
spark基本概念與執行架構
阿新 • • 發佈:2018-12-02
Apache Spark是一個分散式計算框架,旨在簡化運行於計算機叢集上的並行程式的編寫。
RDD:彈性分散式資料集(Resilient Distributed Dataset)是分散式記憶體的一個抽象概念,提供了一個高度受限的共享記憶體模型。一個RDD包含多個分割槽(Partition)。
DAG:有向無環圖(Directed Acyclic Graph)反應RDD之間的依賴關係。
Executor:執行在工作節點(WorkNode)的一個程序,負責執行Task。
Application:使用者編寫的Spark程式。
Task:執行在Executor上的工作單元。
Job
Stage:是Job的基本排程單位,一個Job會分為多組Task,每組Task被稱為Stage,或者也被稱為TaskSet,代表了一組由關聯的、相互之間沒有shuffle依賴關係的任務組成的任務集。
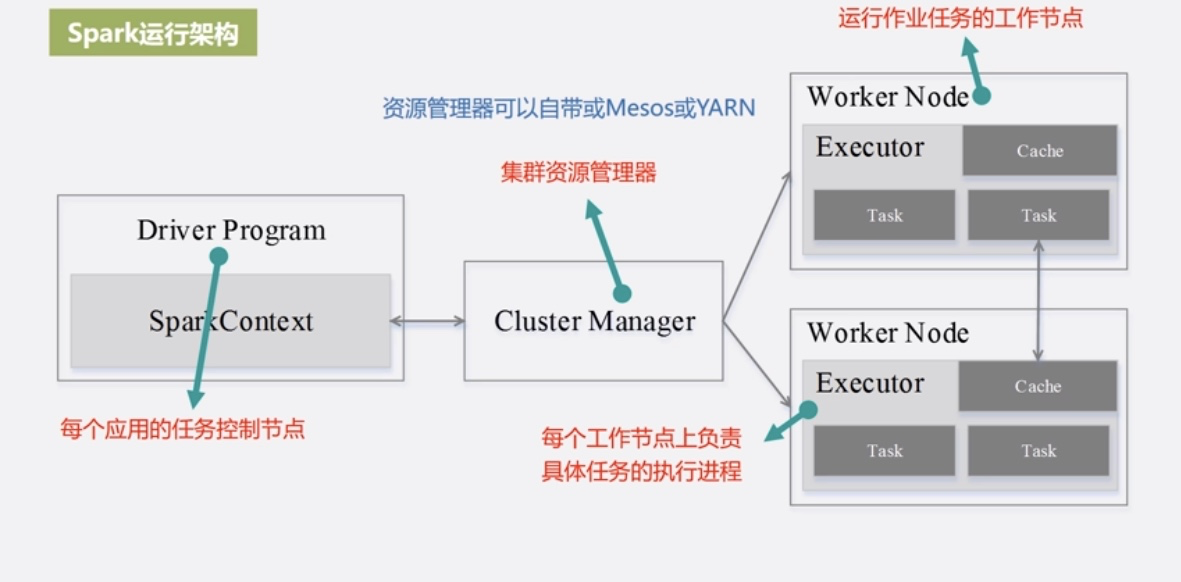

與MapReduce相比的優勢:
- 利用多執行緒來執行具體的任務,減少任務的啟動開銷
- Executor中有一個BlockManager儲存模組,會將記憶體和磁碟共同作為儲存裝置,減少IO開銷
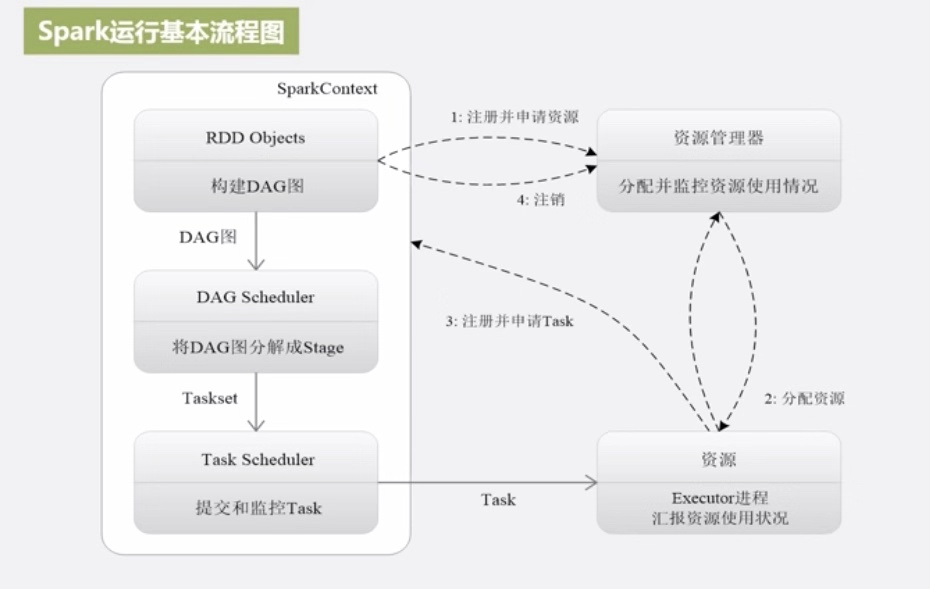
- 為應用構建起基本的執行環境,即由Driver建立一個SparkContext進行資源的申請、任務的分配和監控。
- 資源管理器為Executor分配資源,並Executor啟動程序。
- SparkContext根據RDD的依賴關係構建DAG圖,DAG圖提交給DAGScheduler解析成Stage,然後把一個個TaskSet提交給底層排程器TaskScheduler處理;Executor向SparkContext申請Task,TaskScheduler將Task發放給Executor執行並提供應用程式程式碼。
- Task在Executor上執行把執行結果反饋給TaskSchedulor,然後反饋給DAGScheduler,執行完畢後寫入資料並釋放所有資源。
Spark執行架構特點
- 每個Application都有自己專屬的Executor程序,並且該程序在Application執行期間一直駐留。Executor程序以多執行緒的方式執行Task。
- Spark執行過程與資源管理器無關,只要能夠獲取Executor程序並儲存通訊即可。
- Task採用資料本地性和推測執行等優化機制。
(廈門大學大資料公開課筆記)