
Kubernetes大叢集怎麼管?基於監控的彈性伸縮方法
導語: 我們通常使用Prometheus來對Kubernetes執行情況進行監控。並根據監控資料來擴容或者縮容。通常的擴/縮容都是根據記憶體或者CPU的使用,但是很多時候我們擴/縮容的依據通常是業務監控指標。如何根據業務監控指標來進行擴/縮容,本文作者給出了很優雅的方式。
Kubernetes自動彈性伸縮
自動彈性伸縮是一種基於資源使用情況自動彈性伸縮工作負載的方法。
Kubernetes的自動彈性伸縮有兩個維度:
-
處理node縮放操作的Cluster Autoscaler
-
自動彈性伸縮部署副本集Pod數量的Horizontal Pod Autoscaler(HPA)。
Cluster Autoscaling和Horizontal Pod Autoscaler(HPA)可用於動態調整計算能力以滿足系統SLA的要求。
雖然群集Cluster Autoscaler高度依賴雲提供程式的底層功能,但HPA可以獨立於IaaS / PaaS提供程式執行。
HPA的演變
Horizontal Pod Autoscaler功能首次在Kubernetes V1.1中引入,自那時起已經發展了很久。 HPA V1版本基於觀察到的CPU利用率和記憶體使用情況來自動伸縮POD。 在Kubernetes 1.6中引入了新的API自定義度量API,使HPA可以訪問任意度量標準。 最終,Kubernetes 1.7引入了聚合層,允許第三方應用程式通過將自己註冊為API附加元件來擴充套件Kubernetes API。
Custom Metrics API和聚合層使得Prometheus等監控系統可以向HPA控制器公開特定於應用的指標。
Horizontal Pod Autoscaler使用控制迴圈來實現功能,它定期查詢Resource Metrics API的核心度量標準,如CPU /記憶體和Custom Metrics API以獲取特定於應用程式的度量標準。

以下是關於為Kubernetes 1.9或更高版本配置HPA v2的指南:
-
安裝提供核心指標的Metrics Server外掛。
-
使用demo應用根據CPU和記憶體使用情況展示pod自動調節。
-
部署Prometheus和一個自定義的API伺服器。 將自定義API伺服器註冊到聚合層。
-
demo應用程式使用自定義指標配置HPA。
在開始之前,您需要安裝Go 1.8或更高版本,並在您的GOPATH克隆k8s-prom-hpa[1]:

1. 設定Metrics server
Kubernetes Metrics Server[2]是一個叢集範圍的資源使用資料聚合器,是Heapster[3]的繼任者。 Metrics Server通過彙集來自kubernetes.summary_api.資料來收集node和POD的CPU和記憶體使用情況。summary API是用於將資料從Kubelet / cAdvisor傳遞到Metrics Server的API(基於記憶體十分高效)。

如果在HPA的第一個版本中,您需要Heapster提供CPU和記憶體指標,但在HPA v2和Kubernetes 1.8中,只有啟用horizontal-pod-autoscaler-use-rest-clients時才需要Metrics Server。 Kubernetes 1.9預設啟用HPA rest 客戶端。 GKE 1.9預裝了Metrics Server。
在kube-system名稱空間中部署Metrics Server:
kubectl create -f ./metrics-server
一分鐘後, metric-server開始報告node和POD的CPU和記憶體使用情況。
檢視node指標:
kubectl get --raw "/apis/metrics.k8s.io/v1beta1/nodes" | jq .
檢視pods指標:
kubectl get --raw "/apis/metrics.k8s.io/v1beta1/pods" | jq .
2.基於CPU和記憶體使用情況的Auto Scaling
我們將使用一個基於Golang的小型Web應用程式來測試Horizontal Pod Autoscaler(HPA)。
將podinfo[4]部署到default名稱空間:
kubectl create -f ./podinfo/podinfo-svc.yaml,./podinfo/podinfo-dep.yaml
使用http://<K8S_PUBLIC_IP>:31198.上的NodePort服務訪問podinfo。
接下來定義一個保持最少兩個副本的HPA,如果CPU平均值超過80%或記憶體超過200Mi,則可擴充套件到10:

建立HPA:
kubectl create -f ./podinfo/podinfo-hpa.yaml
幾秒鐘後,HPA控制器聯絡Metrics Server,然後獲取CPU和記憶體使用情況:

為了增加CPU壓力,使用rakyll / hey執行負載測試:

暫時刪除podinfo。 稍後將在本教程中再次部署它:
kubectl delete -f ./podinfo/podinfo-hpa.yaml,./podinfo/podinfo-dep.yaml,./podinfo/podinfo-svc.yaml
3.設定自定義Metrics Server
為了根據自定義指標進行縮放,您需要兩個元件。 一個從您的應用程式收集指標並將它們儲存在Prometheus[5]時間序列資料庫中。 第二個元件使用collect, k8s-prometheus介面卡[6]提供的度量標準擴充套件Kubernetes自定義指標API。

您將在專用名稱空間中部署Prometheus和介面卡。
建立monitoring名稱空間:
kubectl create -f ./namespaces.yaml
在monitoring名稱空間中部署Prometheus v2:
kubectl create -f ./prometheus
生成Prometheus介面卡所需的TLS證書:
make certs
部署Prometheus自定義指標API介面卡:
kubectl create -f ./custom-metrics-api
列出Prometheus提供的自定義指標:
kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1" | jq .
獲取monitoring名稱空間中所有POD的FS使用情況:
kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1/namespaces/monitoring/pods/*/fs_usage_bytes" | jq .
4.基於自定義指標的Auto Scaling
在default名稱空間中建立podinfoNodePort服務並部署:
kubectl create -f ./podinfo/podinfo-svc.yaml,./podinfo/podinfo-dep.yaml
podinfo應用程式公開名為http_requests_total的自定義指標。 Prometheus介面卡移除_total字尾並將度量標記為計數器度量。
從自定義指標API獲取每秒的總請求數:

m代表milli-units,例如, 901m 意味著901 milli-requests (就是大約0.9個請求)。
建立一個HPA,如果請求數量超過每秒10個,將增加podinfo:
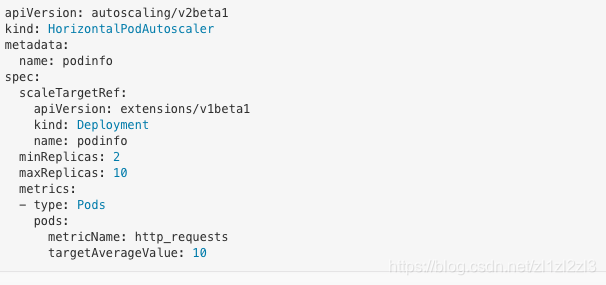
在default名稱空間中部署podinfoHPA:
kubectl create -f ./podinfo/podinfo-hpa-custom.yaml
幾秒鐘後,HPA從度量API獲取http_requests值:

以每秒25個請求的速度為podinfo服務加壓:

幾分鐘後,HPA開始增加POD數量:

按照目前每秒的請求速度,部署將永遠不會達到10個POD的最大值。 三個副本足以使每個POD的RPS保持在10以下。
負載測試完成後,HPA會將部署縮減為其初始副本數量:

您可能已經注意到自動調節器不會立即響應峰值。 預設情況下,指標同步每30秒一次。 如果在最近3-5分鐘內沒有重新縮放,才能進行擴容/縮容。這確保了HP以防止衝突決策快速執行,併為Cluster Autoscaler提供了時間。
結論
並非所有系統都可以通過單獨依靠CPU /記憶體使用量度來滿足其SLA,但大多數Web和移動後端均需要基於每秒請求數來對任何流量突發進行處理。
對於ETL應用程式,自動彈性伸縮可能由作業佇列長度超過某個閾值引發,等等。
通過使用Prometheus提供的適用於自動彈性伸縮的指標,您可以微調應用程式以更好地處理突發事件並確保高可用性。
參考連結
[1] https://github.com/stefanprodan/k8s-prom-hpa
[2] https://github.com/kubernetes-incubator/metrics-server
[3] https://github.com/kubernetes/heapster
[4] https://github.com/stefanprodan/k8s-podinfo
[5] https://prometheus.io
[6] https://github.com/DirectXMan12/k8s-prometheus-adapter