
DataReader分頁效能測試
參考程式地址:http://www.cnblogs.com/eaglet/archive/2008/10/09/1306806.html
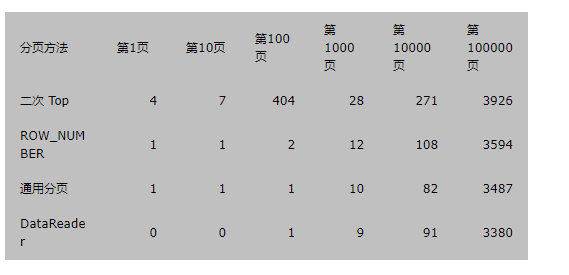
最近遇見程式慢的問題,猜想是分頁導致的,看上面連結評測datareader,
自己在雲上建了個數據庫,測試不在同一臺機器上效果,如果web與資料庫不在同一臺機器上,情況如下
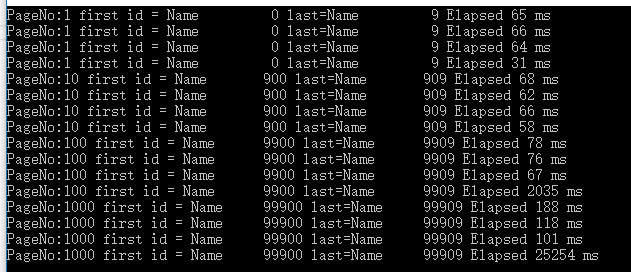
由上圖可見,如果使用dataReader的話,最好在一臺機器上,不在一臺電腦上的話並且網路一般的話,效能影響挺大的。
相關推薦
DataReader分頁效能測試
參考程式地址:http://www.cnblogs.com/eaglet/archive/2008/10/09/1306806.html 最近遇見程式慢的問題,猜想是分頁導致的,看上面連結評測datareader,自己在雲上建了個數據庫,測試不在同一臺機器上效果,如果web與資料庫不在同一臺機器上,情況
分頁效能
現在假如啊,主鍵為id且是自增的,並且是連續的(不存在斷點,),那麼,這個語句 select * from xx limit 20000,10 跟這句 select * from xx where id>20000 limit 10. 取出的是相同的結果,但是前者的效能要遠遠落
oracle 分頁效能
使用者表T_DB_USERS,記錄數60萬 分頁語句一: select t.*,rawtohex(SYS_GUID()) mmm_guid from ( select a.*,rownum rn from T_DB_USERS a) t where rn>10 and rn
SQL大資料量分頁效能優化
目前在進行web api只讀介面的改造,在改造過程中,發現改在後響應時間和之前區別不是很大,通過測試結果顯示在sql的分頁功能處找到原因,並對其進行優化,優化方案如下。測試內容此次執行時間對比採用平臺資金記錄最多的使用者 user_id 36062測試次數未5次 為避免索引
分散式Solr的排序及分頁效能問題
分散式Solr的排序和分頁使用下面的演算法: 1. 傳入查詢條件q,排序sort,開始行數start,返回記錄數rows 2. 修改引數,向各個分片shard傳送新的查詢請求: a)保持q和sort不變 b)修改start=0,rows=原start+原rows
【資料庫效能測試實戰】測試不同分頁儲存過程在10w,100w以及1000w資料量下面的表現
前言 資料庫的效能與每一行程式碼息息相關,所以,每次寫程式碼可以考慮一下在不同級別的資料量下面測試一下效能。 本文參考了: Postgresql生成大量測試資料 以及 準備測試用資料 此次測試我們將分別用10w,100w以及1000w級別的表來測試,下面先建立
整合mybatis分頁插件及通用接口測試出現問題
ping provide form onf ann tsql tro com nbsp 嚴重: Servlet.service() for servlet [springmvc] in context with path [/mavenprj] threw excepti
ElasticSearch最佳入門實踐(三十五)分頁搜尋以及deep paging效能問題深度揭祕
1、如何使用es進行分頁搜尋的語法 size,from GET /_search?size=10 GET /_search?size=10&from=0 GET /_search?size=10&from=20 假設將這6條資料分成3頁,每一頁是2
MySQL分頁查詢效能優化
當需要從資料庫查詢的表有上萬條記錄的時候,一次性查詢所有結果會變得很慢,特別是隨著資料量的增加特別明顯,這時需要使用分頁查詢。對於資料庫分頁查詢,也有很多種方法和優化的點。下面簡單說一下我知道的一些方法。 準備工作 為了對下面列舉的一些優化進行測試,下面針對已有的一張表進行說明。 表名:order
sql效能優化第一篇之分頁資料與count資料一次性獲取
相信大部分人都會遇到:在資料庫的資料量很大時,分頁需要幾秒鐘才會全部完成;包括分頁list的獲取和count的獲取。那我們完全可以將這兩步放到一次sql去執行獲取,減少一半的查詢時間。這裡get到sql_calc_found_rows和SELECT FOUND_ROWS()這兩個知識點。看程式碼
Mysql主鍵 UUID做主鍵,自增主鍵及字串主鍵在插入、查詢,分頁等效能
1.插入方面 UUID做主鍵,其他欄位相同,插入100萬條資料,用了3.5個小時 自增主鍵,其他欄位相同,插入相同的100萬條資料,用了16分鐘 有序增長的字串做主鍵,其他欄位相同,插入相同100萬條資料,用了7分鐘 2.查詢方面 UUID做主鍵,select count() fro
mysql limit 分頁資料丟失問題測試
背景 前幾天看到有說mysql使用 limit 0,10 這種方式分頁會丟失資料,有人質疑說不會,動手驗證一下。 操作步驟 表結構如下: create table `test`.`t_model`( `id` bigint NOT NULL AUTO_INCREMEN
效能優化之分頁查詢
一、背景 大部分開發和DBA同行都對分頁查詢非常非常瞭解,看帖子翻頁需要分頁查詢,搜尋商品也需要分頁查詢。那麼問題來了,遇到上千萬或者上億的資料量怎麼快速的拉取全量,比如大商家拉取每月千萬級別的訂單數量到自己獨立的ISV做財務統計;或者擁有百萬千萬粉絲的公眾大號,給全部粉絲推送訊息的場景。本文講講個人的優化
SSM_CRUD新手練習(7)Spring單元測試分頁請求
好久沒寫這個系列部落格了是因為本人去公司實習去了,公司用的是Spring+SpingMvc+Hibernate現在有時間了不管怎麼樣繼續把這個專案寫完。 因為機器的原因,我的環境變成了IDEA+oracle+1.8+tomc
原創 mysql資料庫千萬級別資料的查詢優化和分頁測試
本文為本人最近利用幾個小時才分析總結出的原創文章,希望大家轉載,但是要註明出處 http://blog.sina.com.cn/s/blog_438308750100im0b.html 有什麼問題:[email protected]於堡艦 我原來的公司是一家網路遊戲公司,其中網
從分頁查詢談使用者體驗與效能表現
●為什麼要做分頁查詢? 大家登陸網站,使用到查詢功能的時候有沒有發現,其實頁面上幾乎都不會給你展示所有內容,而是以分頁的方式進行展示,我們來看看幾個常見的場景: CSDN部落格—— 站長素材—— Printrest—— 包括大家常用的淘寶、知乎、微博、視
Mongodb分頁查詢效能分析
通用的分頁思路 通用的分頁方案是基於row_number的分頁思想,也就是說取第(pageIndexpageSize)到第(pageIndexpageSize + pageSize) db.getCol
mysql 分頁查詢limit中偏移量offset過大導致效能問題
在業務中經常會遇到關於分頁的需求,這就會經常會用到MySQL中的limit offset,rows來分段取出每頁中需要的資料。但是當資料量足夠大的時候,limit條件中的偏移量offset越大就越會導致效能問題,導致查詢耗時增加嚴重。先看一下測試:
MongoDB 分頁查詢的skip方法及效能
說起MongoDB,確實是用完了之後顛覆了我的資料管和程式觀。怎麼說呢?如果用在OO設計的程式裡那真的太棒了,像我這種資料驅動、表驅動思想根深蒂固的人,思路很難一下子跟上MongoDB的節奏。當然並不是呼叫個api,寫幾句query那些思路,而是程式設計思路,業務領域的設計
MongoDB 效能優化之分頁查詢
最常見的分頁採用的是skip+limit這種組合方式,這種方式對付小資料倒也可以,但是對付上幾百上千萬的大資料,只能力不從心。通過如下思路改善,可以大大提高查詢速度:條件查詢+排序+限制返回記錄。邊查詢,邊排序,排序之後,抽取第一次分頁中的最後一條記錄,作為第二次分頁的條件