
機器學習樹模型——決策樹
宣告
在參加大資料競賽的過程中發現用到的演算法都是基於樹模型的,想著將所有的樹模型演算法全部歸納總結一下,形成自己的知識體系,本文是機器學習樹模型系列文章中的第一篇,講解最基礎的決策樹模型,本人不是什麼大牛,文章也是自己對於樹模型的理解,如果有什麼不正確的地方還望指出,歡迎留言討論,共同進步!
正文
對決策樹定義的理解
顧名思義,樹模型因為包含多個分支,像大樹一樣不斷的分散開來所以得名樹模型,常用於分類和迴歸問題,其優點為具有可讀性,分類速度快。在實際中具有很強的實戰性,現在比較火的Xgboost,LightGBM都是基於樹模型建立的。對於一棵樹,我們能夠想到有樹幹,分支以及樹葉,決策樹也由這三部分構成,對於一個現有的資料集而言,我們可以首先把它作為一個整體,進行特徵提取後他們相當於由一個個特徵(設為f1,f2,f3....fn)集合而成,之後我們選擇一種規則,我們利用這種規則來選擇特徵,首先選出來的特徵(假設為fx)就作為這棵樹的樹幹,然後將資料集在特徵為fx時切割成兩個部分,這兩個部分就分別叫做一個分支,之後這兩個分支再按照相同的規則選取最合適的特徵進行切割,直到不能分割為止,最後不能分割的分支就叫做樹葉,一個決策樹分類過程就完成了。所以可以看出,一棵樹的分類過程至少需要包含這幾個部分:特徵選擇,規則的制訂,樹的分割。之後為了防止樹的過擬合,還需要加上剪支的環節。那根據規則的不同我們主要有ID3,C4.5以及CART等演算法,下面將詳細解釋。
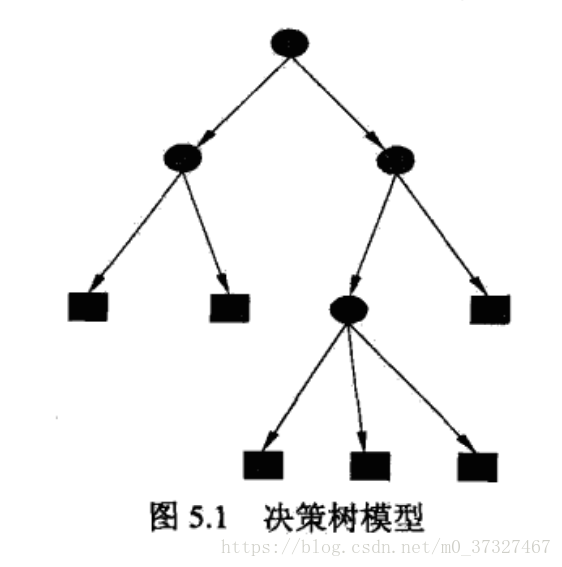
決策樹特徵劃分選擇
前面講到了決策樹的劃分是將特徵按照某種規則進行分割,那具體是哪種規則呢?ID3演算法按照的是資訊增益,C4.5是按照資訊增益比,CART對分類樹用基尼指數、迴歸樹用平方誤差最小化準則對特徵進行分割。下面將一一詳解。
ID3演算法
ID3演算法是利用資訊增益來進行特徵分割的,什麼叫做資訊增益,在李航的《統計學習方法》中有定義:


可能看定義比較抽象,不是很理解,沒關係,在書中還有專門的例子:

如表5.1所示是一個二分類問題,上面給的例子相當於是一個訓練集,有年齡,有工作,有自己房子,信貸情況這四個特徵,我們分別按照資訊增益的公式演算法每個特徵的資訊增益
首先計算經驗熵H(D):這裡因為有15個樣本,所以分母是15,其中類別為是的有9個,作為正樣本,6個否的作為負樣本。
其次將年齡,有工作,有自己的房子,信貸情況分別記為A1,A2,A3,A4,根據公式(5.8)分別計算資訊增益:
A1:年齡有3中情況,所以式子中的n為3,青年,中年,老年各位5個,所以等於5/15, 其中青年5箇中類別為否的有3個,是的有2個,中年5箇中類別為否的有2個,是的有3個,老年5個類別為否的有1個,是的有4個,所以計算的公式為:
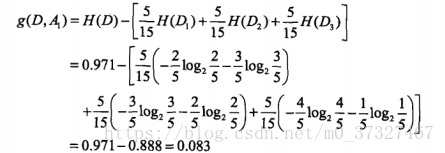
同理A2,A3,A4分別為:

可以發現A3的資訊增益是最大的,所以我們應該首先將A3設為整棵樹的樹幹,A3分為是和否兩類,其中是這一列類別全部為是,不用再進行分類了,否這一列再從年齡(A1),有工作(A2),信貸情況(A3)這三個中按照前面的方法再進行挑選。
如A1,當有房子這一列為否時,可以分為三類,其中青年:4個,這4各種類別為是的有3個,否的有1個;中年:2個,是有0個,否有2個(說明不用分類了,這一部分直接不用算了,等於0),老年:3個,類別為是的有2個,否的有1個,所以將青年和老年的經驗條件熵進行相加,得到結果0.667,最後用經驗熵相減得到年齡的資訊增益為0.918-0.667得到0.251,同理可以得到有工作,信貸情況的資訊增益分別為0.918,0.474,選擇增益最大的特徵作為分支進行分割,不斷重複這樣的過程最後無法分割為止,這樣得到一棵樹。當然這樣得到的樹很容易過擬合,我們必須進行減枝進行處理。
C4.5演算法
C4.5演算法和ID3演算法類似,唯一不同的是規則由資訊增益比取代資訊增益:
