
研讀《ROTE: Rollback Protection for Trusted Execution》——分散式系統保護資料的新鮮性
本部落格是對文章《ROTE: Rollback Protection for Trusted Execution》的研讀與解析,為了直奔文章討論的問題筆者增加了副標題“分散式系統保護訊息的新鮮性”。這篇論文發表在2017年第26屆USENIX安全研討會論文集中。論文針對現有SGX回滾防護方案的不足,提出一種分散式系統來保護資料的新鮮性。作者實現了系統原型,並測試出該系統比已有的解決方案有更好的效能。
本部落格基本依照論文的順序,同時為了使之前沒有了解過回滾攻擊、可信執行技術、分散式系統等知識的同學也能比較好的把握文章內容,筆者補充了一些內容,最後解析思路依次回答這些問題來進行(部落格目錄的*號標記):
第一部分 problem statement
*什麼是回滾攻擊?
筆者沒有在比較常用的詞條找到回滾攻擊的定義,但是我們還是可以通過一些例項瞭解它的含義。
首先說下回滾的含義,筆者最初接觸計算機中的回滾這個詞是在學習資料庫的時候,指資料庫中對資料做修改(update,insert,delete)後但未commit之前,使用rollback可以恢復到資料到修改之前的狀態。維基百科對該詞的解釋如下:
In database technologies, a rollback is an operation which returns the database to some previous state.
這個操作,在資料管理中,多是積極作用,用於防止資料庫伺服器崩潰導致資料丟失,或者對資料做出錯誤的修改時,還能恢復到一個乾淨的副本。
但是在計算機系統或網路認證中,資料或訊息一般與版本,時間等因素有關,回滾可能會破壞資料的完整性,造成攻擊。舉個例子:比如軟體或系統被爆出漏洞時,軟體開發商通常通過簽發一個補丁包給客戶端執行升級來解決。假如對這個補丁包只能鑑別其來源而不能檢查是否是最新的補丁包,那麼攻擊者就可以對客戶端執行歷史的補丁包使其回滾到新爆出的漏洞還沒解決的狀態對漏洞進行利用。
回滾攻擊和大家較為熟知的重放攻擊有點像,不同在於重放攻擊攻擊者重放一模一樣的訊息達到目的,而回滾攻擊重放資料來源相同的歷史狀態的訊息達到目的。一種更為相似的攻擊是
A downgrade attack is a form of cryptographic attack on a computer system or communications protocol that makes it abandon a high-quality mode of operation (e.g. an encrypted connection) in favor of an older, lower-quality mode of operation (e.g. cleartext) that is typically provided for backward compatibility with older systems.
因此,我們可以稍微總結出回滾攻擊是修改資料到舊版本或安全性更低版本的攻擊。
*SGX中的回滾攻擊
SGX簡介
SGX的全稱是Software Guard Extensions(英特爾軟體防護擴充套件),是英特爾釋出的一項可信執行技術。其本質是x86架構指令的安全擴充套件,提供一個隔離於作業系統的可信執行環境,稱為enclave。enclave程式執行時,支援SGX的處理器確保除enclave之外的任何程式,包括作業系統,虛擬機器,特權程式碼等都不能訪問enclave記憶體。
enclave程式退出時,SGX提供密封機制,允許enclave將資料加密儲存在外存和執行完整性檢查。用於加密和簽名的金鑰為enclave特有,這樣,enclave程式下次啟動時直接在本地解密恢復資料,而攻擊者僅能在磁碟中獲得enclave資料密文。
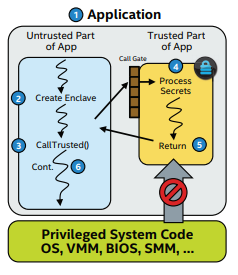
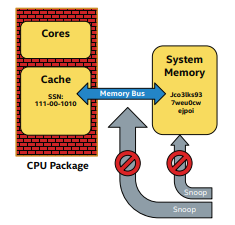
SGX中回滾攻擊的實現
雖然SGX提供了強有力的硬體隔離機制,但是仍有辦法回滾enclave資料到歷史狀態。有兩種情況,一種是通過替換enclave的密封資料為歷史版本的密封資料,另一種是通過例項化兩個enclave程式,一個進行資料修改操作,一個進行資料讀操作來實現。
(1)替換密封資料
我們可以注意到enclave使用SGX提供的密封機制將資料加密儲存到外存並做簽名時,但是enclave無法區分哪個資料是最新密封的,這樣攻擊者可以拿到之前密封的資料來替換當前的密封資料達到回滾攻擊。
(2)同時啟動兩個enclave例項
還有一種情況是,攻擊者可以同時例項化兩個enclave程式,其中一個進行資料修改操作,另一個進行資料讀操作,那麼讀資料的狀態實際上是對修改了的造成了回滾。
*現有的保護方案的不足
通常,消除回滾攻擊的辦法就是先對資料狀態做標識,防護進而轉變成保護這個標識的完整性,即保護資料的新鮮值。目前的保護方案,根據儲存enclave密封資料的新鮮值存放在什麼地方實施保護又分為三類解決方案。
1、儲存在本地非易失性儲存器
(1)SGX counters
SGX counters是英特爾公司官方釋出的,作為SGX的一個可選功能用於防回滾攻擊的方案。它通過引入可信的平臺服務enclave(Platform Service Enclave,PSE)來為本地的其他普通enclave程式提供計數器服務,然後將PSE的記錄的不同enclave的計數器值將儲存在本地非易失性儲存器。英特爾公司雖然提供了這個方法以及相應的技術支援,但是沒有對這個方法效能和安全性做詳細的說明,本文章通過實驗發現 :
- 計數器修改需要80-250ms,讀操作需要60-140ms。並且非易失性儲存器大約在一百萬次寫入後因磨損而無法使用。
- 用來儲存計數器值的非易失性儲存器在處理器包外。
因此該方案不適用於狀態頻繁持續更新的系統, 而且可能會遭受匯流排攻擊和快閃記憶體映象攻擊。
(2)TPM solutions
TPM方案與SGX counter類似,通過在TPM中引入計數器,用NVRAM儲存計數器值。這個方法在效能上也十分受限。
- TPM計數器介面是速率限制的,通常每5秒增加一次,以防止記憶體磨損。寫入NVRAM大約需要100 ms,並且在300K到1.4M寫入後記憶體將無法使用。
因此,該方案不適用與狀態要求快速持續更新的系統。
2、儲存在可信伺服器
Integrity servers
這種方法是通過引入一個可信的伺服器維護enclave的新鮮值。這種方法的缺點是使得該伺服器目標明顯,容易遭受黑客攻擊。而為了消除單點失效攻擊,採用拜占庭共識機制備份伺服器的話,如果使用標準的共識協議,如PBFT,要求多輪通訊,具有高的訊息複雜性,並且為了保護一個節點,至少需要三個副本節點。
3、駐留在enclave記憶體
Architecture modifications
這種方法通過修改SGX體系結構,使得enclave程式退出時,enclave的記憶體不會被OS清除,enclave狀態得以駐留在enclave記憶體中。但是這樣影響OS對enclave程式的排程,而且勢必導致不能執行多個enclave程式。另外通過例項化兩個enclave例項的回滾攻擊還是能實現。
第二部分 Our approach&ROTE system
*本文提出的方法
防護目標
根據對現有防護方案的分析,我們可以總結出現有防護方案存在的不足,而我們提出的防護目標基本就是解決這些問題,即對SGX回滾攻擊的防護應達到enclave狀態更新次數能不受限制,並且提供快速更新,enclave新鮮值不依賴處理器包之外的儲存器儲存,抗擊單點失效攻擊。
分散式的保護模型
有了上述的目標,作者想到既然單個SGX平臺無法有效保護資料新鮮值,但SGX平臺的所有者或所有者可以註冊多個處理器以互相幫助,於是描繪方案的基本輪廓:用協助enclave為本地的一般enclave程式提供計數器服務,而協助enclave的計數器值通過構建一個多協助enclave的分散式系統,向系統廣播這個計數器值,通過分散式系統的同步協議來保證協助enclave計數器值安全。同時這些協議針對回滾保護任務來設計以減少所需的副本和通訊數量。
敵手模型
提出了分散式的保護模型之後,考慮的在這種場景下的敵手模型,攻擊者的能力範圍總結如下:
- 網路通訊控制。假定對手可以阻塞訊息,並通過選擇在任何給定時間到達的節點來劃分網路。
- 控制多個協助enclave同時重啟。
- 啟動多個協助enclave例項。
(因為一開始加入到分散式系統的協助enclave就可能是攻擊者所控制的,因此攻擊者對被控制協助enclave做任何操作都是可能的)
*ROTE系統
系統架構
系統架構如圖所示。每個平臺有執行特定應用程式的enclave,稱為ASE(Application-specific Enclave),ROTE系統用於回滾保護的RE(Rollback Enclave)和配置在ASE的用於ASE請求RE回滾保護的ROTE lib庫。RE還與其他平臺的RE通訊,其他平臺也是同樣的結構。
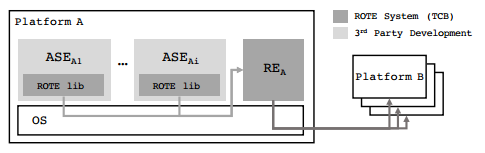
分散式系統的引數
需要提醒的是,這個分散式系統中涉及到一些引數,結構圖沒有體現:
- n 協助平臺總數。
- f 被攻擊的額協助平臺數
- u 在目標平臺更新狀態時訊息不可達或者沒有響應的最大協助平臺數。(這裡忽略了正常情況下的重啟協助平臺數,即認為平臺重啟不是很頻繁,而且要求系統的協助enclave都是響應式的)
那麼我們系統具有這樣的公式n=f+2u+1,也就是說系統管理員選定了可接受的安全級別f和魯棒性,就可以確定所需的協助平臺數量n。或者,給定n個協助平臺,管理員可以設定f和u。為什麼是這樣的公式會在後面的章節解釋。
工作流程
系統中各種enclave的資料結構如下圖所示:

當ASE需要更新其狀態時,它會從ROTE庫呼叫計數器增量函式。一旦RE返回計數器值,ASE就可以安全地更新其狀態,將計數器值儲存到其儲存器中並將所有資料與計數器值一起密封。當ASE需要驗證其狀態的新鮮度時,它可以再次從ROTE庫呼叫一個函式來獲取最新的計數器值,以驗證未密封的密封資料(或其執行時記憶體中的狀態)的新鮮度。
為了方便描述,我們稱發起服務請求的為目標平臺,協助平臺和目標平臺構成一個保護組。RE維護單調計數器(MC),為每次ASE更新增加它,將其分配給在輔助平臺上執行的RE,並將計數器值包括在其自己的密封資料中。當RE需要驗證其自身狀態的新鮮度時,它從分散式保護組中的協助節點獲得最新的計數器值。
協議
下面介紹系統工作涉及到的協議的具體流程。
(1)ASE狀態更新協議

①:ASE向RE請求計數器增
②~③:目標RE對ASE做計數器增操作,簽發自己自增後的MC給系統所有其他RE。
④~⑤:一旦收到簽名MC,每個RE更新自己儲存的組計數器表,然後傳送echo識別符號給目標RE。需要注意的是這個組計數器表儲存在執行記憶體,不會被密封到外存的,以避免整個系統無休止的更新下去。同時,更新MC值是需要兩輪通訊的,因此每個RE也儲存echo在執行記憶體以便後續驗證使用。
⑥:RE收到q=u+f+1=(n+f+1)/2個echo後,有將echo返回echo給相應的傳送者。
⑦:收到目標RE返回的echo,每個RE檢查是否與自己執行記憶體中的一致,如果一致返回ACK識別符號。
⑧:目標RE收到q個ACK,就醬自己的狀態連同MC值密封到本地外存。
⑨:RE返回增加過的ASE計數器值給ASE,ASE可以繼續後續的狀態修改操作,將狀態值連同這個計數器值密封。
(2)RE重啟協議
RE重啟協議是RE重啟之後需執行的操作。它的主要目的是讓RE加入一個存在的保護組,恢復它的計數器值和組計數器表。

①:RE與其他節點建立加密傳輸連線,更新組配置資訊。
②~③:向本地OS請求密封資料,如果有本地密封資料,解封恢復MC。
④~⑤:目標RE向所有其他節點請求它們為自己儲存的MC值。其他節點RE檢查自己的組計數器表,如果找到了這個MC就對該MC簽名回覆,並將自己平臺的計數器表也傳送給目標RE。
⑥:當目標RE收到q個MC回覆後,在其中選擇一個簽名通過的最大MC值,認為這個是它的計數器值,用這個MC值更新組計數器表。同時,目標RE要驗證至少f+1個收到的計數器值都不為0。最後如果解封狀態中有和MC值匹配的,目標RE恢復該狀態。
⑦:目標RE密封更新後的狀態,同時儲存計數器值在執行記憶體。
(3)ASE啟動/讀計數器值協議

①~②:ASE向本地OS請求密封資料,如果有本地密封資料,解封恢復出計數器值。
③:ASE向平臺上的RE請求其為自身儲存的最後一次計數器值。
④~⑤:目標RE為了保證它自身執行記憶體的計數器值是最新的,執行RE重啟協議的④到⑥步,驗證從系統獲得的MC和自己記憶體的MC值,如果相同,將ASE的計數器值返回。
⑥:ASE收到RE返回的計數器值恢復與之匹配的密封狀態。
第三部分 Security analysis&Performance evaluation
通過第二部分對文章提出的方法和系統的介紹,我們可以總結出,ROTE系統中ASE的資料新鮮性依賴本地平臺上的RE的資料新鮮性,而RE的資料新鮮性依賴協助平臺。ASE通過ROTE lib庫和RE通訊,以及SGX的密封機制實現安全儲存,是很容易證明如果RE不被回滾,ASE也不被回滾的。那麼RE依賴分散式的保護組的安全性又怎樣呢?RE重啟協議中,如果目標RE能收到q(q=f+u+1=(n+f+1)/2)個計數器值回覆,那麼認為q其中最大的計數器值是自己的計數器值。RE之間的通訊是安全的,每個RE也有密封機制實現安全儲存。也就是說,除非攻擊者將所有其他協助enclave都回滾,否則不能回滾目標協助enclave。但是為什麼只要求至少能收到分散式保護中的一個極大計數器值就能保證RE的新鮮性,達到了節點備份更少(和拜占庭標準共識協議相比)?這部分重點分析這個問題。
*ROTE系統如何只需要q個協助平臺?
結合分散式情況下敵手的能力模型,敵手可以:
- 網路通訊控制。
- 控制多個協助enclave同時重啟。
- 啟動多個協助enclave例項
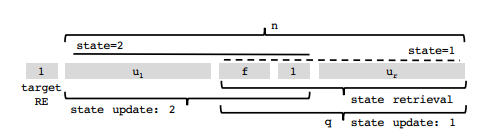
攻擊者可以控制u個節點的網路,導致它們為目標RE儲存的MC值是小於最新MC的。
比如上圖,目標RE第一次向系統廣播計數器值時,攻擊者可以阻止傳送到左側,只允許計數器值1到達組的右側,第二次向系統廣播計數器值時,攻擊者阻止傳送到右側,只允許計數器值2到達組的左側。 最後,目標RE請求計數器值時,攻擊者再次阻塞左側。 這樣組中至少存在u + 1個誠實平臺的計數器值為2,但是收到的q=f+1+u®中只有一個是真實的並且是最大值。當然攻擊者可以阻塞一部分u(l)一部分u®最後返回的,這樣收到的q中不止一個真實值,但仍然是大值。所以目標RE驗證自身的新鮮性時至少需要保護組的一個正確的計數器值。
協助enclave重啟意味執行記憶體丟失,著需要重新和保護組建立會話,同步組計數器表,這樣重啟的協助enclave自身都需要其他協助enclave恢復自身計數器值,是沒辦法幫助目標RE驗證新鮮性的。如果攻擊者同時重啟多個協助enclave會出現什麼情況?ROTE如何應對的?第一種情況,u個節點同時重啟,這樣根據上一段的論述,這樣不足以造成回滾攻擊,對系統執行也不造成影響。第二種情況是有多於u個,但不是整個保護組同時重啟,這樣雖然系統不能正常執行,系統管理員可以通過至少一個沒有重啟的enclave重置整個系統,然而那個沒有重啟的enclave的組計數器表可能不是最新的,有回滾攻擊的風險。最極端的情況是n+1個節點同時重啟了,那麼系統管理員要重新匯入配置資訊來初始化系統。
現在討論ROTE如何保證保護組中q個節點成功儲存目標RE的計數器值。回憶一下ASE更新協議,目標RE需收到q個標誌協助RE收到MC值的echo回覆。但是僅接收到q個echo就能保證嗎?考慮這種情況:首先,攻擊者只允許將更新訊息傳遞到一個協助節點並返回echo,之後,攻擊者重新啟動該節點,並阻止其與目標平臺通訊,這樣重新啟動的RE恢復先前的計數器值,而其他可到達的RE尚未接收到新值。攻擊者對所有協助平臺重複相同的過程。結果,目標節點可以接收到q個echo並接受狀態更新,但是所有輔助節點都具有先前的計數器值,導致回滾攻擊。因此,ASE協議是兩輪通訊的,目標RE收到q個echo之後又將它返回給對於的協助RE,協助RE對比與自己記憶體中的echo,如果一致,傳送ACK識別符號。如果在這過程中協助RE重啟了,目標RE是收不到q個ACK的。因此目標RE收到q個echo和ACK,這才確認保護組中q個節點記錄了它的計數器值。
效能評估
過程:略
結論:通過實驗表明,效能上:(1)ROTE強加的效能開銷很大程度上取決於節點之間的網路連線。(2)如果節點通過低延遲網路連線,ROTE支援需要非常快速狀態更新的應用程式(1-2毫秒), 對於容忍較大延遲的應用(例如,每個狀態更新超過600ms),ROTE可以在地理上較遠的組上執行。與基於本地非易失性儲存器的方法相比:我們的系統提供了更快的回滾保護。 與沒有回滾保護的系統相比,我們的解決方案帶來了適度的開銷。
第四部分 Conclusion&Discussion
總結:本文提出了一種新的英特爾SGX回滾保護方法。其主要想法是將完整性保護實現為多enclave平臺協助的分散式系統。 並構建了一個強大的對手模型。論證系統提供了強大的安全保障,稱之為全有或全無回滾。通過實驗表明,與基於本地非易失性儲存器的解決方案相比,此保護方法可提供明顯更好的效能。