
caffe for python(1)
阿新 • • 發佈:2018-12-03
導言
本教程中,我們將會利用Caffe官方提供的深度模型——CaffeNet(該模型是基於Krizhevsky等人的模型的)來演示影象識別與分類。我們將分別用CPU和GPU來進行演示,並對比其效能。然後深入探討該模型的一些其它特徵。
1、準備工作
1.1 首先,安裝Python,numpy以及matplotlib。
#安裝Python環境、numpy、matplotlib
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
1.2 然後,載入Load caffe。
# caffe模組要在Python的路徑下; # 這裡我們將把caffe 模組新增到Python路徑下. import sys caffe_root = '../' #該檔案要從路徑{caffe_root}/examples下執行,否則要調整這一行。 sys.path.insert(0, caffe_root + 'python') import caffe # 如果你看到"No module named _caffe",那麼要麼就是你沒有正確編譯pycaffe;要麼就是你的路徑有錯誤。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
說明:該步驟,本人是將編譯好的pycaffe檔案下的全部東西複製到Python的“site-packages”下的。所以不知道按上述做法具體會出現什麼問題。
1.3 必要的話,需要事先下載“CaffeNet”模型,該模型是AlexNet的變形。
import os
if os.path.isfile(caffe_root + 'models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel'):
print 'CaffeNet found.'
else:
print 'Downloading pre-trained CaffeNet model...'
!../scripts/download_model_binary.py ../models/bvlc_reference_caffenet
- 1
- 2
- 3
- 4
- 5
- 6
說明:該步驟,本人是事先下載好”bvlc_reference_caffenet.caffemodel”,然後將其放在”caffe_root + ‘models/bvlc_reference_caffenet/”目錄下面,因為用程式碼下載太慢了。
2、載入網路並設定輸入預處理
2.1 將Caffe設定為CPU模式,並從硬碟載入網路。
caffe.set_mode_cpu()
model_def = caffe_root + 'models/bvlc_reference_caffenet/deploy.prototxt'
model_weights = caffe_root + 'models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel'
net = caffe.Net(model_def, # 定義模型結構
model_weights, # 包含了模型的訓練權值
caffe.TEST) # 使用測試模式(不執行dropout)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
2.2 設定輸入預處理(我們將用Caffe’s caffe.io.Transformer來進行預處理。不過該步驟與caffe的其它模組是相互獨立的,所以任何預處理程式碼應該都是可行的)。我們使用的CaffeNet模型預設的輸入影象格式是BGR格式的,其畫素值位於[0,255]之間,同時每個畫素值都減去了ImageNet影象的平均值。除此之外,通道的維數等於第一維(outermost)的大小。另外,因為matplotlib載入的影象的值位於[0,1]之間,並且格式是RGB格式,通道的維數等於innermost的維數,所以我們需要做一些變換(感覺這一段翻譯的太爛),如下:
# 載入ImageNet影象均值 (隨著Caffe一起釋出的)
mu = np.load(caffe_root + 'python/caffe/imagenet/ilsvrc_2012_mean.npy')
mu = mu.mean(1).mean(1) #對所有畫素值取平均以此獲取BGR的均值畫素值
print 'mean-subtracted values:', zip('BGR', mu)
# 對輸入資料進行變換
transformer = caffe.io.Transformer({'data': net.blobs['data'].data.shape})
transformer.set_transpose('data', (2,0,1)) #將影象的通道數設定為outermost的維數
transformer.set_mean('data', mu) #對於每個通道,都減去BGR的均值畫素值
transformer.set_raw_scale('data', 255) #將畫素值從[0,255]變換到[0,1]之間
transformer.set_channel_swap('data', (2,1,0)) #交換通道,從RGB變換到BGR
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
3、用CPU分類
3.1 現在我們開始進行分類。儘管我們只對一張影象進行分類,不過我們將batch的大小設定為50以此來演示batching。
# 設定輸入影象大小
net.blobs['data'].reshape(50, # batch 大小
3, # 3-channel (BGR) images
227, 227) # 影象大小為:227x227
- 1
- 2
- 3
- 4
3.2 載入影象(caffe自帶的)並進行預處理。
image = caffe.io.load_image(caffe_root + 'examples/images/cat.jpg')
transformed_image = transformer.preprocess('data', image)
plt.imshow(image)
plt.show()
- 1
- 2
- 3
- 4

說明:這裡的”plt.show()”是我自己加的,不加的話沒法顯示影象。
3.3 接下來,開始進行識別分類
# 將影象資料拷貝到為net分配的記憶體中
net.blobs['data'].data[...] = transformed_image
### 執行分類
output = net.forward()
output_prob = output['prob'][0] #batch中第一張影象的概率值
print 'predicted class is:', output_prob.argmax()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
predicted class is: 281
網路輸出是一個概率向量;最可能的類別是第281個類別。但是結果是否正確呢,讓我們來檢視一下ImageNet的標籤。
# 載入ImageNet標籤
labels_file = caffe_root + 'data/ilsvrc12/synset_words.txt'
if not os.path.exists(labels_file):
!../data/ilsvrc12/get_ilsvrc_aux.sh
labels = np.loadtxt(labels_file, str, delimiter='\t')
print 'output label:', labels[output_prob.argmax()]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
說明:ImageNet標籤檔案(synset_words.txt)需要自己下載
output label: n02123045 tabby, tabby cat
”Tabby cat”是正確的,然後我們再來看下其它幾個置信的較高的結果。
# sort top five predictions from softmax output
top_inds = output_prob.argsort()[::-1][:5] # reverse sort and take five largest items
print 'probabilities and labels:'
zip(output_prob[top_inds], labels[top_inds])
- 1
- 2
- 3
- 4
- 5
probabilities and labels:
[(0.31243637, 'n02123045 tabby, tabby cat'),
(0.2379719, 'n02123159 tiger cat'),
(0.12387239, 'n02124075 Egyptian cat'),
(0.10075711, 'n02119022 red fox, Vulpes vulpes'),
(0.070957087, 'n02127052 lynx, catamount')]
- 1
- 2
- 3
- 4
- 5
我們可以看出,較低置信度的結構也是合理的。
4、GPU模式
4.1 讓我們先看下CPU的分類時間,然後再與GPU進行比較。
%timeit net.forward()
- 1
1 loop, best of 3: 1.42 s per loop
還是需要一段時間的,即使是對批量的50張影象。然後,讓我們看下GPU模式下的執行時間。
caffe.set_device(0) # 如果你有多個GPU,那麼選擇第一個
caffe.set_mode_gpu()
net.forward() # run once before timing to set up memory
%timeit net.forward()
- 1
- 2
- 3
- 4
10 loops, best of 3: 70.2 ms per loop
這下就快多了。
5、測試網路的中間層輸出
我們的網路不單單是一個黑盒子。接下來,我們來看下該模型的一些引數和一些中間輸出。首先,我們來看下如何讀取網路的結構(每層的名字以及相應層的引數)。對於每一層,其結構構成為:(batch_size, channel_dim, height, width)。
# 對於每一層,顯示輸出型別。
for layer_name, blob in net.blobs.iteritems():
print layer_name + '\t' + str(blob.data.shape)
data (50, 3, 227, 227)
conv1 (50, 96, 55, 55)
pool1 (50, 96, 27, 27)
norm1 (50, 96, 27, 27)
conv2 (50, 256, 27, 27)
pool2 (50, 256, 13, 13)
norm2 (50, 256, 13, 13)
conv3 (50, 384, 13, 13)
conv4 (50, 384, 13, 13)
conv5 (50, 256, 13, 13)
pool5 (50, 256, 6, 6)
fc6 (50, 4096)
fc7 (50, 4096)
fc8 (50, 1000)
prob (50, 1000)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
現在,我們來看下引數的形狀。引數是OrderdDict型別,net.params。我們根據索引來訪問引數。[0]:表示weights,[1]:表示biases。
引數形狀的構成為:
(output_channels, input_channels, filter_height, filter_width)為weights;(output_channels,)為biases。
for layer_name, param in net.params.iteritems():
print layer_name + '\t' + str(param[0].data.shape), str(param[1].data.shape)
conv1 (96, 3, 11, 11) (96,)
conv2 (256, 48, 5, 5) (256,)
conv3 (384, 256, 3, 3) (384,)
conv4 (384, 192, 3, 3) (384,)
conv5 (256, 192, 3, 3) (256,)
fc6 (4096, 9216) (4096,)
fc7 (4096, 4096) (4096,)
fc8 (1000, 4096) (1000,)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
因為我們處理的是四位資料,所以我們將定義一個幫助函式來視覺化特徵。
def vis_square(data):
"""輸入一個形如:(n, height, width) or (n, height, width, 3)的陣列,並對每一個形如(height,width)的特徵進行視覺化sqrt(n) by sqrt(n)"""
# 正則化資料
data = (data - data.min()) / (data.max() - data.min())
# 將濾波器的核轉變為正方形
n = int(np.ceil(np.sqrt(data.shape[0])))
padding = (((0, n ** 2 - data.shape[0]),
(0, 1), (0, 1)) # 在相鄰的濾波器之間加入空白
+ ((0, 0),) * (data.ndim - 3)) # 不擴充套件最後一維
data = np.pad(data, padding, mode='constant', constant_values=1) # 擴充套件一個畫素(白色)
# tile the filters into an image
data = data.reshape((n, n) + data.shape[1:]).transpose((0, 2, 1, 3) + tuple(range(4, data.ndim + 1)))
data = data.reshape((n * data.shape[1], n * data.shape[3]) + data.shape[4:])
plt.imshow(data)
plt.axis('off')
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
首先,我們來看下第一個卷積層(conv1)的輸出特徵。
# 引數為一個[weights, biases]的列表
filters = net.params['conv1'][0].data
vis_square(filters.transpose(0, 2, 3, 1))
- 1
- 2
- 3

上圖為conv1的輸出。
feat = net.blobs['conv1'].data[0, :36]
vis_square(feat)
- 1
- 2

上圖為pool5的輸出。
feat = net.blobs['pool5'].data[0]
vis_square(feat)
- 1
- 2

上圖為第一個全連線層(fc6)的輸出。
接下來,我們將顯示輸出結果及直方圖。
feat = net.blobs['fc6'].data[0]
plt.subplot(2, 1, 1)
plt.plot(feat.flat)
plt.subplot(2, 1, 2)
_ = plt.hist(feat.flat[feat.flat > 0], bins=100)
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
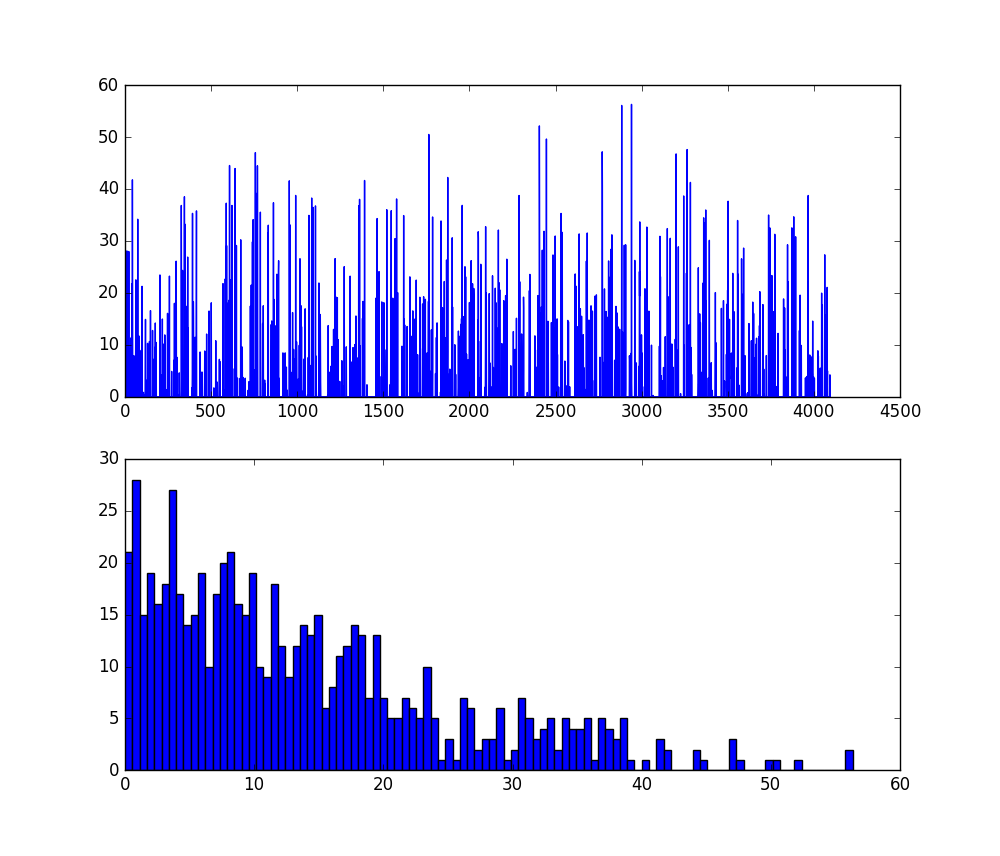
上圖為最終的概率輸出,prob。
feat = net.blobs['prob'].data[0]
plt.figure(figsize=(15, 3))
plt.plot(feat.flat)
plt.show()
- 1
- 2
- 3
- 4

上圖顯示了分類的聚類結果,峰值對應的標籤為預測結果。
6、測試自己的影象
現在,我們隨便從網上找一種影象,然後安裝上述步驟來進行分類。
將”my_image_url”設為影象的連結(URL)
# 下載影象
my_image_url = "..." # 將你的影象URL貼上到這裡
# 例如:
# my_image_url = "https://upload.wikimedia.org/wikipedia/commons/b/be/Orang_Utan%2C_Semenggok_Forest_Reserve%2C_Sarawak%2C_Borneo%2C_Malaysia.JPG"
!wget -O image.jpg $my_image_url
# 變換影象並將其拷貝到網路
image = caffe.io.load_image('image.jpg')
net.blobs['data'].data[...] = transformer.preprocess('data', image)
# 預測分類結果
net.forward()
# 獲取輸出概率值
output_prob = net.blobs['prob'].data[0]
# 將softmax的輸出結果按照從大到小排序,並提取前5名
top_inds = output_prob.argsort()[::-1][:5]
plt.imshow(image)
plt.show()
print 'probabilities and labels:'
zip(output_prob[top_inds], labels[top_inds])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23