
Kaggle入門介紹
這是我去年 4 月份參加完第一次 Kaggle 比賽並拿到前 5% 的成績後寫的總結。本文的英文版當時還被 Kaggle 的官方推特轉發推薦。一年過去了,Kaggle 的賽制和積分體系等都發生了一些變化,不過本文中描述的依然是行之有效的入門 Kaggle 或者其他任何資料科學專案的方法。
本文采用署名 - 非商業性使用 - 禁止演繹 3.0 中國大陸許可協議進行許可。
I. General Approach
在這一節中我會講述一次 Kaggle 比賽的大致流程。
1. Data Exploration
在這一步要做的基本就是 EDA (Exploratory Data Analysis)
通常我們會用 pandas 來載入資料,並做一些簡單的視覺化來理解資料。
1.1 Visualization
通常來說 matplotlib 和 seaborn 提供的繪圖功能就可以滿足需求了。
比較常用的圖表有:
- 檢視目標變數的分佈。當分佈不平衡時,根據評分標準和具體模型的使用不同,可能會嚴重影響效能。
- 對 Numerical Variable,可以用 Box Plot 來直觀地檢視它的分佈。
- 對於座標類資料,可以用 Scatter Plot來檢視它們的分佈趨勢和是否有離群點的存在。
- 對於分類問題,將資料根據 Label 的不同著不同的顏色繪製出來,這對 Feature 的構造很有幫助。
- 繪製變數之間兩兩的分佈和相關度圖表。
這裡有一個在著名的 Iris 資料集上做了一系列視覺化的例子,非常有啟發性。
1.2 Statistical Tests
我們可以對資料進行一些統計上的測試來驗證一些假設的顯著性。雖然大部分情況下靠視覺化就能得到比較明確的結論,但有一些定量結果總是更理想的。不過,在實際資料中經常會遇到非 i.i.d. 的分佈。所以要注意測試型別的的選擇和對顯著性的解釋。
在某些比賽中,由於資料分佈比較奇葩或是噪聲過強,Public LB
2. Data Preprocessing
大部分情況下,在構造 Feature 之前,我們需要對比賽提供的資料集進行一些處理。通常的步驟有:
- 有時資料會分散在幾個不同的檔案中,需要 Join 起來。
- 處理 Missing Data。
- 處理 Outlier。
- 必要時轉換某些 Categorical Variable 的表示方式。
- 有些 Float 變數可能是從未知的 Int 變數轉換得到的,這個過程中發生精度損失會在資料中產生不必要的 Noise,即兩個數值原本是相同的卻在小數點後某一位開始有不同。這對 Model 可能會產生很負面的影響,需要設法去除或者減弱 Noise。
這一部分的處理策略多半依賴於在前一步中探索資料集所得到的結論以及建立的視覺化圖表。在實踐中,我建議使用 iPython Notebook 進行對資料的操作,並熟練掌握常用的 pandas 函式。這樣做的好處是可以隨時得到結果的反饋和進行修改,也方便跟其他人進行交流(在 Data Science 中 Reproducible Results 是很重要的)。
下面給兩個例子。
2.1 Outlier
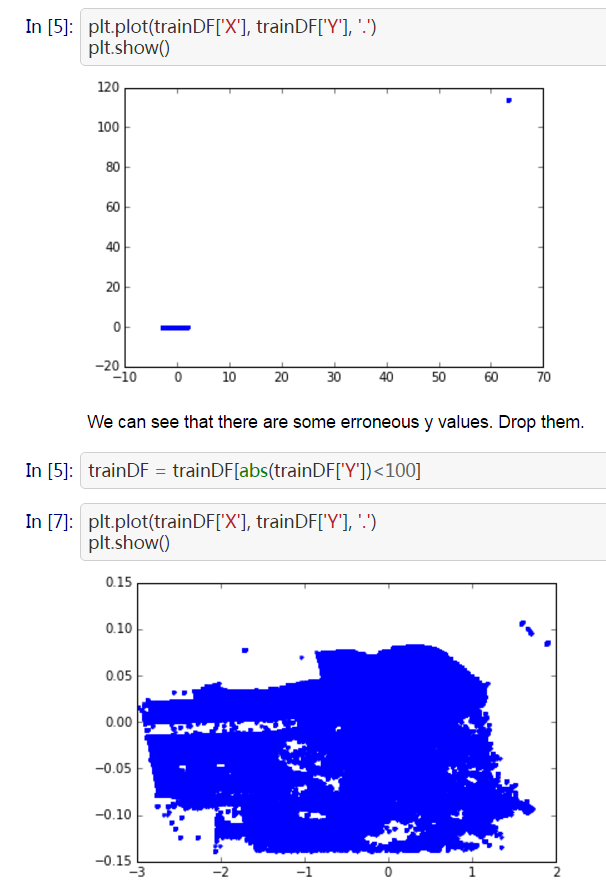
這是經過 Scaling 的座標資料。可以發現右上角存在一些離群點,去除以後分佈比較正常。
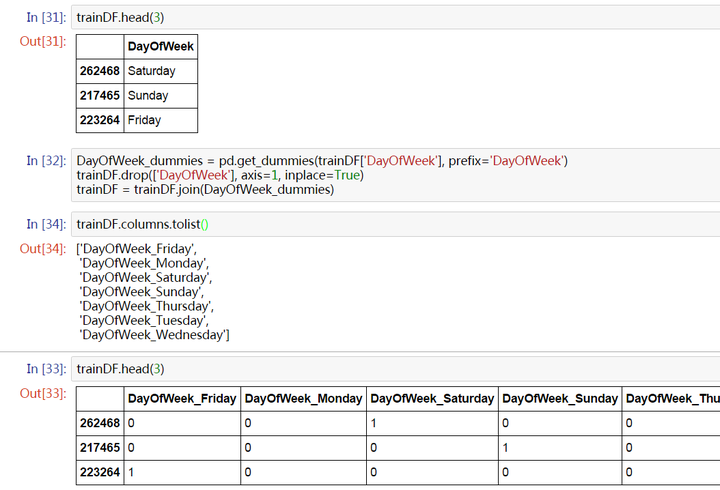
2.2 Dummy Variables
對於 Categorical Variable,常用的做法就是 One-hot encoding。即對這一變數建立一組新的偽變數,對應其所有可能的取值。這些變數中只有這條資料對應的取值為 1,其他都為 0。
如下,將原本有 7 種可能取值的 Weekdays 變數轉換成 7 個 Dummy Variables。
要注意,當變數可能取值的範圍很大(比如一共有成百上千類)時,這種簡單的方法就不太適用了。這時沒有有一個普適的方法,但我會在下一小節描述其中一種。
3. Feature Engineering
有人總結 Kaggle 比賽是 “Feature 為主,調參和 Ensemble 為輔”,我覺得很有道理。Feature Engineering 能做到什麼程度,取決於對資料領域的瞭解程度。比如在資料包含大量文字的比賽中,常用的 NLP 特徵就是必須的。怎麼構造有用的 Feature,是一個不斷學習和提高的過程。
一般來說,當一個變數從直覺上來說對所要完成的目標有幫助,就可以將其作為 Feature。至於它是否有效,最簡單的方式就是通過圖表來直觀感受。比如:
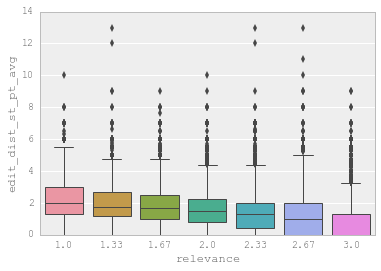
3.1 Feature Selection
總的來說,我們應該生成儘量多的 Feature,相信 Model 能夠挑出最有用的 Feature。但有時先做一遍 Feature Selection 也能帶來一些好處:
- Feature 越少,訓練越快。
- 有些 Feature 之間可能存線上性關係,影響 Model 的效能。
- 通過挑選出最重要的 Feature,可以將它們之間進行各種運算和操作的結果作為新的 Feature,可能帶來意外的提高。
Feature Selection 最實用的方法也就是看 Random Forest 訓練完以後得到的 Feature Importance 了。其他有一些更復雜的演算法在理論上更加 Robust,但是缺乏實用高效的實現,比如這個。從原理上來講,增加 Random Forest 中樹的數量可以在一定程度上加強其對於 Noisy Data 的 Robustness。
看 Feature Importance 對於某些資料經過脫敏處理的比賽尤其重要。這可以免得你浪費大把時間在琢磨一個不重要的變數的意義上。
3.2 Feature Encoding
這裡用一個例子來說明在一些情況下 Raw Feature 可能需要經過一些轉換才能起到比較好的效果。
假設有一個 Categorical Variable 一共有幾萬個取值可能,那麼建立 Dummy Variables 的方法就不可行了。這時一個比較好的方法是根據 Feature Importance 或是這些取值本身在資料中的出現頻率,為最重要(比如說前 95% 的 Importance)那些取值(有很大可能只有幾個或是十幾個)建立 Dummy Variables,而所有其他取值都歸到一個“其他”類裡面。
4 Model Selection
準備好 Feature 以後,就可以開始選用一些常見的模型進行訓練了。Kaggle 上最常用的模型基本都是基於樹的模型:
- Gradient Boosting
- Random Forest
- Extra Randomized Trees
以下模型往往在效能上稍遜一籌,但是很適合作為 Ensemble 的 Base Model。這一點之後再詳細解釋。(當然,在跟影象有關的比賽中神經網路的重要性還是不能小覷的。)
- SVM
- Linear Regression
- Logistic Regression
- Neural Networks
以上這些模型基本都可以通過 sklearn 來使用。
當然,這裡不能不提一下 Xgboost。Gradient Boosting 本身優秀的效能加上 Xgboost 高效的實現,使得它在 Kaggle 上廣為使用。幾乎每場比賽的獲獎者都會用 Xgboost 作為最終 Model 的重要組成部分。在實戰中,我們往往會以 Xgboost 為主來建立我們的模型並且驗證 Feature 的有效性。順帶一提,在 Windows 上安裝 Xgboost 很容易遇到問題,目前已知最簡單、成功率最高的方案可以參考我在這篇帖子中的描述。
4.1 Model Training
在訓練時,我們主要希望通過調整引數來得到一個性能不錯的模型。一個模型往往有很多引數,但其中比較重要的一般不會太多。比如對 sklearn 的 RandomForestClassifier 來說,比較重要的就是隨機森林中樹的數量 n_estimators 以及在訓練每棵樹時最多選擇的特徵數量 max_features。所以我們需要對自己使用的模型有足夠的瞭解,知道每個引數對效能的影響是怎樣的。
通常我們會通過一個叫做 Grid Search 的過程來確定一組最佳的引數。其實這個過程說白了就是根據給定的引數候選對所有的組合進行暴力搜尋。
-
param_grid
=
{
'n_estimators'
:
[
300
,
500
],
'max_features'
:
[
10
,
12
,
14
]}
-
model
=
grid_search
.
GridSearchCV
(
estimator
=
rfr
,
param_grid
=
param_grid
,
n_jobs
=
1
,
cv
=
10
,
verbose
=
20
,
scoring
=
RMSE
)
-
model
.
fit
(
X_train
,
y_train
)
順帶一提,Random Forest 一般在 max_features 設為 Feature 數量的平方根附近得到最佳結果。
這裡要重點講一下 Xgboost 的調參。通常認為對它效能影響較大的引數有:
- eta:每次迭代完成後更新權重時的步長。越小訓練越慢。
- num_round:總共迭代的次數。
- subsample:訓練每棵樹時用來訓練的資料佔全部的比例。用於防止 Overfitting。
- colsample_bytree:訓練每棵樹時用來訓練的特徵的比例,類似 RandomForestClassifier 的 max_features。
- max_depth:每棵樹的最大深度限制。與 Random Forest 不同,Gradient Boosting 如果不對深度加以限制,最終是會 Overfit 的。
- early_stopping_rounds:用於控制在 Out Of Sample 的驗證集上連續多少個迭代的分數都沒有提高後就提前終止訓練。用於防止 Overfitting。
一般的調參步驟是:
- 將訓練資料的一部分劃出來作為驗證集。
- 先將 eta 設得比較高(比如 0.1),num_round 設為 300 ~ 500。
- 用 Grid Search 對其他引數進行搜尋
- 逐步將 eta 降低,找到最佳值。
- 以驗證集為 watchlist,用找到的最佳引數組合重新在訓練集上訓練。注意觀察演算法的輸出,看每次迭代後在驗證集上分數的變化情況,從而得到最佳的 early_stopping_rounds。
-
X_dtrain
,
X_deval
,
y_dtrain
,
y_deval
=
cross_validation
.
train_test_split
(
X_train
,
y_train
,
random_state
=
1026
,
test_size
=
0.3
)
-
dtrain
=
xgb
.
