
【機器學習】分類決策樹與迴歸決策樹案例
一、回顧
上面三篇,主要介紹了相關的理論知識,其中構建決策樹的過程可以很好地幫助我們理解決策樹的分裂屬性的選擇。
本篇所有原始碼:Github
二、決策樹的Python實現
假設我們有資料集:
dataSet = [
[1, 1, 'yes'],
[1, 1, 'yes'],
[1, 0, 'no'],
[0, 1, 'no'],
[0, 1, 'no']
]
labels = ['第一個特徵', '第二個特徵' 我們用第二篇中介紹的資訊增益的方法,來構造決策樹,然後再用python程式碼實現:
1. 資訊熵
0 表示’no’,1 表示’yes’,P(0) 表示標籤為 ‘no’ 的概率
2. 資訊增益
由於第一個特徵的資訊增益大於第二個特徵的資訊增益,選擇第一個特徵作為根節點
此時就剩一個特徵了,可以直接畫,使用 多數表決法 決定葉子節點所屬類別;如果還有其他特徵,可以重複以上操作,直到達到決策樹停止條件。
- 使用 多數表決法 構成分類決策樹
- 如果決策規則不是使用多數表決法,而是使用 均方誤差(MSE)或平均絕對誤差(MAE) ,就可以構成迴歸決策樹
3. 畫出決策樹
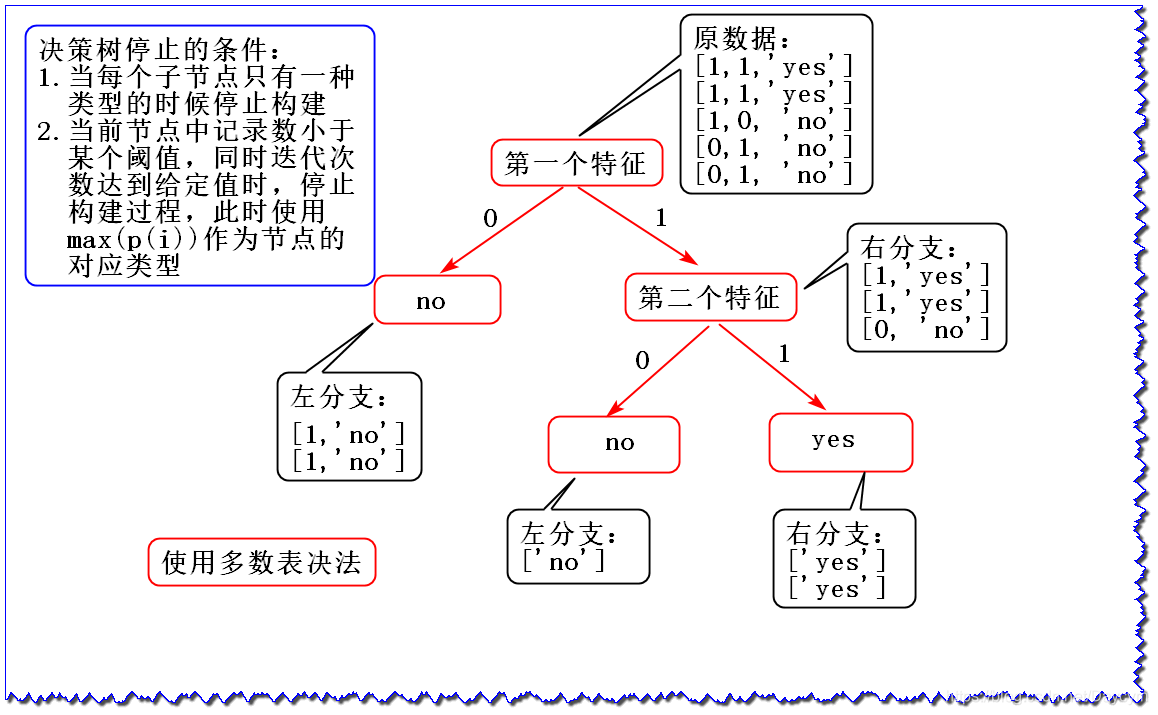
上圖便是最終的決策樹結構
4. 程式碼實現
程式碼可見:01_決策樹的實現.py
執行結果為:
myTree: {'第一個特徵': {0: 'no', 1: {'第二個特徵': {0: 'no', 1: 'yes'}}}}
可見,執行結果和上圖是一樣,首先按第一個特徵作為分裂屬性,然後再按第二個屬性
三、分類決策樹案例
1. 鳶尾花資料分類
本案例主要看看使用決策樹模型的一般步驟。
實現步驟:
- 讀取資料
- 劃分資料(特徵資料與標籤資料分開)
- 資料分割(訓練集和測試集)
- 資料預處理(資料歸一化、特徵選擇、降維)
- 模型構建及訓練
- 模型預測
- 模型評估
- 畫圖
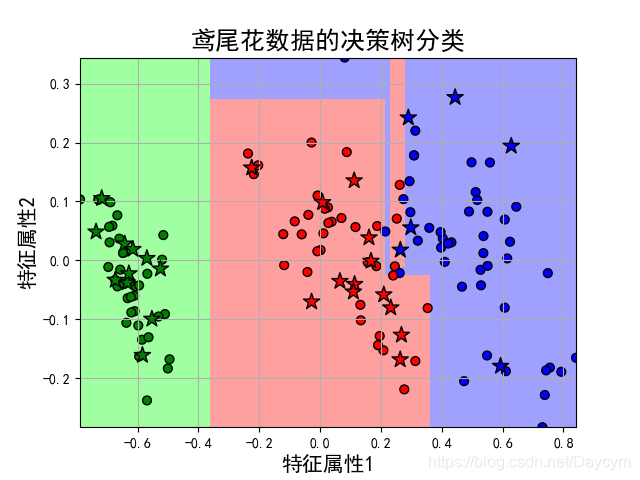
可得到如下結果:
Score: 0.9666666666666667
Classes: [0 1 2]
獲取各個特徵的權重:[0.91754496 0.08245504]
由結果可見,正確率達到了96.7%
本案例通過特徵選擇選擇了3個特徵,當三維不好畫圖;
然後通過降維處理,降為二維,得到以上結果
程式碼可見:02_鳶尾花資料分類.py
2. 鳶尾花資料分類(引數優化)
本案例主要是選擇出最優的模型引數(超引數),以使模型達到最優。
實現步驟:
- 讀取資料
- 劃分資料(特徵資料與標籤資料分開)
- 資料分割(訓練集和測試集):至此和三個案例一樣
- 引數優化(通過管道設定模型及引數)
- 模型構建及訓練
- 模型評估
- 應用以上得到的最優引數檢視效果
最優引數列表: {'decision__criterion': 'gini', 'decision__max_depth': 4, 'pca__n_components': 0.99, 'skb__k': 3}
score值: 0.95
最優模型:Pipeline(memory=None,steps=[('mms', MinMaxScaler(copy=True, feature_range=(0, 1))),
('skb', SelectKBest(k=3, score_func=<function chi2 at 0x0000010FDCA9A0D0>)),
('pca', PCA(copy=True, iterated_power='auto', n_components=0.99, random_state=None, svd_solver='auto', tol=0.0, whiten=False)),
('decision', DecisionTreeClass... min_weight_fraction_leaf=0.0, presort=False, random_state=0, splitter='best'))])
程式碼可見:03_鳶尾花資料分類_引數優化.py
3.鳶尾花資料分類(決策樹深度不同)
本案例主要為了測試決策樹不同深度給模型帶來的效果。
實現步驟:
- 讀取資料
- 劃分資料(特徵資料與標籤資料分開)
- 資料分割(訓練集和測試集):至此和三個案例一樣
- 模型訓練(基於不同深度依次訓練,此處省略了資料預處理),並記錄每個深度下的正確率
- 畫出正確率變化圖
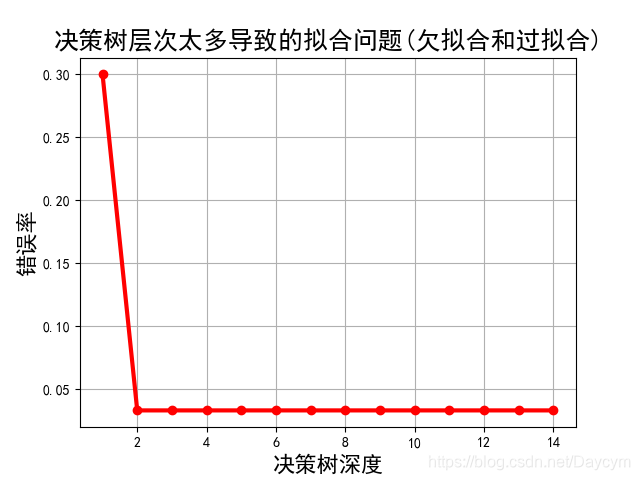
執行結果可能不一樣,大體可以看出:
- 當決策樹深度為1時,錯誤率比較大,此時模型欠擬合;
- 當決策樹深度為2時,錯誤率達到最低;
- 之後,錯誤率基本沒變化,說明此時的模型以及開始過擬合了;
程式碼可見:04_鳶尾花資料分類_決策樹深度不同.py
4.鳶尾花資料分類(特徵屬性比較)
本案例主要是使用2個特徵來訓練模型,並且這兩個特徵為任意組合,最後檢視每個模型的效果。
實現步驟:
- 讀取資料
- 劃分資料(特徵資料與標籤資料分開)
- 資料分割(訓練集和測試集):至此和三個案例一樣
- 特徵比較(每組特徵模型訓練,畫圖)
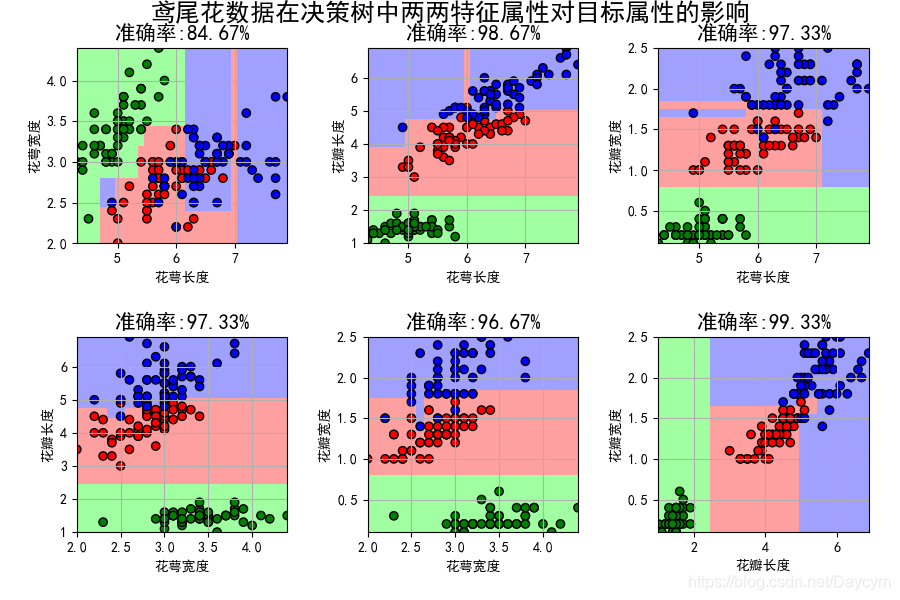
由圖可看出,使用花瓣長度和花瓣寬度特徵,模型正確率達到了99.33%,可以推斷這兩個特徵對於分類決策的效果最好。
也就是這三類花在花瓣長度和花瓣寬度有不同的大小
程式碼可見:05_鳶尾花資料分類_特徵比較.py
四、迴歸決策樹案例
1. 波士頓房屋租賃價格預測
本案例使用迴歸決策樹進行房屋租賃價格預測,並與之前在迴歸演算法中使用線性迴歸、Lasso迴歸、Ridge迴歸進行比較。
實現步驟:
- 讀取資料
- 劃分資料(特徵資料與標籤資料分開)
- 資料分割(訓練集和測試集):這些步驟和前面的案例類似
- 資料處理(資料歸一化)
- 模型構建,並訓練,預測,評估(決策樹、線性迴歸、Lasso迴歸、Ridge迴歸)
- 畫圖
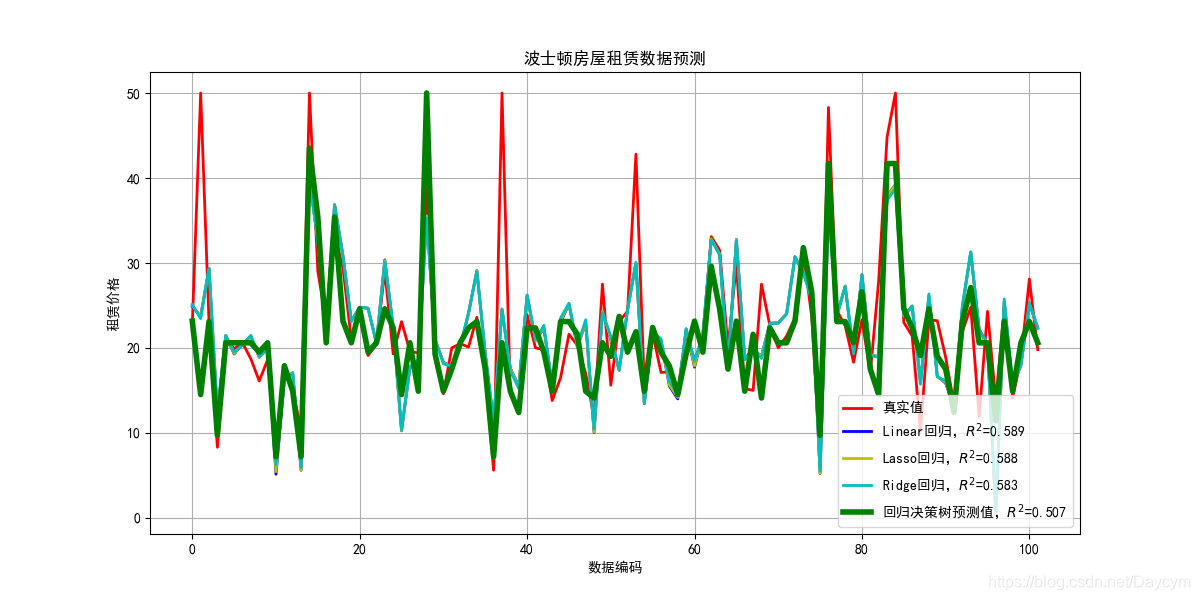
由圖可知,迴歸決策樹的效果其他方法的效果都好
程式碼可見:06_波士頓房屋租賃價格預測.py
2. 波士頓房屋租賃價格預測(引數優化)
本案例是主要是選擇出最佳模型的引數。
實現步驟:
- 讀取資料
- 劃分資料(特徵資料與標籤資料分開)
- 資料分割(訓練集和測試集)
- 引數優化(通過管道設定模型及引數)
- 模型構建及訓練
- 應用以上得到的最優引數檢視效果
執行結果為:
0 score值: 0.4001529052721232 最優引數列表: {'decision__max_depth': 7, 'pca__n_components': 0.75}
1 score值: 0.7569661898236847 最優引數列表: {'decision__max_depth': 4}
2 score值: 0.7565404744169743 最優引數列表: {'decision__max_depth': 4}
正確率: 0.8435980902870441
此程式每次執行得到的最優模型的引數有些不一樣 ,不過最後的正確率都差不多
程式碼可見:07_波士頓房屋租賃價格預測_引數優化.py
3. 波士頓房屋租賃價格預測(決策樹不同深度)
本案例主要為了測試決策樹不同深度給模型帶來的效果。
實現步驟:
- 讀取資料
- 劃分資料(特徵資料與標籤資料分開)
- 資料分割(訓練集和測試集):至此和三個案例一樣
- 模型訓練(基於不同深度依次訓練,此處省略了資料預處理),並記錄每個深度下的正確率
- 畫出正確率變化圖
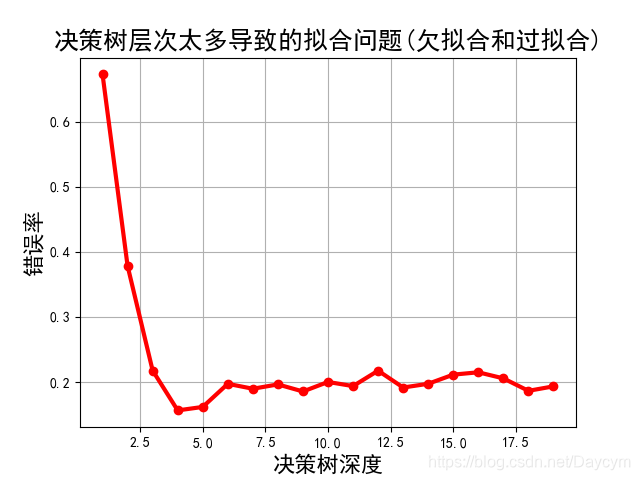
由上圖可知:
- 當深度比較小的時候,錯誤率比較高,模型欠擬合;
- 當深度為4的時候,錯誤率達到了最低,模型最佳;
- 再增加模型深度,錯誤率一直在波動,說明說明模型開始過擬合了
程式碼可見:08_波士頓房屋租賃價格預測_決策樹深度不同.py
五、迴歸決策樹過欠擬合與過擬合
本案例主要是通過隨機資料,看決策樹深度對模型擬合程度的影響。
實現步驟:
- 資料準備(隨機構造資料,此處構造的是sin(x),加上隨機噪聲)
- 模型構造(構造深度不一樣的)
- 模型訓練
- 模型預測(隨機產生測試資料)
- 畫圖展示
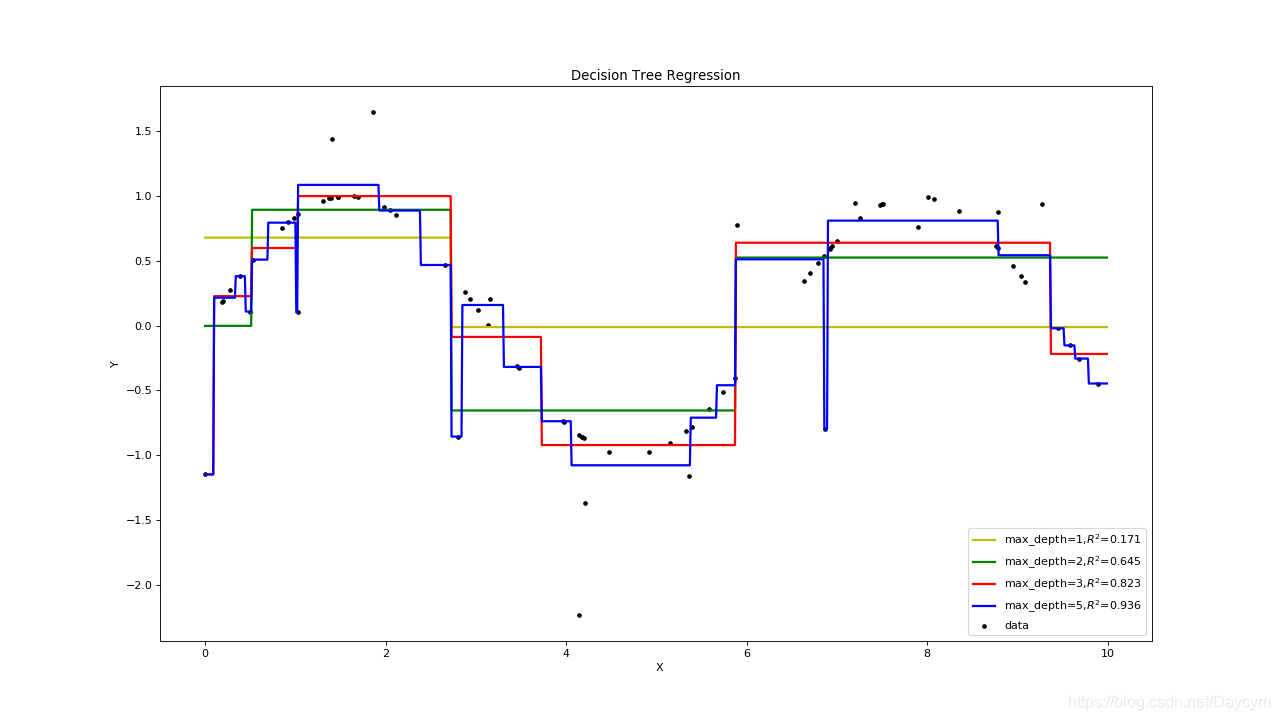
由上圖可知:
- 當深度為1,2的時候,圖中黃色,、綠色的線,明顯出現了欠擬合;
- 當深度為5的時候,模型是和大多數資料吻合,但也把噪聲也擬合的很好,出現了過擬合;
- 當深度為3的時候,模型對資料比較擬合,當然也不一定是最優的。
程式碼可見:09_決策樹欠擬合與過擬合.py
注:
- 如果使用線性迴歸演算法,那麼擬合的線應該是曲線,當用迴歸決策樹來擬合時,會呈一段一段的;
- 因為,迴歸決策樹和分類決策樹的區別就在於決策規則,迴歸決策樹使用的是均方誤差之類的,是根據樣本求得的,所以只會是一些點,不會連成曲線
總結
-
決策樹過擬合一般情況是由於節點太多導致的,剪枝優化對決策樹的正確率影響是比較大的,也是最常用的一種優化方式。可見:
相關推薦
【機器學習】分類決策樹與迴歸決策樹案例
一、回顧 什麼是決策樹,資訊熵 構建決策樹的過程 ID3、C4.5和CRAT演算法 上面三篇,主要介紹了相關的理論知識,其中構建決策樹的過程可以很好地幫助我們理解決策樹的分裂屬性的選擇。 本篇所有原始碼:Github 二
【機器學習】分類決策樹基本介紹+程式碼實現
參考:https://blog.csdn.net/u012351768/article/details/73469813 1.基礎知識 基於特徵對例項進行分類。 優點:複雜度低,輸出結果易於理解,缺失中間值不敏感,可處理不相關特徵資料。 缺點:過度匹配。 適用資料型別:標稱和
【機器學習】Weighted LSSVM原理與Python實現:LSSVM的稀疏化改進
【機器學習】Weighted LSSVM原理與Python實現:LSSVM的稀疏化改進 一、LSSVM 1、LSSVM用於迴歸 2、LSSVM模型的缺點 二、WLSSVM的數學原理 三、WLSSVM的python實現 參
【機器學習】分類器效能指標
1. 錯誤率: e = 錯誤分類個數/總樣本數 2. 正確率: TP:分類正確正例 TN:分類正確負例 FP:分類錯誤正例 FN:分類錯誤負例 precision = 分類正確的正類/(預測結果中被分為正類的個數) = TP/(TP+FP) 3. 召回
【機器學習】分類效能度量指標 : ROC曲線、AUC值、正確率、召回率、敏感度、特異度
在分類任務中,人們總是喜歡基於錯誤率來衡量分類器任務的成功程度。錯誤率指的是在所有測試樣例中錯分的樣例比例。實際上,這樣的度量錯誤掩蓋了樣例如何被分錯的事實。在機器學習中,有一個普遍適用的稱為混淆矩陣(confusion matrix)的工具,它可以幫助人們
【機器學習】貝葉斯線性迴歸模型
假設當前資料為X,迴歸引數為W,結果為B,那麼根據貝葉斯公式,可以得到後驗概率: ,我們的目標是讓後驗概率最大化。其中pD概率是從已知資料中獲取的量,視為常量;pw函式是w分佈的先驗資訊。 令: 求l函式最大化的過程稱為w的極大似然估計(ML),求pie函式最小化的
【機器學習】貝葉斯線性迴歸(最大後驗估計+高斯先驗)
引言 如果要將極大似然估計應用到線性迴歸模型中,模型的複雜度會被兩個因素所控制:基函式的數目(的維數)和樣本的數目。儘管為對數極大似然估計加上一個正則項(或者是引數的先驗分佈),在一定程度上可以限制模型的複雜度,防止過擬合,但基函式的選擇對模型的效能仍然起著決定性的作用。
