
高併發熱點快取資料可能出現問題及解決方案
背景
電商場景促銷活動的會場頁由於經常集中在某個時間點進行“秒殺”促銷,這些頁面的QPS(伺服器每秒可以處理的請求量)往往特別高,資料庫通常無法直接支撐如此高QPS的請求,常見的解決方案是讓大部分相同資訊的請求都儘可能地壓在快取(cache)上來緩解資料庫(DB)的壓力,從而儘可能地去滿足高併發訪問的訴求(如圖2-1所示)。
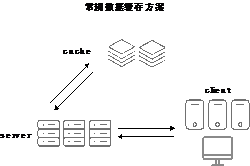
在一次業務促銷過程中,運營給一大批使用者集中推送了一條訊息:10點鐘準時搶購一批遠低於市場價而且數量有限的促銷活動商品。由於確實物美價廉,使用者收到訊息之後10點鐘準時進入手機客戶端的會場頁進行瘋搶。幾分鐘內很多使用者進入會場頁,最終導致頁面異常,伺服器瘋狂報警。報警資訊顯示很多關於快取的異常,由於快取拿不到資料轉而會轉向資料庫去查詢資料,這樣資料庫更加難以支撐,整個業務叢集處於雪崩狀態(如圖2-2所示)。
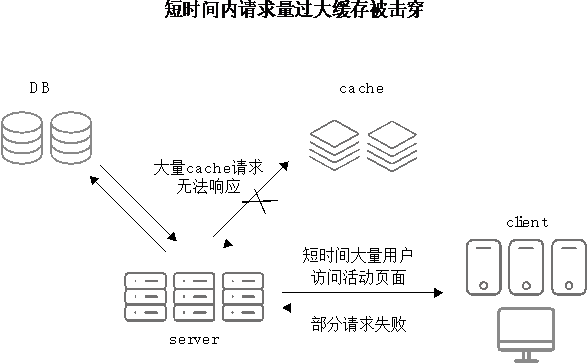
此時快取到底發生了什麼問題?關注哪些方面可以有效地預防快取被擊穿導致雪崩的發生呢?
快取問題分析與解決過程
- 首先檢視快取詳細日誌,發現有很多帶有“CacheOverflow”字樣的日誌,初步懷疑是觸發了快取限流。但是計算了快取的整體能力和當前訪問量情況:快取的機器數×單機能夠承受的QPS > 當前使用者訪問的最大QPS值,此時使用者訪問QPS並沒有超過快取之前的預算,怎麼也會觸發限流呢?
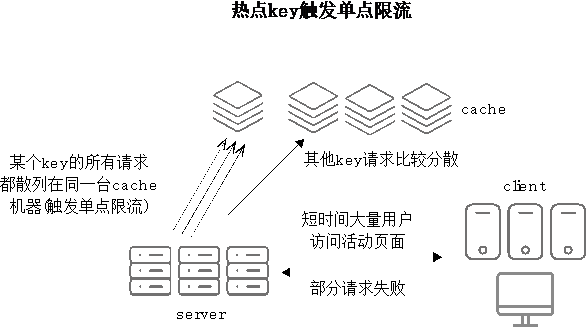
- 進一步分析日誌,發現所有伺服器上限流日誌中快取機器IP貌似都是同一臺,說明大流量並沒有按預想平均分散在不同的快取機器上。回想前面提到的案例實際現象,發現確實有部分資料使用者的訪問請求都會觸發對快取中同一個key(熱點key)進行訪問,使用者訪問QPS有多大,則這個key的併發數就會有多大,而其他快取機器完全沒有分擔任何請求壓力,如圖2-3所示。
- 然後緊急梳理出存在“熱點請求”的key,並快速接入“熱點本地快取”方案,然後迅速在下一場秒殺活動中進一步進行驗證,此時發現之前異常大幅度減少。不過還是有少量“CacheOverflow”字樣異常日誌。熱點key的請求都被“本地快取”攔截掉了,此時發現遠端QPS限流異常已經基本沒有了,這又是什麼原因呢?
