
caffe練習例項(1)——訓練mnist資料集
阿新 • • 發佈:2019-01-29
1.簡介
這是一個非常簡單的例項,主要是為了這個簡單的例項瞭解caffe的工作流程。
2.操作流程
1.獲取資料
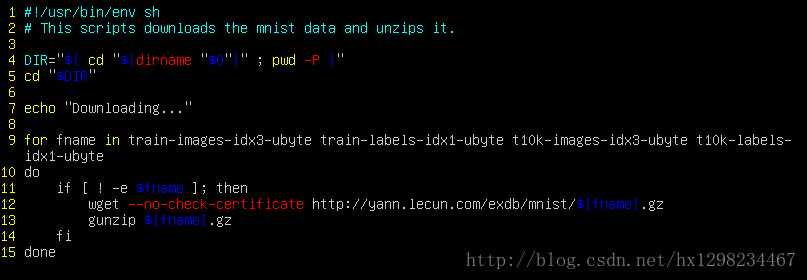
在caffe-master/data/mnist資料夾中只有一個get_mnist.sh可執行檔案,我們需要執行這個檔案獲取mnist所需要的資料。
- 執行命令:
./data/mnist/get_mnist.sh - get_mnist.sh原始碼解析:
通過原始碼我們可以知道,這個指令碼主要是下載t10k-images-idx3-ubyte t10k-labels-idx1-ubyte train-images-idx3-ubyte train-labels-idx1-ubyte 這四個檔案 然後解壓 - 執行完命令後的檔案目錄:
get_mnist.sh檔案是原有的,其他四個檔案是下載的。

2.將資料轉化為lmdb格式
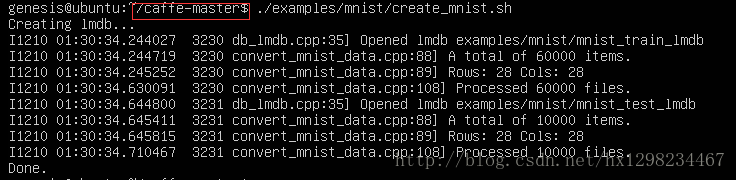
- 命令:./examples/mnist/create_mnist.sh
- 注意:在這裡可能會遇到一個bug,如下:
- 問題描述:
- 原因是:指令碼執行必須在caffe資料夾的根目錄下執行,,而我在examples/mnist/目錄下執行指令碼,所以報錯。
- 問題描述:

3.訓練
命令:./examples/mnist/train_lenet.sh
train_lenet.sh原始碼解析:
- 原始碼:
- 解釋:train是我們在安裝caffe的時候已經編譯好的二進位制檔案,tools資料夾中還有很多工具,訓練呼叫的是caffe原始碼中tools資料夾中的二進位制檔案,solver後面跟的是定義優化方式的prototxt檔案
- 原始碼:
注意:訓練的時候,如果安裝的時候選擇了CPU_ONLY的話,在*.prototxt檔案中,把“mode:GPU”改成“mode:CPU”
lenet_solver.prototxt檔案原始碼解析:


4.結果
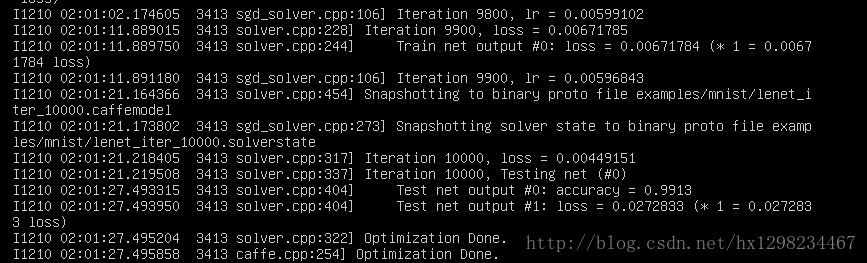
這裡僅用CPU進行訓練,大概用15分鐘左右,準確率為99.13%。