【機器學習】決策樹與隨機森林(轉)
文章轉自: https://www.cnblogs.com/fionacai/p/5894142.html 首先,在瞭解樹模型之前,自然想到樹模型和線性模型有什麼區別呢?其中最重要的是,樹形模型是一個一個特徵進行處理,之前線性模型是所有特徵給予權重相加得到一個新的值。決
【機器學習】決策樹(基於ID3,C4.5,CART分類迴歸樹演算法)—— python3 實現方案
內含3種演算法的核心部分. 沒有找到很好的測試資料. 但就理清演算法思路來說問題不大 剪枝演算法目前只實現了CART迴歸樹的後剪枝. import numpy as np from collections import Counter from sklearn imp
【機器學習】決策樹(下)CART演算法分類樹、迴歸樹
CART同樣由特徵選擇、樹的生成、剪枝組成。既可以用於迴歸,又可以用於分類。 CART是在給定輸入隨機變數X條件下輸出隨機變數Y的條件概率分佈的學習方法。 CART假設決策樹是二叉樹,內部節點特徵的取值為“是“和“否“,左分支是取值為“是“的分支,右分支是取值為“否“的分支。這樣的決策樹
【機器學習】CART分類決策樹+程式碼實現
1. 基礎知識 CART作為二叉決策樹,既可以分類,也可以迴歸。 分類時:基尼指數最小化。 迴歸時:平方誤差最小化。 資料型別:標值型,連續型。連續型分類時採取“二分法”, 取中間值進行左右子樹的劃分。 2. CART分類樹 特徵A有N個取值,將每個取值作為分界點,將資料
【機器學習】決策樹(三)——生成演算法(ID3、C4.5與CRAT)
回顧 前面我們介紹了決策樹的特徵選擇,以及根據資訊增益構建決策樹。 那麼決策樹的生成又有哪些經典演算法呢?本篇將主要介紹ID3的生成演算法,然後介紹C4.5中的生成演算法。最後簡單介紹CRAT演算法。 ID3演算法 前面我們提到,一般而言,資訊增
【機器學習】演算法原理詳細推導與實現(七):決策樹演算法
# 【機器學習】演算法原理詳細推導與實現(七):決策樹演算法 在之前的文章中,對於介紹的分類演算法有[邏輯迴歸演算法](https://www.cnblogs.com/TTyb/p/10976291.html)和[樸素貝葉斯演算法](https://www.cnblogs.com/TTyb/p/109890
【機器學習--樸素貝葉斯與SVM進行病情分類預測】
貝葉斯定理由英國數學家托馬斯.貝葉斯(Thomas Baves)在1763提出,因此得名貝葉斯定理。貝葉斯定理也稱貝葉斯推理,是關於隨機事件的條件概率的一則定理。 對於兩個事件A和B,事件A發生則B也發生的概率記為P(B|A),事件B發生則A也發生的概率記為P
【機器學習】決策樹剪枝優化及視覺化
前言 \quad\quad 前面,我們介紹了分類決策樹的實現,以及用 sklearn 庫中的 DecisionTre
【機器學習】決策樹演算法(二)— 程式碼實現
#coding=utf8 ‘’’ Created on 2018年11月4日 @author: xiaofengyang 決策樹演算法:ID3演算法 ‘’’ from sklearn.feature_extraction import DictVectorize
【機器學習】決策樹(上)
前言:決策樹是一種基本的分類與迴歸演算法。可以認為是if-then規則的集合,也可以認為是定義在特徵空間與類空間上的條件概率分佈。 學習時,利用訓練資料,根據損失函式最小化原則建立決策樹模型。 學習包括3個步驟:特徵選擇、決策樹的生成、決策樹的修建 一、決策樹模型 更多參照博文
【機器學習】決策樹 總結
具體的細節概念就不提了,這篇blog主要是用來總結一下決策樹的要點和注意事項,以及應用一些決策樹程式碼的。 一、決策樹的優點: • 易於理解和解釋。數可以視覺化。也就是說決策樹屬於白盒模型,如果一個情況被觀察到,使用邏輯判斷容易表示這種規則。相反,如
【機器學習】決策樹(上)——從原理到演算法實現
前言:決策樹(Decision Tree)是一種基本的分類與迴歸方法,本文主要討論分類決策樹。決策樹模型呈樹形結構,在分類問題中,表示基於特徵對例項進行分類的過程。它可以認為是if-then規則的集合,也可以認為是定義在特徵空間與類空間上的條件概率分佈。相比樸素
【機器學習】決策樹演算法的基本原理
參考周志華老師的《機器學習》一書,對決策樹演算法進行總結。 決策樹(Decision Tree)是在已知各種情況發生概率的基礎上,通過構建決策樹來求取淨現值期望值大於等於0的概率,評價專案風險,判斷其可行性的決策分析方法,是直觀運用概率分析的圖解法。