圖2-3 熱點key觸發單點限流
仔細檢視快取單臺機器的網路流量監控,發現偶爾有網路流量過大超過單臺快取機器的情況(如圖2-4所示)。圖2-4 網路流量監控
說明快取中有某些key對應的value資料過大,導致儘管QPS不是很高,但是網路流量(QPS×單個value的大小)還是過大,觸發了快取單臺機器的網路流量限流。 - 緊急梳理出存在“大value”的key,發現這些“大value”部分是可以精簡,部分是可以直接放入記憶體不用每次都遠端獲取的,經過一番梳理和優化之後,下次“秒殺”場景終於風平浪靜了。至此問題初步得到解決。

預防“快取被擊穿”總結
- 評估快取是否滿足具體業務場景的請求流量,不是簡單地對預估訪問流量除以單臺快取的最大服務能力。
- 如果使用的快取機制是按key的hash值雜湊到同一臺機器,則必須梳理出當前業務場景中被高併發訪問的那些key,看看這些key的併發訪問量是否會超過單臺機器的服務能力,如果超過則必須採取更多措施進行規避。
- 除了關注key的併發訪問量外,還要關注key對應value的大小,如果key的併發訪問量×value大小 > 單臺快取機器的網路流量限制,則也需要採取更多措施進行資料精簡。
更多思考
- 單個key的請求量不超過單臺快取機器的服務能力,但是如果多個key正好雜湊到同一臺機器,而且這幾個key的流量之和超過單臺機器的服務能力,我們該如何處理呢?
- 單個key的併發訪問量×對應value大小 < 單臺快取機器的網路流量限制,但是如果多個key的併發訪問量×各自對應value大小 >單臺快取機器的網路流量限制,又該如何處理呢?
針對上述兩個問題,首先要做的是做好快取中元素key的訪問監控,一旦發現快取有QPS限流或者網路大小限流時,能夠迅速定位哪些key併發訪問量過大,或者哪些key返回的value大小較大,再結合快取的雜湊演算法,通過一定規則動態修改key值來自動將這些可疑的key平均雜湊到各臺快取機器上去,這樣就可以充分地利用所有快取機器來分攤壓力,保證快取叢集的最大可用能力,從而減少快取被擊穿的風險。
相關推薦
高併發熱點快取資料可能出現問題及解決方案
背景 電商場景促銷活動的會場頁由於經常集中在某個時間點進行“秒殺”促銷,這些頁面的QPS(伺服器每秒可以處理的請求量)往往特別高,資料庫通常無法直接支撐如此高QPS的請求,常見的解決方案是讓大部分相同資訊的請求都儘可能地壓在快取(cache)上來緩解資料庫(DB)的壓力
Web大規模高併發請求和搶購的原理及解決方案
電商的秒殺和搶購,對我們來說,都不是一個陌生的東西。然而,從技術的角度來說,這對於Web系統是一個巨大的考驗。當一個Web系統,在一秒鐘內收到數以萬計甚至更多請求時,系統的優化和穩定至關重要。這次我們會關注秒殺和搶購的技術實現和優化,同時,從技術層面揭開,為什麼我們總是不容易搶到火車票的原因?&nb
網際網路高併發大流量訪問的處理及解決方法
1.硬體升級普通的P4伺服器一般最多能支援每天10萬獨立IP,如果訪問量比這個還要大, 那麼必須首先配置一臺更高效能的專用伺服器才能解決問題 ,否則怎麼優化都不可能徹底解決效能問題。2.負載均衡它是根據某種負載策略把請求分發到叢集中的每一臺伺服器上,讓整個伺服器群來處理網站的
高併發下CURL請求緩慢原因及解決方…
這幾天在做一個對內的服務: 由一個封裝好的類傳送curl請求到接收端,接收端收到鑑權後入到佇列內。 開發完畢後自己使用php單程序能夠達到每秒400左右請求。 但是使用ab、loadrunner,100高併發的時候發現每秒只能處理8個請求。 而併發在10個的時候一切正常 經過測試發現當傳送端和接收端都在同一臺
java:集合框架(併發修改異常產生的原因及解決方案)
A:案例演示 * 需求:我有一個集合,請問,我想判斷裡面有沒有"world"這個元素,如果有,我就新增一個"javaee"元素,請寫程式碼實現。 public class Demo3_List
vue單頁快取存在的問題及解決方案
1.css同名覆蓋,解決方法:父元件加上scoped <style lang="scss" scoped> @import './unbind.scss' </style> 子元件同名樣式加上deep /deep/ .tabs-row { .item
資料庫 資料丟失問題 及解決方案
什麼是資料丟失 兩個執行緒基於同一個查詢結果進行修改,後修改的人會將先修改人的修改覆蓋掉. 讓我們先來看這麼個小案例: 我們給遊戲充值100,支付成功後,銀行會向遊戲伺服器傳送支付成功資訊,有一個訂單支付資訊表(order)和一個賬戶資訊表(account
快取穿透、快取雪崩、快取擊穿的概念及解決方案
一、快取穿透 概念 訪問一個不存在的key,快取不起作用,請求會穿透到DB,流量大時DB會掛掉。 解決方案 採用布隆過濾器,使用一個足夠大的bitmap,用於儲存可能訪問的key,不存在的key直接被過濾; 訪問key未在DB查詢到值,也將空值寫進快取,但
PHP-高併發和大流量的概念和解決方案
.......QPS (每秒查詢率) : 每秒鐘請求或者查詢的數量,在網際網路領域,指每秒響應請求數(指HTTP請求) .......PV(Page View):綜合瀏覽量,即頁面瀏覽量或者點選量,一個訪客在24小時內訪問的頁面數量--注:同一個人瀏覽你的網站的同一頁面,只
一道面試題引出的系列資料庫效能,資料安全問題及解決方案
事件背景: SELECT * FROM girls WHERE age BETWEEN 18 and 24 and boyfriend='no'; 上週在朋友圈看到一張照片,隨手轉發並且提出了一個問題。 面試題一枚可好:請問以下SQL有什麼可能的邏輯問題、語法
RecyclerView使用之——資料重新整理混亂及解決方案
初學Android,首次在專案中運用發生了RecyclerView刷新發生混亂的問題,困擾好久,終於解決,分享如下。 【問題現象】 專案中用RecyclerView做了一個醫生排班列表,用於顯示所有醫生的排班資訊,RecyclerView的一個專案(即一個醫生),可以通過點
資料傾斜原理及解決方案
導讀 相信很多接觸MapReduce的朋友對'資料傾斜'這四個字並不陌生,那麼究竟什麼是資料傾斜?又該怎樣解決這種該死的情況呢? 何為資料傾斜? 在弄清什麼是資料傾斜之前,我想讓大家看看資料分佈的概念: 正常的資料分佈理論上都是傾斜的,就是我們所說的20-80原理
高併發快取處理之——快取穿透的幾種形式及解決方案
快取失效的幾種形式 1 快取穿透 快取穿透是指查詢一個一定不存在的資料,由於快取是不命中時被動寫的,並且出於容錯考慮,如果從儲存層查不到資料則不寫入快取,這將導致這個不存在的資料每次請求都要到儲存層去查詢,失去了快取的意義。在流量大時,可能DB就掛掉了,要是有人利用不存在
PHP高併發與大資料
web資源防盜鏈 盜鏈是什麼? 為什麼要防? 在自己頁面上顯示一些不是自己伺服器的資源(圖片、音訊、視訊、css、js等) 由於別人盜鏈你的資源會加重你的伺服器負擔,所以我們需要防止 可能會影響統計 防盜鏈是什麼? 有哪幾種方式? 防
Redis學習總結(10)——快取雪崩、快取穿透、快取併發、快取預熱、快取演算法的概念及解決思路總結
一、快取雪崩 概念: 可能是因為資料未載入到快取中,或者快取同一時間大面積的失效,從而導致所有請求都去查資料庫,導致資料庫CPU和記憶體負載過高,甚至宕機。 解決思路: 1.1、加鎖計數(即限制併發的數量,可以用semphore)或者起一定數量的佇列來避免快取失效時大
高併發的詳解及解決方案
一、什麼是高併發 高併發(High Concurrency)是網際網路分散式系統架構設計中必須考慮的因素之一,它通常是指,通過設計保證系統能夠同時並行處理很多請求。 高併發相關常用的一些指標有響應時間(Response Time),吞吐量(Throughput),每秒查詢率QPS(Quer
高併發下快取和資料庫一致性問題(更新淘汰快取不得不注意的細節)
快取和資料庫一致性問題本文討論的背景是,cache如memcache,redia等快取來快取資料庫讀取出來的資料,以提高讀效能,如何處理快取裡的資料和資料庫資料的一致性是本文討論的內容:正常的快取步驟是:1查詢快取資料是否存在,2不存在即查詢資料庫,3將資料新增到快取同時返
java面試總結(九)—— 如何處理專案的高併發、大資料
1.HTML靜態化 如果網站的請求量過大,我們可以將頁面靜態化提供訪問來緩解伺服器壓力,能夠緩解伺服器壓力加大以及降低資料庫資料的頻繁交換。適合於某些訪問了過大,但是內容不經常改變的頁面,如首頁、新聞頁等 2.檔案伺服器 顧名思義,檔案伺服器就是將檔案
《連載 | 物聯網框架ServerSuperIO教程》- 17.整合Golden實時資料庫,高併發儲存測點資料。附:3.4 釋出與版本更新說明。
目 錄 17.支援實時資料庫,高併發儲存測點資料... 2 17.1 概述... 2 17.2 ServerSuperIO與實時資料庫對接... 4 17.2.1 繼承動態介面,
如何解決高併發下快取被擊穿的問題
背景: 在某些電商促消活動中需要搞活動,對某些頁面的訪問量(QPS)往往會非常高。如果直接讀資料庫,肯定DB會承受不住。那比較常見的方案就是讓大部分相同資訊的請求都儘可能壓在cache上來緩解DB的壓力,從而儘可能去滿足高併發訪問的需求在一次具體的促銷過程中,當運營同學