
快取失效及解決方案
這幾天在網易雲課堂上看到幾個關於Java開發比較好的視訊,推薦給大家
Java高階開發工程師公開課
這篇文章也是對其中一門課程的個人總結。
何謂快取失效
對於一個併發量大的專案,快取是必須的,如果沒有快取,所有的請求將直擊資料庫,資料庫很有可能抗不住,所以建立快取勢在不行。
那麼建立快取後就有可能出現快取失效的問題:
- 大面積的快取key失效
- 熱點key失效
類似12306網站,因為使用者頻繁的查詢車次資訊,假設所有車次資訊都建立對應的快取,那麼如果所有車次建立快取的時間一樣,失效時間也一樣,那麼在快取失效的這一刻,也就意味著所有車次的快取都失效。通常當快取失效的時候我們需要重構快取,這時所有的車次都將面臨重構快取,即出現問題1的場景,此時資料庫就將面臨大規模的訪問。
針對以上這種情況,可以將建立快取的時間進行分佈,使得快取失效時間儘量不同,從而避免大面積的快取失效。
下面討論第二個問題。
春節馬上快到了,搶票回家的時刻也快來臨了。通常我們會事先選擇好一個車次然後瘋狂更新車次資訊,假設此時這般車的快取剛好失效,可以想象會有多大的請求會直懟資料庫。
使用快取
下面是通常的快取使用方法,無非就是先查快取,再查DB,重構快取。
@Service public class TicketService { @Autowired TicketRepository ticketRepository; @Autowired RedisUtil redis; public Integer findTicketByName(String name){ //1.先從快取獲取 String value = redis.get(name); if(value != null){ System.out.println(Thread.currentThread().getId()+"從快取獲取:"+value); return Integer.valueOf(value); } //2.查詢資料庫 Ticket ticket = ticketRepository.findByName(name); System.out.println(Thread.currentThread().getId()+"從資料庫獲取:"+ticket.getTickets()); //3.放入快取 redis.set(name,ticket.getTickets(),120); return 0; } }
接下來我們模擬1000個請求同時訪問這個service
@RunWith(SpringRunner.class) @SpringBootTest public class RedisQpsApplicationTests { //車次 public static final String NAME = "G2386"; //請求數量 public static final Integer THREAD_NUM = 1000; //倒計時 private CountDownLatch countDownLatch = new CountDownLatch(THREAD_NUM); @Autowired private TicketService tocketService; @Autowired private TicketService2 tocketService2; @Autowired private TicketService3 tocketService3; @Test public void contextLoads() { long startTime = System.currentTimeMillis(); System.out.println("開始測試"); Thread[] threads = new Thread[THREAD_NUM]; for(int i=0;i<THREAD_NUM;i++){ threads[i] = new Thread(new Runnable() { @Override public void run() { try { //所有開啟的執行緒在此等待,倒計時結束後統一開始請求,模擬併發量 countDownLatch.await(); //查詢票數 tocketService.findTicketByName(NAME); } catch (InterruptedException e) { e.printStackTrace(); } } }); threads[i].start(); //倒計時 countDownLatch.countDown(); } for(Thread thread:threads){ try { thread.join(); } catch (InterruptedException e) { e.printStackTrace(); } } System.out.println("結束測試===="+(System.currentTimeMillis()-startTime)); } }
經過測試可以很簡單地發現所有的訪問都直接去查詢資料庫而獲得資料
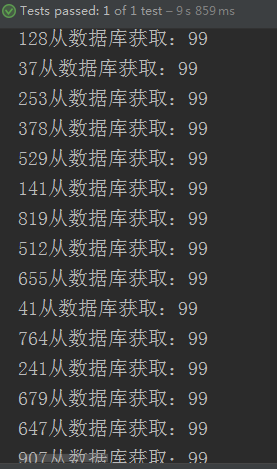
那麼明明我們已經使用了快取為什麼還會出現這種情況呢?只要稍微瞭解多執行緒的知識就不難知道為什麼會出現這個問題。
我們的思路是第一個訪問的人在沒有快取的情況下,去重構快取,那麼剩下的訪問再去查快取。上述的情況就是因為在第一人去查DB的時候,剩下的訪問也去查DB了。
那麼根據我們的思路無非就是想讓剩下的訪問阻塞等待嘛,於是有了我們下面經過改良的方案。
加鎖重構快取
@Service
public class TicketService2 {
@Autowired
TicketRepository ticketRepository;
Lock lock = new ReentrantLock();
@Autowired
RedisUtil redis;
public Integer findTicketByName(String name){