DMatrix
(
X_dtrain
,
y_dtrain
)
-
deval
=
xgb
.
DMatrix
(
X_deval
,
y_deval
)
-
watchlist
=
[(
deval
,
'eval'
)]
-
params
=
{
-
'booster'
:
'gbtree'
,
-
'objective'
:
'reg:linear'
,
-
'subsample'
:
0.8
,
-
'colsample_bytree'
:
0.85
,
-
'eta'
:
0.05
,
-
'max_depth'
:
7
,
-
'seed'
:
2016
,
-
'silent'
:
0
,
-
'eval_metric'
:
'rmse'
-
}
-
clf
=
xgb
.
train
(
params
,
dtrain
,
500
,
watchlist
,
early_stopping_rounds
=
50
)
-
pred
=
clf
.
predict
(
xgb
.
DMatrix
(
df_test
))
最後要提一點,所有具有隨機性的 Model 一般都會有一個 seed 或是 random_state 引數用於控制隨機種子。得到一個好的 Model 後,在記錄引數時務必也記錄下這個值,從而能夠在之後重現 Model。
4.2 Cross Validation
Cross Validation 是非常重要的一個環節。它讓你知道你的 Model 有沒有 Overfit,是不是真的能夠 Generalize 到測試集上。在很多比賽中 Public LB 都會因為這樣那樣的原因而不可靠。當你改進了 Feature 或是 Model 得到了一個更高的 CV 結果,提交之後得到的 LB 結果卻變差了,一般認為這時應該相信 CV 的結果。當然,最理想的情況是多種不同的 CV 方法得到的結果和 LB 同時提高,但這樣的比賽並不是太多。
在資料的分佈比較隨機均衡的情況下,5-Fold CV 一般就足夠了。如果不放心,可以提到 10-Fold。但是 Fold 越多訓練也就會越慢,需要根據實際情況進行取捨。
很多時候簡單的 CV 得到的分數會不大靠譜,Kaggle 上也有很多關於如何做 CV 的討論。比如這個。但總的來說,靠譜的 CV 方法是 Case By Case 的,需要在實際比賽中進行嘗試和學習,這裡就不再(也不能)敘述了。
5. Ensemble Generation
Ensemble Learning 是指將多個不同的 Base Model 組合成一個 Ensemble Model 的方法。它可以同時降低最終模型的 Bias 和 Variance(證明可以參考這篇論文,我最近在研究類似的理論,可能之後會寫新文章詳述),從而在提高分數的同時又降低 Overfitting 的風險。在現在的 Kaggle 比賽中要不用 Ensemble 就拿到獎金幾乎是不可能的。
常見的 Ensemble 方法有這麼幾種:
- Bagging:使用訓練資料的不同隨機子集來訓練每個 Base Model,最後進行每個 Base Model 權重相同的 Vote。也即 Random Forest 的原理。
- Boosting:迭代地訓練 Base Model,每次根據上一個迭代中預測錯誤的情況修改訓練樣本的權重。也即 Gradient Boosting 的原理。比 Bagging 效果好,但更容易 Overfit。
- Blending:用不相交的資料訓練不同的 Base Model,將它們的輸出取(加權)平均。實現簡單,但對訓練資料利用少了。
- Stacking:接下來會詳細介紹。
從理論上講,Ensemble 要成功,有兩個要素:
- Base Model 之間的相關性要儘可能的小。這就是為什麼非 Tree-based Model 往往表現不是最好但還是要將它們包括在 Ensemble 裡面的原因。Ensemble 的 Diversity 越大,最終 Model 的 Bias 就越低。
- Base Model 之間的效能表現不能差距太大。這其實是一個 Trade-off,在實際中很有可能表現相近的 Model 只有寥寥幾個而且它們之間相關性還不低。但是實踐告訴我們即使在這種情況下 Ensemble 還是能大幅提高成績。
5.1 Stacking
相比 Blending,Stacking 能更好地利用訓練資料。以 5-Fold Stacking 為例,它的基本原理如圖所示:
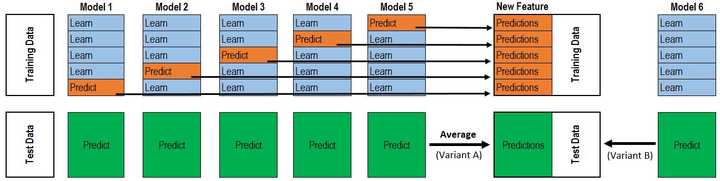
整個過程很像 Cross Validation。首先將訓練資料分為 5 份,接下來一共 5 個迭代,每次迭代時,將 4 份資料作為 Training Set 對每個 Base Model 進行訓練,然後在剩下一份 Hold-out Set 上進行預測。同時也要將其在測試資料上的預測儲存下來。這樣,每個 Base Model 在每次迭代時會對訓練資料的其中 1 份做出預測,對測試資料的全部做出預測。5 個迭代都完成以後我們就獲得了一個 #訓練資料行數 x #Base Model 數量 的矩陣,這個矩陣接下來就作為第二層的 Model 的訓練資料。當第二層的 Model 訓練完以後,將之前儲存的 Base Model 對測試資料的預測(因為每個 Base Model 被訓練了 5 次,對測試資料的全體做了 5 次預測,所以對這 5 次求一個平均值,從而得到一個形狀與第二層訓練資料相同的矩陣)拿出來讓它進行預測,就得到最後的輸出。
這裡給出我的實現程式碼:
-
class
Ensemble
(
object
):
-
def
__init__
(
self
,
n_folds
,
stacker
,
base_models
):
-
self
.
n_folds
=
n_folds
-
self
.
stacker
=
stacker
-
self
.
base_models
=
base_models
-
def
fit_predict
(
self
,
X
,
y
,
T
):
-
X
=
np
.
array
(
X
)
-
y
=
np
.
array
(
y
)
-
T
=
np
.
array
(
T
)
-
folds
=
list
(
KFold
(
len
(
y
),
n_folds
=
self
.
n_folds
,
shuffle
=
True
,
random_state
=
2016
))
-
S_train
=
np
.
zeros
((
X
.
shape
[
0
],
len
(
self
.
base_models
)))
-
S_test
=
np
.
zeros
((
T
.
shape
[
0
],
len
(
self
.
base_models
)))
-
for
i
,
clf
in
enumerate
(
self
.
base_models
):
-
S_test_i
=
np
.
zeros
((
T
.
shape
[
0
],
len
(
folds
)))
-
for
j
,
(
train_idx
,
test_idx
)
in
enumerate
(
folds
):
-
X_train
=
X
[
train_idx
]
-
y_train
=
y
[
train_idx
]
-
X_holdout
=
X
[
test_idx
]
-
# y_holdout = y[test_idx]
-
clf
.
fit
(
X_train
,
y_train
)
-
y_pred
=
clf
.
predict
(
X_holdout
)[:]
-
S_train
[
test_idx
,
i
]
=
y_pred
-
S_test_i
[:,
j
]
=
clf
.
predict
(
T
)[:]
-
S_test
[:,
i
]
=
S_test_i
.
mean
(
1
)
-
self
.
stacker
.
fit
(
S_train
,
y
)
-
y_pred
=
self
.
stacker
.
predict
(
S_test
)[:]
-
return
y_pred
獲獎選手往往會使用比這複雜得多的 Ensemble,會出現三層、四層甚至五層,不同的層數之間有各種互動,還有將經過不同的 Preprocessing 和不同的 Feature Engineering 的資料用 Ensemble 組合起來的做法。但對於新手來說,穩穩當當地實現一個正確的 5-Fold Stacking 已經足夠了。
6. Pipeline
可以看出 Kaggle 比賽的 Workflow 還是比較複雜的。尤其是 Model Selection 和 Ensemble。理想情況下,我們需要搭建一個高自動化的 Pipeline,它可以做到:
- 模組化 Feature Transform,只需寫很少的程式碼就能將新的 Feature 更新到訓練集中。
- 自動化 Grid Search,只要預先設定好使用的 Model 和引數的候選,就能自動搜尋並記錄最佳的 Model。
- 自動化 Ensemble Generation,每個一段時間將現有最好的 K 個 Model 拿來做 Ensemble。
對新手來說,第一點可能意義還不是太大,因為 Feature 的數量總是人腦管理的過來的;第三點問題也不大,因為往往就是在最後做幾次 Ensemble。但是第二點還是很有意義的,手工記錄每個 Model 的表現不僅浪費時間而且容易產生混亂。
Crowdflower Search Results Relevance 的第一名獲得者 Chenglong Chen 將他在比賽中使用的 Pipeline 公開了,非常具有參考和借鑑意義。只不過看懂他的程式碼並將其中的邏輯抽離出來搭建這樣一個框架,還是比較困難的一件事。可能在參加過幾次比賽以後專門抽時間出來做會比較好。
II. Home Depot Search Relevance
在這一節中我會具體分享我在 Home Depot Search Relevance 比賽中是怎麼做的,以及比賽結束後從排名靠前的隊伍那邊學到的做法。關於這次比賽的程式碼我都放在 GitHub 上了,主要的工作都可以在這個 Jupyter Notebook 中找到:https://github.com/dnc1994/Kaggle-Playground/blob/master/home-depot/Preprocess.ipynb
首先簡單介紹這個比賽。Task 是判斷使用者搜尋的關鍵詞和網站返回的結果之間的相關度有多高。相關度是由 3 個人類打分取平均得到的,每個人可能打 1 ~ 3 分,所以這是一個迴歸問題。資料中包含使用者的搜尋詞,返回的產品的標題和介紹,以及產品相關的一些屬性比如品牌、尺寸、顏色等。使用的評分基準是 RMSE。
這個比賽非常像 Crowdflower Search Results Relevance 那場比賽。不過那邊用的評分基準是 Quadratic Weighted Kappa,把 1 誤判成 4 的懲罰會比把 1 判成 2 的懲罰大得多,所以在最後 Decode Prediction 的時候會更麻煩一點。除此以外那次比賽沒有提供產品的屬性。
1. EDA
由於加入比賽比較晚,當時已經有相當不錯的 EDA 了。尤其是這個。從中我得到的啟發有:
- 同一個搜尋詞/產品都出現了多次,資料分佈顯然不 i.i.d.。
- 文字之間的相似度很有用。
- 產品中有相當大一部分缺失屬性,要考慮這會不會使得從屬性中得到的 Feature 反而難以利用。
- 產品的 ID 對預測相關度很有幫助,但是考慮到訓練集和測試集之間的重疊度並不太高,利用它會不會導致 Overfitting?
2. Preprocessing
這次比賽中我的 Preprocessing 和 Feature Engineering 的具體做法都可以在這裡看到。我只簡單總結一下和指出重要的點。
- 利用 Forum 上的 Typo Dictionary 修正搜尋詞中的錯誤。
- 統計屬性的出現次數,將其中出現次數多又容易利用的記錄下來。
- 將訓練集和測試集合並,並與產品描述和屬性 Join 起來。這是考慮到後面有一系列操作,如果不合並的話就要重複寫兩次了。
- 對所有文字能做 Stemming 和 Tokenizing,同時手工做了一部分格式統一化(比如涉及到數字和單位的)和同義詞替換。
3. Feature
-
*Attribute Features
- 是否包含某個特定的屬性(品牌、尺寸、顏色、重量、內用/外用、是否有能源之星認證等)
- 這個特定的屬性是否匹配
-
Meta Features
- 各個文字域的長度
- 是否包含屬性域
- 品牌(將所有的品牌做數值離散化)
- 產品 ID
-
簡單匹配
- 搜尋詞是否在產品標題、產品介紹或是產品屬性中出現
- 搜尋詞在產品標題、產品介紹或是產品屬性中出現的數量和比例
- *搜尋詞中的第 i 個詞是否在產品標題、產品介紹或是產品屬性中出現
-
搜尋詞和產品標題、產品介紹以及產品屬性之間的文字相似度
- BOWCosine Similairty
- TF-IDF Cosine Similarity
- Jaccard Similarity
- *Edit Distance
- Word2Vec Distance(由於效果不好,最後沒有使用,但似乎是因為用的不對)
-
Latent Semantic Indexing:通過將 BOW/TF-IDF Vectorization 得到的矩陣進行 SVD 分解,我們可以得到不同搜尋詞/產品組合的 Latent 標識。這個 Feature 使得 Model 能夠在一定程度上對不同的組合做出區別,從而解決某些產品缺失某些 Feature 的問題。
值得一提的是,上面打了 * 的 Feature 都是我在最後一批加上去的。問題是,使用這批 Feature 訓練得到的 Model 反而比之前的要差,而且還差不少。我一開始是以為因為 Feature 的數量變多了所以一些引數需要重新調優,但在浪費了很多時間做 Grid Search 以後卻發現還是沒法超過之前的分數。這可能就是之前提到的 Feature 之間的相互作用導致的問題。當時我設想過一個看到過好幾次的解決方案,就是將使用不同版本 Feature 的 Model 通過 Ensemble 組合起來。但最終因為時間關係沒有實現。事實上排名靠前的隊伍分享的解法裡面基本都提到了將不同的 Preprocessing 和 Feature Engineering 做 Ensemble 是獲勝的關鍵。
4. Model
我一開始用的是 RandomForestRegressor,後來在 Windows 上折騰 Xgboost 成功了就開始用 XGBRegressor。XGB 的優勢非常明顯,同樣的資料它只需要不到一半的時間就能跑完,節約了很多時間。
比賽中後期我基本上就是一邊桌上型電腦上跑 Grid Search,一邊在筆記本上繼續研究 Feature。
這次比賽資料分佈很不獨立,所以期間多次遇到改進的 Feature 或是 Grid Search 新得到的引數訓練出來的模型反而 LB 分數下降了。由於被很多前輩教導過要相信自己的 CV,我的決定是將 5-Fold 提到 10-Fold,然後以 CV 為標準繼續前進。
5. Ensemble
最終我的 Ensemble 的 Base Model 有以下四個:
- RandomForestRegressor
- ExtraTreesRegressor
- GradientBoostingRegressor
- XGBRegressor
第二層的 Model 還是用的 XGB。
因為 Base Model 之間的相關都都太高了(最低的一對也有 0.9),我原本還想引入使用 gblinear 的 XGBRegressor 以及 SVR,但前者的 RMSE 比其他幾個 Model 高了 0.02(這在 LB 上有幾百名的差距),而後者的訓練實在太慢了。最後還是隻用了這四個。
值得一提的是,在開始做 Stacking 以後,我的 CV 和 LB 成績的提高就是完全同步的了。
在比賽最後兩天,因為身心疲憊加上想不到還能有什麼顯著的改進,我做了一件事情:用 20 個不同的隨機種子來生成 Ensemble,最後取 Weighted Average。這個其實算是一種變相的 Bagging。其意義在於按我實現 Stacking 的方式,我在訓練 Base Model 時只用了 80% 的訓練資料,而訓練第二層的 Model 時用了 100% 的資料,這在一定程度上增大了 Overfitting 的風險。而每次更改隨機種子可以確保每次用的是不同的 80%,這樣在多次訓練取平均以後就相當於逼近了使用 100% 資料的效果。這給我帶來了大約 0.0004 的提高,也很難受說是真的有效還是隨機性了。
比賽結束後我發現我最好的單個 Model 在 Private LB 上的得分是 0.46378,而最終 Stacking 的得分是 0.45849。這是 174 名和 98 名的差距。也就是說,我單靠 Feature 和調參進到了 前 10%,而 Stacking 使我進入了前 5%。
6. Lessons Learned
比賽結束後一些隊伍分享了他們的解法,從中我學到了一些我沒有做或是做的不夠好的地方:
- 產品標題的組織方式是有 Pattern 的,比如一個產品是否帶有某附件一定會用 With/Without XXX 的格式放在標題最後。
- 使用外部資料,比如 WordNet,Reddit 評論資料集等來訓練同義詞和上位詞(在一定程度上替代 Word2Vec)詞典。
- 基於字母而不是單詞的 NLP Feature。這一點我讓我十分費解,但請教以後發現非常有道理。舉例說,排名第三的隊伍在計算匹配度時,將搜尋詞和內容中相匹配的單詞的長度也考慮進去了。這是因為他們發現越長的單詞約具體,所以越容易被使用者認為相關度高。此外他們還使用了逐字元的序列比較(difflib.SequenceMatcher),因為這個相似度能夠衡量視覺上的相似度。像這樣的 Feature 的確不是每個人都能想到的。
- 標註單詞的詞性,找出中心詞,計算基於中心詞的各種匹配度和距離。這一點我想到了,但沒有時間嘗試。
- 將產品標題/介紹中 TF-IDF 最高的一些 Trigram 拿出來,計算搜尋詞中出現在這些 Trigram 中的比例;反過來以搜尋詞為基底也做一遍。這相當於是從另一個角度抽取了一些 Latent 標識。
- 一些新穎的距離尺度,比如 Word Movers Distance
- 除了 S