
給定模型λ和觀測序列O,在t 時刻的狀態qi 的概率為(在前向後向演算法中有推導):
在每一時刻t 最有可能的狀態it* 是
![]()
這樣就可以得到近似的狀態序列
![]()
維特比演算法和前向後向演算法一樣,也是利用動態規劃來解隱馬爾科夫的預測問題。在前向後向演算法中是對t 時刻轉移到t+1 時刻的所有可能的狀態相加,因為是求邊緣概率 P(O|π);而在維特比演算法中是對t 時刻轉移到t+1 時刻的狀態求最大概率,即求最大的P(O, S|π)(注意:在這裡求t 時刻的最大值也是和t - 1的時刻相關聯的。無關的化只是貪心法)。
首先定義兩個變數δ和Ψ。定義在時刻t 狀態為i 的所有單個路徑中概率最大值(這裡事實上就是前向演算法中的前向概率的最大值)
![]()
由定義可得變數δ的遞推公式
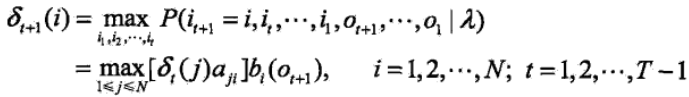
定義在時刻t 狀態為i 的所有單個路徑中概率最大的路徑的第i -1 個節點(在這裡和前一時刻關聯起來)
![]()
維特比演算法的具體過程如下:
1)初始化

2)遞迴
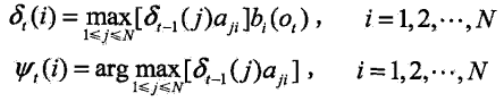
3)終止
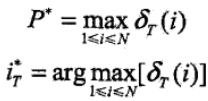
4)最優路徑回溯,求得最優路徑
![]()
既然是遞迴的形式,我們用歸納的方法展開去理解演算法的整個過程
當 t = 1時,此時需要考慮的子序列只有一個觀測值
P(i1 = qi,o1 | λ) = πibi(o1) = α1(i) = δ1(i) ,初始化時和我們的前向概率是一樣的,但之後的有所不一樣
維特比演算法:P(o1 | λ) = max(δ1(i)) 和前向演算法不同的第一個地方
前向演算法:P(o1|λ) = α1(1) + α1(2) + ...... + α1(N)
當t = 2,此時的子序列長度為2:
前向演算法:α2(i) = α1(1) a1i bi(o2) + α1(2) a2i bi(o2) + ...... + α1(N) aNi bi(o2)
維特比演算法:δ2(i) = max(α1(j) aji ) bi(o2),j = 1, 2..., N,和前向演算法不同的第二個地方,也是維特比演算法的核心
當 t = t + 1時:
前向演算法:P(o1o2.....ot+1|λ) = αt+1(1) + αt+1(2) + ...... + αt+1(N),其中αt+1(i) = αt(1) a1i bi(ot+1) + αt(2) a2i bi(ot+1) + ...... + αt(N) aNi bi(ot+1)
維特比演算法:P(o1o2.....ot+1|λ) = max( δt+1(i) ),其中δt+1(i) = max( δt+1(j) aji ) bi(ot+1)
然而維特比演算法不是求概率,而上述的過程最終的結果只是獲得了最大概率,但是最大概率下的狀態序列就是我們要獲得的序列。當獲得最大概率後我們可以獲得當前的狀態,也就是iT(根據最後一步max時選擇的狀態來確定),然後從該節點一步一步的回溯到t = 1時刻,在這個回溯過程中我們需要儲存一個能讓我們找到之前所選擇的節點的值,這就是我們的變數ψ的作用,我們來理解下
![]()
在ψt(i) 中有兩個變數,i 和j,j 是我們要計算出的當前狀態,但這裡還有一個變數i,而i 就是t +1 時刻的狀態,確定了i 的狀態,再回過頭來就很好確定j 的值(這裡的i 的值是在我們找到了最大概率的狀態序列的T時刻的狀態之後回溯的值,只有這樣確定的i 的值猜能確保我們的狀態序列是全域性最優的)。
引自:
http://www.cnblogs.com/jiangxinyang/p/9279711.html