//1.先從快取獲取
String value = redis.get(name);
if(value != null){
System.out.println(Thread.currentThread().getId()+"從快取獲取:"+value);
return Integer.valueOf(value);
}
//第一人獲取鎖,去查DB,剩餘人二次查詢快取
long s = System.currentTimeMillis();
lock.lock();
try {
System.out.println(Thread.currentThread().getId()+"加鎖阻塞時長"+(System.currentTimeMillis()-s));
value = redis.get(name);
if(value != null){
System.out.println(Thread.currentThread().getId()+"從快取獲取:"+value);
return Integer.valueOf(value);
}
//2.查詢資料庫
Ticket ticket = ticketRepository.findByName(name);
System.out.println(Thread.currentThread().getId()+"從資料庫獲取:"+ticket.getTickets());
//3.放入快取
redis.set(name,ticket.getTickets(),120);
}finally {
lock.unlock();
}
return 0;
}
}
通過單元測試可以看到確實符合我們的預期。第一個去重構快取,剩餘的查快取。這裡要注意記得在鎖內對快取進行二次查詢。
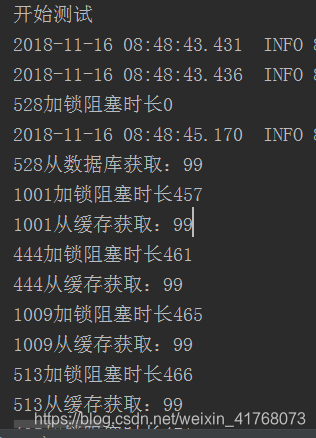
這種解決方案怎麼說呢,有好有壞。
- 優點:簡單通用,使用範圍廣
- 缺點:阻塞訪問,使用者體驗差,鎖粒度粗
關於鎖的粒度:12306的車次是非常多的,假設有兩個車次的快取都失效了,假設使用上述方案,第一個車次的去查DB,第二個車次的也要去查DB重構快取啊,憑什麼我要等你第一個車次的查完,我再去查。這就是鎖粒度粗導致的,一把鎖面對所有車次的查詢,當別車次擁有了鎖,那你只好乖乖等待了。
快取降級
快取降級簡單的理解就是降低預期期望。比如雙十一的時候很多人因為支付不成功而提示的稍後再試,這些都屬於快取降級,快取降級也有好幾種方案,具體要結合實際業務場景,可以返回固定的資訊,返回備份快取的值(並不一定是真實值),返回提示等待…
對鎖的粒度進行優化結合快取降級,對於每一個車次如果已經在重構快取,那麼同車次的訪問進行快取降級,不同車次的訪問則也可以重構快取。大體思路如下
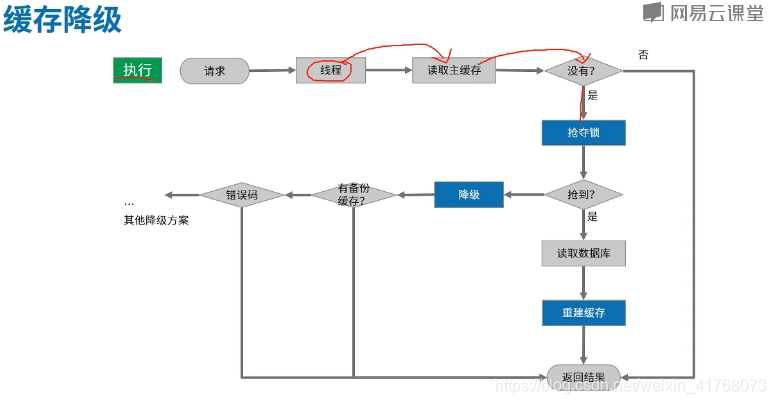
下面使用ConcurrentHashMap對每個車次的鎖進行標記
@Service
public class TicketService3 {
@Autowired
TicketRepository ticketRepository;
//標記該車次是否有人在重構快取
ConcurrentHashMap<String,String> mapLock = new ConcurrentHashMap<>();
@Autowired
RedisUtil redis;
public Integer findTicketByName(String name){
//1.先從快取獲取
String value = redis.get(name);
if(value != null){
System.out.println(Thread.currentThread().getId()+"從快取獲取:"+value);
return Integer.valueOf(value);
}
boolean lock = false;
try {
/* putIfAbsent 如果不存在,新增鍵值,返回null,存在則返回存在的值 */
lock = mapLock.putIfAbsent(name,"true") == null ; //1000個請求,只有一個拿到鎖,剩餘人快取降級
if(lock){ //拿到鎖
//2.查詢資料庫
Ticket ticket = ticketRepository.findByName(name);
System.out.println(Thread.currentThread().getId()+"從資料庫獲取:"+ticket.getTickets());
//3.放入快取
redis.set(name,ticket.getTickets(),120);
//4.有備份快取 雙寫快取 不設時間
}else{
//方案1 返回固定值
System.out.println(Thread.currentThread().getId()+"固定值獲取:0");
return 0;
//方案2 備份快取
//方案3 提示使用者重試
}
}finally {
if(lock){//有鎖才釋放
mapLock.remove(name);//釋放鎖
}
}
return 0;
}
}
詳細程式碼已經見碼雲
總結
快取失效的兩種情況:
1.大面積快取key失效,所有車次查詢都依賴資料庫,可對快取的時間進行隨機分佈
2.熱點key失效,某個key的海量請求直擊資料庫
快取的實現原理:先查快取,再查DB,塞進快取
1.快取失效:快取有有效時間,當有效時間到達,大量併發執行緒會直擊資料庫。
解決方案:1.Lock 第一人查DB,做快取,剩餘人二次查詢快取
優點:簡單有效,適用範圍廣
缺點:阻塞其他執行緒,使用者體驗差
鎖顆粒度大
優化:細粒度鎖實現
2.快取降級:1)做備份快取,不設定事件 2)返回固定值
主備都無資料,一人去查DB,剩餘人返回固定值
主無資料,備有資料,一人查DB,剩餘人查備份
優點:靈活多變
缺點:備份快取資料可能不一致