
【統計學習方法-李航-筆記總結】九、EM(Expectation Maximization期望極大演算法)演算法及其推廣
本文是李航老師《統計學習方法》第九章的筆記,歡迎大佬巨佬們交流。
主要參考部落格:
https://www.cnblogs.com/YongSun/p/4767517.html
https://blog.csdn.net/u010626937/article/details/75116000
主要包括以下內容:
1. EM演算法的引入
2. EM演算法的收斂性
3. EM演算法在高斯混合學習模型中的應用
4. EM演算法的推廣
EM演算法是一種迭代演算法,用於含有隱變數(hidden variable)的概率模型引數的極大似然估計,或極大後驗概率估計。EM演算法的每次迭代由兩步組成:E步,求期望(expectation)
對於極大似然估計的補充:
極大似然估計,只是一種概率論在統計學中的應用,它是引數估計的方法之一。說的是已知某個隨機樣本滿足某種概率分佈,但是其中具體的引數不清楚,引數估計就是通過若干次實驗,觀察其結果,利用結果推出引數的大概值。最大似然估計是建立在這樣的思想上:已知某個引數能使這個樣本出現的概率值最大,我們當然不會再去選擇其他小概率的樣本,所以乾脆就把這個引數作為估計的真實值。最大似然估計你可以把它看作是一個反推。多數情況下我們是根據已知條件來推算結果,而最大似然估計是已經知道了結果,然後尋求使該結果出現的可能性最大的條件,以此作為估計值。
求最大似然函式估計值的一般步驟:
(1) 寫出似然函式;
(2) 對數似然函式取對數,並整理;
(3) 求導數,令導數為0,得到似然方程;
(4) 解似然方程,得到的引數即為所求。最大(極大)似然估計也是統計學習中經驗風險最小化(RRM)的例子。如果模型為條件概率分佈,損失函式定義為對數損失函式,經驗風險最小化就等價於最大似然估計。
對於幾種估計的詳述可參考前文:https://blog.csdn.net/zl3090/article/details/82989065
對於極大似然估計的例子可參考部落格:https://blog.csdn.net/pipisorry/article/details/51461997?utm_source=blogxgwz0
1. EM演算法的引入
概率模型又是既含有觀測變數,又含有隱變數或潛在變數,如果概率模型的變數都是觀測變數,那麼給定資料,可以直接利用極大似然估計法,或貝葉斯估計法估計模型引數,但是當模型含有隱變數時,就不能簡單地使用這些方法,EM演算法就是含有隱變數的概率模型引數的極大似然估計法,或極大後驗概率估計法。
(1)EM演算法
三硬幣模型:

求解過程:
三硬幣模型可寫作(一次實驗後的結果):
其中,y是觀測變數,表示一次實驗的結果是1或者0,z是隱變數,表示未觀測到的硬幣A的拋擲結果;
是引數模型,是以上資料的生成模型。
將觀測資料表示為,未觀測資料表示為
,則觀測資料的似然函式為:
求引數模型的極大似然估計,即
這個問題沒有解析解,只有通過迭代的方法求解,EM演算法就是可以用於求解這一問題的迭代演算法。
按照EM演算法,首先選取引數的初始值,記作,然後通過迭代計算引數估計值,直到收斂為止。
第i次迭代引數的估計值為:,第i+1次迭代為:
E步:計算觀測資料yi來自硬幣B的概率:
M步:計算模型引數的新估計值:
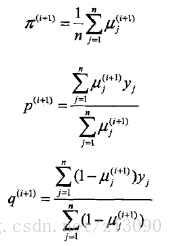
進行數字計算:
假設模型引數的初值為:
代入上述式子,得:

於是得到模型引數θ的極大似然估計:
如果選擇不同的初值會有不同的結果,也就說明了EM演算法與初值的選擇有關。
一般地,用Y表示觀測隨機變數的資料,Z表示隱隨機變數的資料。Y和Z連在一起稱為完全資料( complete-data ),觀測資料Y又稱為不完全資料(incomplete-data)。假設給定觀測資料Y,其概率分佈是P(Y | θ),其中θ是需要估計的模型引數,那麼不完全資料Y的似然函式是P(Y | θ),對數似然函式L(θ)=logP(Y | θ);假設Y和Z的聯合概率分佈是P(Y, Z),那麼完全資料的對數似然函式是log P(Y, Z | θ)。
EM演算法描述如下:


Q函式:完全資料的對數似然函式log P(Y, Z | θ)關於在給定觀測資料Y和當前引數θ(i)下對未觀測資料Z的條件概率分佈P(Z | Y,θ(i))的期望稱為Q函式,即
![]()
EM演算法說明:
步驟(1)引數的初值可以任意選擇。但需注意EM演算法對初值是敏感的。
步驟(2) E步求Q( θ, θ(i))。Q函式式中Z是未觀測資料,Y是觀測資料。注意,Q( θ, θ(i))的第1個變數 θ表示要極大化的引數,第2個變數 θ(i)表示引數的當前估計值。每次迭代實際在求Q函式及其極大。
步驟(3) M步求Q( θ, θ(i))的極大化,得到 θ(i+1),完成一次迭代 θ(i)--> θ(i+1)。後面將證明每次迭代使似然函式增大或達到區域性極值。
步驟(4)給出停止迭代的條件,一般是對較小的正數,若滿足![]() 則停止迭代。
則停止迭代。
(2)EM演算法的匯出
下邊解釋為什麼EM演算法可以實現對觀測資料的極大似然估計:
對於一個含有隱變數的概率模型,目標是極大化觀測資料(不完全資料),Y關於引數θ的對數似然函式,即極大化:
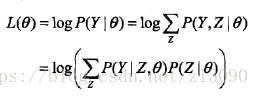
注意到這一極大化的主要困難是上式中有未觀測資料(Z)幷包含和(或積分)的對數。
事實上,EM演算法是通過迭代逐步近似極大化L(θ)的,假設在第i次迭代後,θ的估計值是θ(i),我們希望新估計值θ能使L(θ)增加,並逐步達到極大值,因此考慮兩者的差:
利用Jensen不等式,得到其下界:(Jensen不等式詳見https://baike.baidu.com/item/%E7%90%B4%E7%94%9F%E4%B8%8D%E7%AD%89%E5%BC%8F/397409?fr=aladdin)
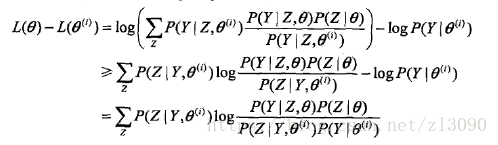
令:
則:
因此,函式B是L的一個下界,任何使B增大的θ也可以使L增大,為了使L(θ)有儘可能大的增長,選擇θ(i+1)是B達到極大,即:

上式等價於EM演算法的一次迭代,即求Q函式及其極大化,下圖給出EM演算法的直觀解釋:

圖中上方曲線為L(θ),下方曲線為B(θ, θ(i)),為對數似然函式L(θ)的下界,且在 θ=θ(i)處相等。EM演算法找到下一個點θ(i+1)使函式B(θ, θ(i))極大化,也使函式Q(θ, θ(i))極大化。函式B的增加,保證對數似然函式L在每次迭代中也是增加的。EM演算法在點θ(i+1)重新計算Q函式值,進行下一次迭代。在這個過程中,對數似然函式L不斷增大。從圖可以推斷出EM演算法不能保證找到全域性最優值。
(3)EM演算法在非監督學習中的應用
訓練資料只有輸入沒有對應的輸出(X,?),從這樣的資料學習模型稱為非監督學習問題。EM演算法可以用於生成模型的非監督學習,生成模型由聯合概率分佈P(X, Y)表示,可以認為非監督學習訓練資料是聯合概率分佈產生的資料。X為觀測資料,Y為未觀測資料。
2. EM演算法的收斂性
EM演算法的最大優點是簡單性和普適性,下邊探索EM演算法得到的序列估計的收斂性:
定理 :設P(Y | θ)為觀測資料的似然函式,θ(i) (i=1, 2,...)為EM演算法得到的引數估計序列,P(Y | θ(i) )(i=1, 2,...))為對應的似然函式序列,則P(Y | θ(i) )是單調遞增的,即:
![]()
定理 :設P(Y | θ)為觀測資料的似然函式,θ(i) (i=1, 2,...)為EM演算法得到的引數估計序列,L(θ(i))=P(Y | θ(i) )(i=1, 2,...))為對應的似然函式序列,
(1)如果P(Y | θ)有上界,則L(θ(i))收斂到某一值L*;
(2)在函式Q與L滿足一定條件下,由EM演算法得到的引數估計序列θ(i)的收斂值θ*是L(θ)的穩定點。
EM演算法的收斂性包含關於對數似然函式序列L的收斂性和關於引數估計序列θ的收斂性兩層意思,前者並不蘊涵後者。此外,定理只能保證引數估計序列收斂到對數似然函式序列的穩定點,不能保證收斂到極大值點。所以在應用中,初值的選擇變得非常重要,常用的辦法是選取幾個不同的初值進行迭代,然後對得到的各個估計值加以比較,從中選擇最好的。
3. EM演算法在高斯混合學習模型中的應用
EM演算法的一個重要應用是高斯混合模型的引數估計。
高斯混合模型:高斯混合模型是指具有如下形式的概率分佈模型:,

高斯混合模型引數估計中的EM演算法:
假設觀測資料由上述高斯模型生成,我們利用EM算的估計高斯混合模型的引數θ:
(1) 明確隱變數,寫出完全資料的對數似然函式:
可以設想觀測資料yj是這樣產生的:首先依概率ak選擇第k個高斯分佈分模型;然後依第k個分模型的概率分佈生成觀測
資料yj。這時觀測資料yj是已知的;反映觀測資料yj來自第k個分模型的資料是未知的,k=1,2,... ,K,為隱變數定義如下:

有了觀測資料yi及未觀測資料,那麼完全資料是:
於是,完全資料的似然函式是:

其中,
那麼,完全資料的對數似然函式為:
(2)EM演算法的E步:確定Q函式

(3)確定EM演算法的M步:
迭代的M步是求函式Q的極大值,即求新一輪迭代的模型引數:
通過求偏導並令其為0,可以得到:

其中,得到的。
高斯混合模型引數估計的EM演算法:

4. EM演算法的推廣
EM演算法還可以理解為F函式的極大-極大演算法,基於這個解釋有若干變形與推廣,如廣義期望極大(GEM演算法)等。
(1)F函式的極大-極大演算法
F函式:假設隱變數資料Z的概率分佈為,定義分佈
與引數θ的函式F(
,θ)如下:
稱為F函式,式中是分佈
的熵。
引理1:對於固定的θ,存在唯一的分佈極大化
,這時
由下式給出:
,並且
隨θ連續變化。
引理2:若,則
定理1:設L(θ) = logP(Y|θ)為觀測資料的對數似然函式,,i =1,2,...,為EM演算法得到的引數估計序列,函式
由上述F函式定義,如果
在
和
有區域性極大值,那麼L(θ)也在
有區域性極大值;如果
在
和
達到全域性最大值,那麼L(θ)也在
達到全域性最大值。
定理2:EM演算法的一次迭代可以由F函式的極大-極大演算法實現,設為第i次迭代引數θ的估計,
為第i次迭代函式
的估計,在第i+1次迭代的兩步為:
(1)對固定的,求
使
極大化;
(2)對固定的,求
使
極大化;
(2)GEM演算法
演算法1:

在GEM演算法1中,有時求Q(theta,theta(i))的極大化是很困難的。 GEM演算法2和GEM演算法3並不是直接求theta(i+1)使Q達到極大的theta,而是找一個theta(i+1)使得Q(theta(i+1), theta(i)) >Q(theta(i), theta(i))。
演算法2:

演算法3:
