
【統計學習方法-李航-筆記總結】六、邏輯斯諦迴歸和最大熵模型
本文是李航老師《統計學習方法》第六章的筆記,歡迎大佬巨佬們交流。
主要參考部落格:
http://www.cnblogs.com/YongSun/p/4767100.html
https://blog.csdn.net/tina_ttl/article/details/53519391
https://blog.csdn.net/tina_ttl/article/details/53542004
主要內容包括:
1. 邏輯斯諦迴歸模型
2. 最大熵模型
3. 模型學習的最優化演算法
邏輯斯諦迴歸(logistic regression)是統計學習中的經典分類方法。最大熵是概率模型學習的一個準則將其推廣到分類
1. 邏輯斯諦迴歸模型
(1)logistic分佈
設X是連續隨機變數,X服從logistic分佈是指X具有下列分佈函式和密度函式:
式中,u為位置引數,r>0為形狀引數。
logistic分佈的密度函式f(x)和分佈函式F(x)的圖形如下圖所示。分佈函式屬於logistic函式,其圖形是一條S形曲線(sigmoid curve)。該曲線以點(u, 1/2)為中心對稱,即滿足:
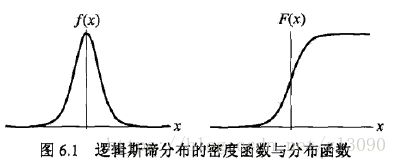
對於密度函式,曲線在中心附近增長速度較快,在兩端增長速度較慢,形狀引數γ的值越小,曲線在中心附近增長得越快,也就是越陡。
(2)二項logistic迴歸模型
二項logistic迴歸模型是一種分類模型,用於二類分類。由條件概率分佈P(Y|X)表示,形式為引數化的邏輯分佈。這裡,隨機變數X取值為實數,隨機變數Y取值為1或0。通過監督學習的方法來估計模型引數。
二項邏輯迴歸模型是如下的條件概率分佈:
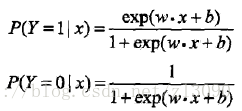
w稱為權值向量,b稱為偏置,w·x為w和x的內積。
將權值向量和輸入向量加以擴充為 w=(w(1),w(2),...,w(n), b), x =(x(1),x(2),...,x(n),1)T(轉置),logistic迴歸模型如下:
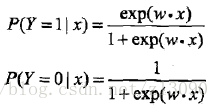
注1:P(Y=1|x)+P(Y=0|x)=1
注2:上面的二項logistic迴歸模型其實就是一個二項分佈的形式,即一次試驗的結果要麼為1、要麼為0,其中,結果為1的概率利用logistic分佈給出
一個事件的機率(odds)是指該事件發生的概率與該事件不發生的概率的比值,如果事件發生的概率是p,那麼該事件的對數機率(log odds)或logit函式是: ![]()
對logistic迴歸而言,![]() (帶入上述logistic公式可以推出)
(帶入上述logistic公式可以推出)
這就是說,在logistic迴歸模型中,輸出Y=1的對數機率是由輸入x的線性函式表示的模型。換個角度看,可以將線性函式w·x轉換為概率:,這時,線性函式的值越接近正無窮,概率值越接近1,線性函式的值越接近負無窮,概率越接近0,也呼應了上圖的logistic分佈函式。
(3)模型引數估計
可以應用極大似然估計法估計模型引數,設:
則,似然函式為:
對數似然函式為:
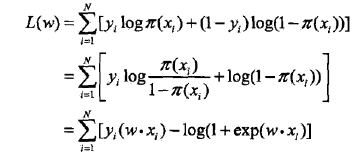
隨後,對L(w)求極大值,得到w的估計值,這樣,問題就變成了以對數似然函式為目標函式的最優化問題。邏輯迴歸學習中通常採用梯度下降法及擬牛頓法。
假設w的極大似然估計值為,那麼學到的logistic迴歸為:
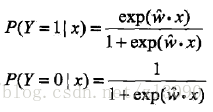
這是直接把w的估計值帶入邏輯迴歸的定義式得到的模型,上述求似然函式的極大值主要為了估計w。
(4)多項logistic迴歸
多項logistic迴歸模型(multi-nominal logistic regression model),用於多類分類,模型如下:
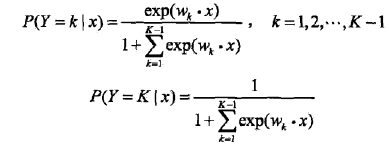
二項邏輯迴歸的引數估計法也可以推廣到多項邏輯迴歸。
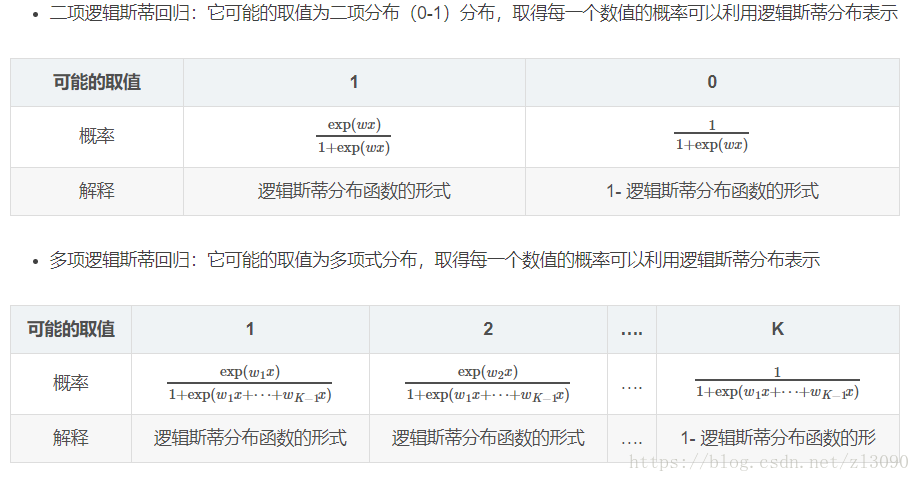
用表格來比較二項與多項logistic迴歸如下所示:
2. 最大熵模型
(1)最大熵原理
最大熵原理認為:在所有可能的概率模型中,熵最大的模型為最好的概率模型。
假設離散變數X的概率分佈是P(X),則其熵為:
(關於熵的具體解釋可參見部落格:https://blog.csdn.net/zl3090/article/details/83006572 中特徵選擇部分)
熵滿足下列不等式:
式中,|x|是X的取值個數,當且僅當X是均勻分佈的時候,右邊等號成立,也就是當X服從均勻分佈時,熵最大。
詳細證明請見部落格:https://blog.csdn.net/acdreamers/article/details/41413445
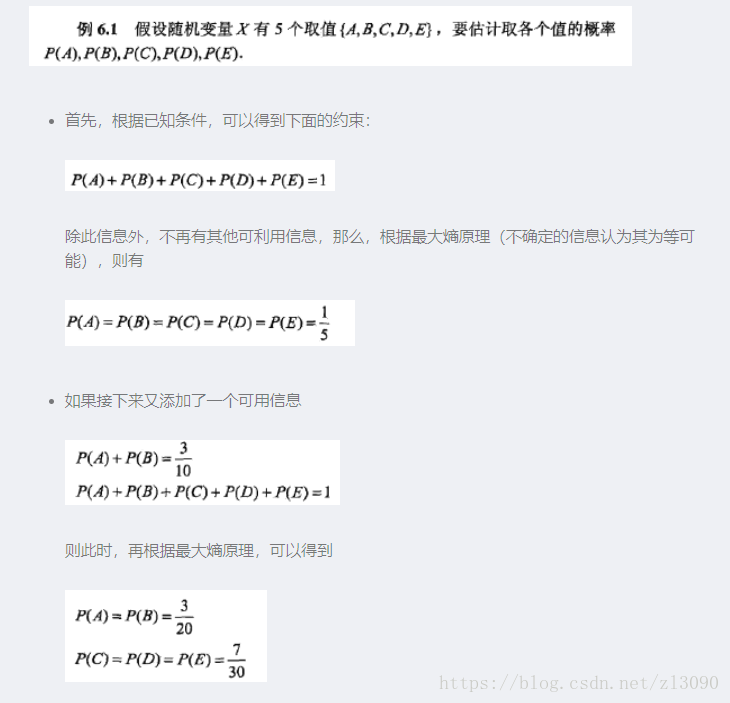
用一個例子來理解:
最大熵模型的幾何意義:
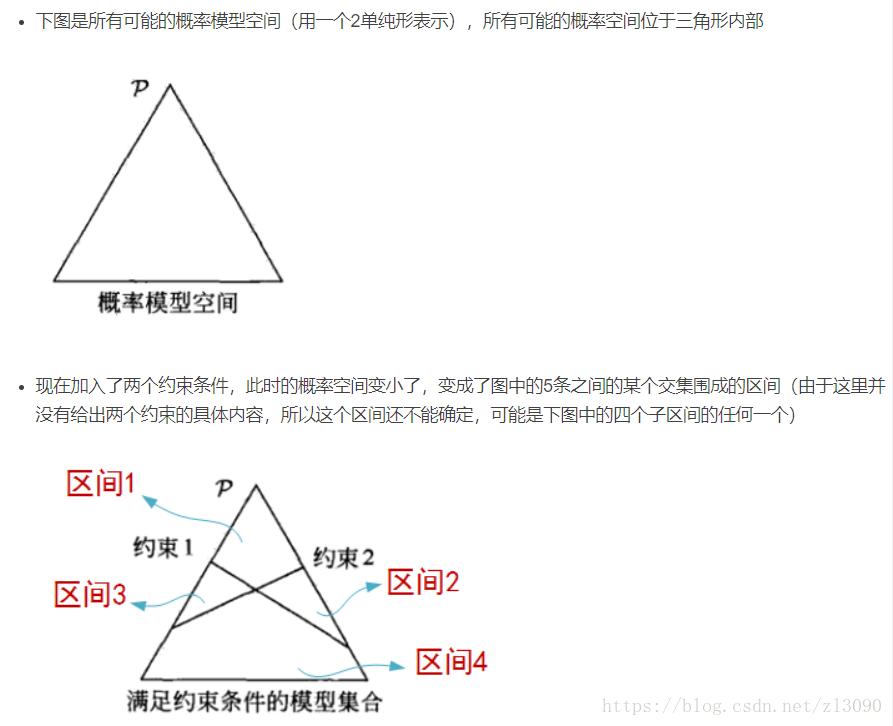
(2)最大熵模型(模型)
給定訓練資料集,可以確定聯合分佈P(X,Y)的經驗分佈和邊緣分佈P(X)的經驗分佈,
![]()
其中,v(X=x,Y=y)表示訓練資料中樣本(x,y)出現的頻數,v(X = x)表示訓練資料中輸入x出現的頻數,N表示訓練樣本容量。
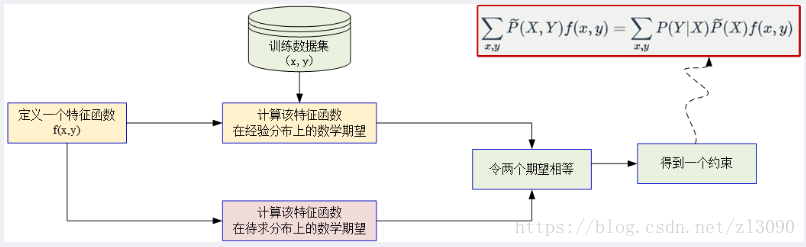
用特徵函式(feature function) f(x,y)描述輸入x和輸出Y之間的某一個事實。其定義是
![]()
特徵函式f(x,y)關於經驗分佈P~(X,Y)的期望值,用EP~(f)表示:
![]()
特徵函式f(x,y)關於模型P(Y|X)與經驗分佈P~(X)的期望值,用EP(f)表示:
![]()
如果模型能夠獲取訓練資料中的資訊,就可以假設上述兩個期望值相等,則約束條件為:
![]()
或:
上述過程可以總結如下:由於最大熵原理認為熵最大模型最好,而分佈約接近均勻分佈熵越大,因此我們要的約束應該是使分佈接近於均勻分佈的,因此可以將上述兩個期望相等(自己的理解),流程如下圖所示:
最大熵模型:假設滿足所有約束條件的模型集合為:![]() ,定義在條件概率分佈P(Y|X)上的條件熵為
,定義在條件概率分佈P(Y|X)上的條件熵為
![]()
則模型集合C中條件熵H(P)最大的模型稱為最大熵模型。
至此,最大熵模型總結如下:

可見,其實最大熵模型就是一個有約束的優化問題
(3)最大熵模型的學習(策略與演算法)
最大熵模型的學習過程就是求解最大熵模型的過程,可以形式化為約束最優化問題:
按照(2)中總結所述,最大熵模型的最優化等價於下式的約束最優化問題:
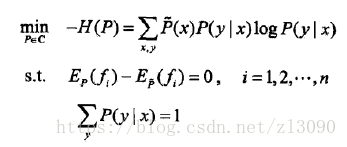
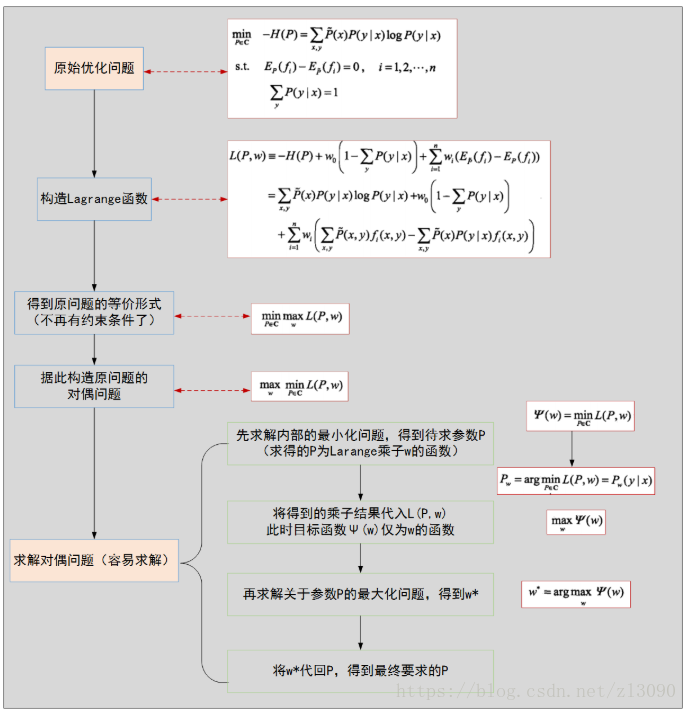
將約束最優化的原始問題轉換為無約束最優化的對偶問題,通過求解對偶問題求原解始問題:
引進拉格朗日乘子w0,w1,...wn,定義拉格朗日函式L(P,w):
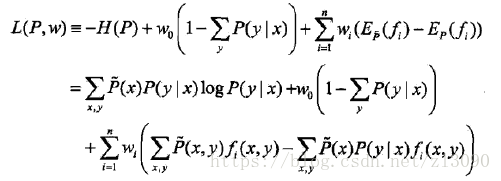
優化的原始問題是:
對偶問題是:
由於這裡的Lagrange函式是凸函式,所以原問題和對偶問題的最優解相同,接下來只需要求解對偶問題的最優解就可以:
簡單理解,拉格朗日函式就是把約束條件的乘子作為目標函式的一項,這樣可以使目標函式取得最優值時也能滿足約束條件, 對拉格朗日求解最優化問題原理的理解詳見部落格:https://www.cnblogs.com/sddai/p/5728195.html
需要注意的是,此處需要對P(y|x)求導,因為從條件熵的定義可以看出,條件概率P(y|x)是自變數。

上述過程圖解為:
用例子解釋上述過程:



(4)極大似然估計(等價形式)
從(3)中模型的求解可以看書,最大熵模型是所表示的條件概率分佈,下面研究它的等價形式,即對偶函式的極大化等價於最大熵模型的極大似然估計。
已知資料的經驗概率分佈為,條件概率分佈P(Y|X)的對數似然函式是:
,
當條件概率分佈P(y|x)是最大熵模型時,對數似然函式變為:
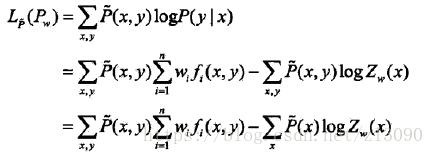
再看對偶函式:
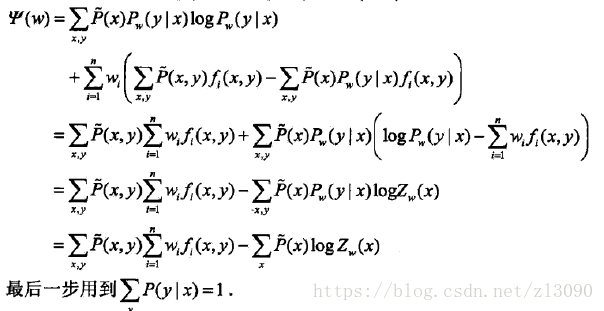
比較上述兩式,得:
因此,有對偶函式等價於對數似然函式,也就是說最大熵模型的學習問題可以轉化為具體求解對數似然函式極大化或對偶函式極大化問題。
可以將最大熵模型寫成更一般的公式:
其中,
3. 模型學習的最優化演算法
logistic迴歸模型、最大熵模型學習歸納為以似然函式為目標函式的優化問題,通常採用迭代法求解,常用的方法有改進的迭代尺度法、梯度下降法、牛頓法或者擬牛頓法。
(1)改進的迭代尺度法
改進的迭代尺度法(IIS)是一種最大熵模型學習的最優化演算法,它的想法是假設最大熵模型當前的引數向量是w=(w1, ..., wn)T,希望找到一個新的引數向量w + sigmal =(w1+sigmal1, ..., wn+sigmaln)T,使得模型的對數似然函式值增大。如果能有這樣一種引數向量更新的方法:w-->w + sigma,那麼就可以重複使用這一方法,直至找到對數似然函式的最大值。
對於給定的經驗分佈,模型引數從w到w+sigma,對數似然函式的改變數是:
利用不等式:
建立對數似然函式改變數的下界:
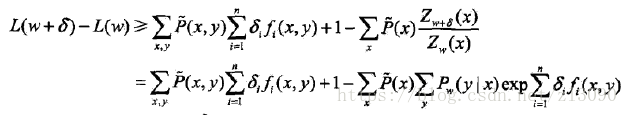
將右端記為
則有,
即A(δ|w)是對數似然函式的一個下界,若能找到適當的δ使下界提高,則對數似然函式也會同時提高,然而A(δ|w)中的δ是一個向量,有多個變數,不易同時優化,IIS試圖一次只優化一個變數,而固定其他變數,IIS演算法流程如下:

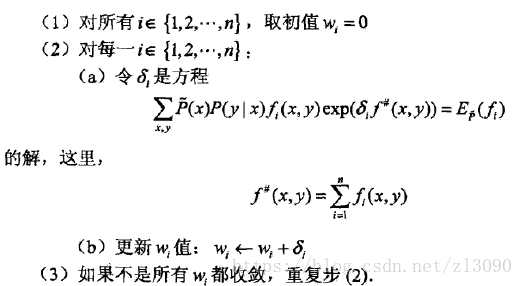

(2)擬牛頓法
最大熵模型的學習還可以用牛頓法或者擬牛頓法,對於最大熵模型而言:
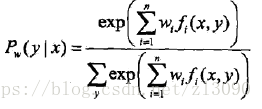
目標函式為:,
梯度為:,其中
相應的擬牛頓演算法(BFGS)流程如下:

最後,關於logistic迴歸與最大熵模型的區別還有待進一步理解,先大致參見這一部落格: