
開源 serverless 產品原理剖析
背景
Serverless 架構的出現讓開發者不用過多地考慮傳統的伺服器採購、硬體運維、網路拓撲、資源擴容等問題,可以將更多的精力放在業務的拓展和創新上。
隨著 serverless 概念的深入人心,各大雲端計算廠商紛紛推出了各自的 serverless 產品,其中比較有代表性的有 AWS lambda、Azure Function、Google Cloud Functions、阿里雲函式計算等。
另外,CNCF 也於 2016 年創立了 Serverless Working Group,它致力於 cloud native 和 serverless 技術的結合。下圖是 CNCF serverless 全景圖,它將這些產品分成了工具型、安全型、框架型和平臺型等類別。
同時,容器以及容器編排工具的出現,大大降低了 serverless 產品的開發成本,促進了一大批優秀開源 serverless 產品的誕生,它們大多構建於 kubernetes 之上,如下圖所示。
Kubeless 簡介
本文將要介紹的 kubeless 便是這些開源 serverless 產品的典型代表。根據官方的定義,kubeless 是 kubernetes native 的無服務計算框架,它可以讓使用者在 kubernetes 之上使用 FaaS 構建高階應用程式。從 CNCF 視角,kubeless 屬於平臺型產品。
Kubless 有三個核心概念:
- Functions - 代表需要被執行的使用者程式碼,同時包含執行時依賴、構建指令等資訊;
- Triggers - 代表和函式關聯的事件源。如果把事件源比作生產者,函式比作執行者,那麼觸發器就是聯絡兩者的橋樑;
- Runtime - 代表函式執行時所依賴的環境。
原理剖析
本章節將以 kubeless 為例介紹 serverless 產品需要具備的基本能力,以及 kubeless 是如何利用 K8s 現有功能來實現它們的。這些基本能力包括:
- 敏捷構建 - 能夠基於使用者提交的原始碼迅速構建可執行的函式,簡化部署流程;
- 靈活觸發 - 能夠方便地基於各類事件觸發函式的執行,並能方便快捷地整合新的事件源;
- 自動伸縮 - 能夠根據業務需求,自動完成擴容縮容,無須人工干預。
本文所做的調研基於kubeless v1.0.0和k8s 1.13。
敏捷構建
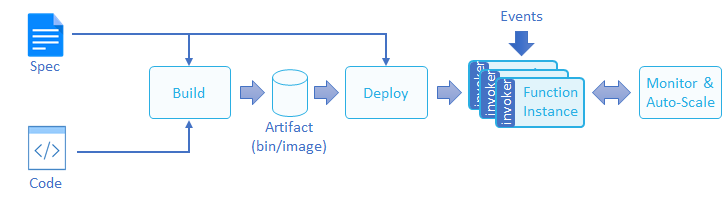
CNCF 對函式生命週期的定義如下圖所示。使用者只需提供原始碼和函式說明,構建部署等工作通常由 serverless 平臺完成。 因此,基於使用者提交的原始碼迅速構建可執行函式是 serverless 產品必須具備的基礎能力。
在 kubeless 裡,建立函式非常簡單:
kubeless function deploy hello --runtime python2.7 \
--from-file test.py \
--handler test.hello該命令各引數含義如下:
hello:將要部署的函式名稱;--runtime python2.7: 指定使用 python 2.7 作為執行環境。Kubeless 可供選擇的執行環境請參考連結 runtimes。--from-file test.py:指定函式原始碼檔案(支援 zip 格式)。--handler test.hello:指定使用 test.py 中的 hello 方法處理請求。
函式資源與 K8s Operator
Kubeless 函式是一個自定義 K8s 物件,本質上是 k8s operator。k8s operator 原理如下圖所示:
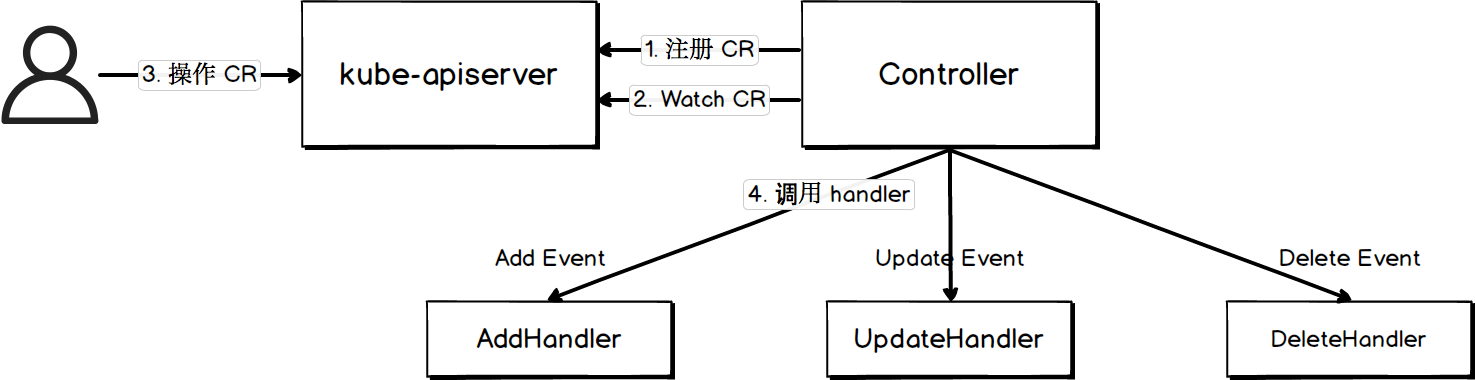
下面以 kubeless 函式為例,描述 K8s operator 的一般工作流程:
- 使用 k8s 的 CustomResourceDefinition(CRD) 定義資源,這裡建立了一個名為
functions.kubeless.io的 CRD 來代表 kubeless 函式; - 建立一個 controller 監聽自定義資源的 ADD、UPDATE、DELETE 事件並繫結 hander。這裡建立了一個名為
function-controller的 CRD controller,該 controller 會監聽針對 function 的 ADD、UPDATE、DELETE 事件,並繫結 handler(參閱 AddEventHandler); - 使用者執行建立、更新、刪除自定義資源的命令;
- Controller 根據監聽到的事件呼叫相應的 handler。
除了函式外,下文將要介紹的 trigger 也是一個 k8s operator。
函式構成
Kubeless 的 function-controller監聽到針對 function 的 ADD 事件後,會觸發相應 handler 建立函式。一個函式由若干 K8s 物件組成,包括 ConfigMap、Service、Deployment、Pod 等,其結構如下圖所示:
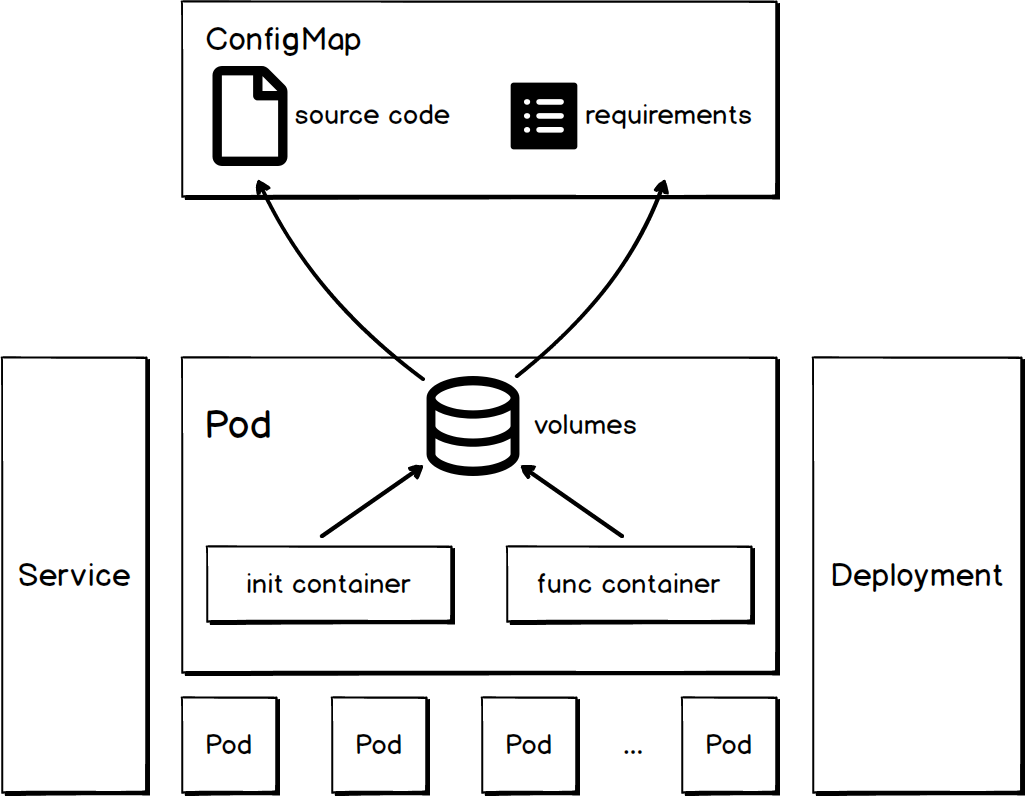
ConfigMap
函式中的 ConfigMap 用於描述函式原始碼和依賴。
apiVersion: v1
data:
handler: test.hello
# 函式依賴的第三方 python 庫
requirements.txt: |
kubernetes==2.0.0
# 函式原始碼
test.py: |
def hello(event, context):
print event
return event['data']
kind: ConfigMap
metadata:
labels:
created-by: kubeless
function: hello
# 該 ConfigMap 名稱
name: hello
namespace: default
...Service
函式中的 Service 用於描述該函式的訪問方式。該 Service 會與執行 function 邏輯的 Pods 相關聯,型別是 ClusterIP。
apiVersion: v1
kind: Service
metadata:
labels:
created-by: kubeless
function: hello
# 該 Service 名稱
name: hello
namespace: default
...
spec:
clusterIP: 10.109.2.217
ports:
- name: http-function-port
port: 8080
protocol: TCP
targetPort: 8080
selector:
created-by: kubeless
function: hello
# Service 型別
type: ClusterIP
...Deployment
函式中的 Deployment 用於編排執行函式邏輯的 Pods,通過它可以描述函式期望的個數。
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
labels:
created-by: kubeless
function: hello
name: hello
namespace: default
...
spec:
# 指定函式期望的個數
replicas: 1
...Pod
函式中的 Pod 包含真正執行函式邏輯的容器。
Volumes
Pod 中的 volumes 段指定了該函式的 ConfigMap。這會將 ConfigMap 中的原始碼和依賴新增到 volumeMounts.mountPath 指定的目錄裡面。從容器視角來看,檔案路徑為/src/test.py和 /src/requirements。
...
volumeMounts:
- mountPath: /kubeless
name: hello
- mountPath: /src
name: hello-deps
volumes:
- emptyDir: {}
name: hello
- configMap:
defaultMode: 420
name: hello
...Init Container
Pod 中的 Init Container 主要作用如下:
- 將原始碼和依賴檔案拷貝到指定目錄;
- 安裝第三方依賴。
Func Container
Pod 中的 Func Container 會載入 Init Container 準備好的原始碼和依賴並執行函式。不同 runtime 載入程式碼的方式大同小異,可參考 kubeless.py,Handler.java。
小結
- Kubeless 通過綜合運用 K8s 中的多種元件以及利用各語言的動態載入能力實現了從使用者原始碼到可執行的函式的構建邏輯;
- 考慮了函式執行的安全性,通過 Security Context 機制限制容器中的程序以非 root 身份執行。
靈活觸發
一款成熟的 serverless 產品需要具備靈活觸發能力,以滿足事件源的多樣性需求,同時需要能夠方便快捷地接入新事件源。CNCF 將函式的觸發方式分成了如下圖所示的幾種類別,關於它們的詳細介紹可參考連結 Function Invocation Types。
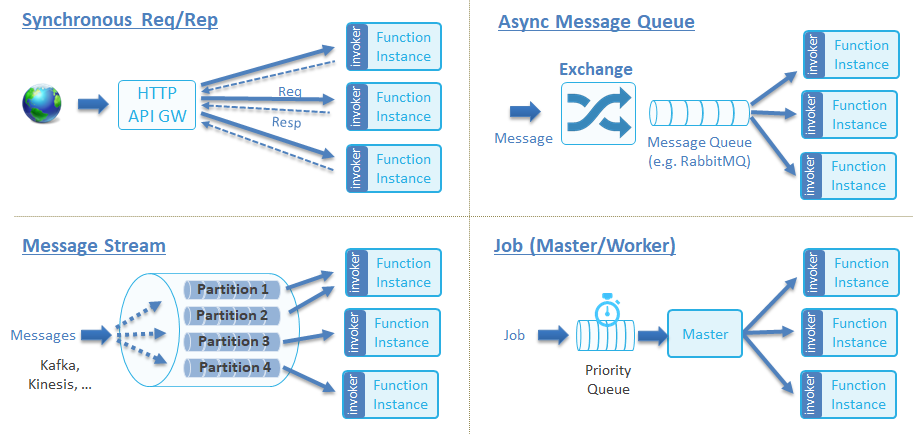
對於 kubeless 的函式,最簡單的觸發方式是使用 kubeless CLI,另外還支援通過各種觸發器。下表展示了 kubeless 函式目前支援的觸發方式以及它們所屬的類別。
| 觸發方式 | 類別 |
|---|---|
| kubeless CLI | Synchronous Req/Rep |
| Http Trigger | Synchronous Req/Rep |
| Cronjob Trigger | Job (Master/Worker) |
| Kafka Trigger | Async Message Queue |
| Nats Trigger | Async Message Queue |
| Kinesis Trigger | Message Stream |
下圖展示了 kubeless 函式部分觸發方式的原理:
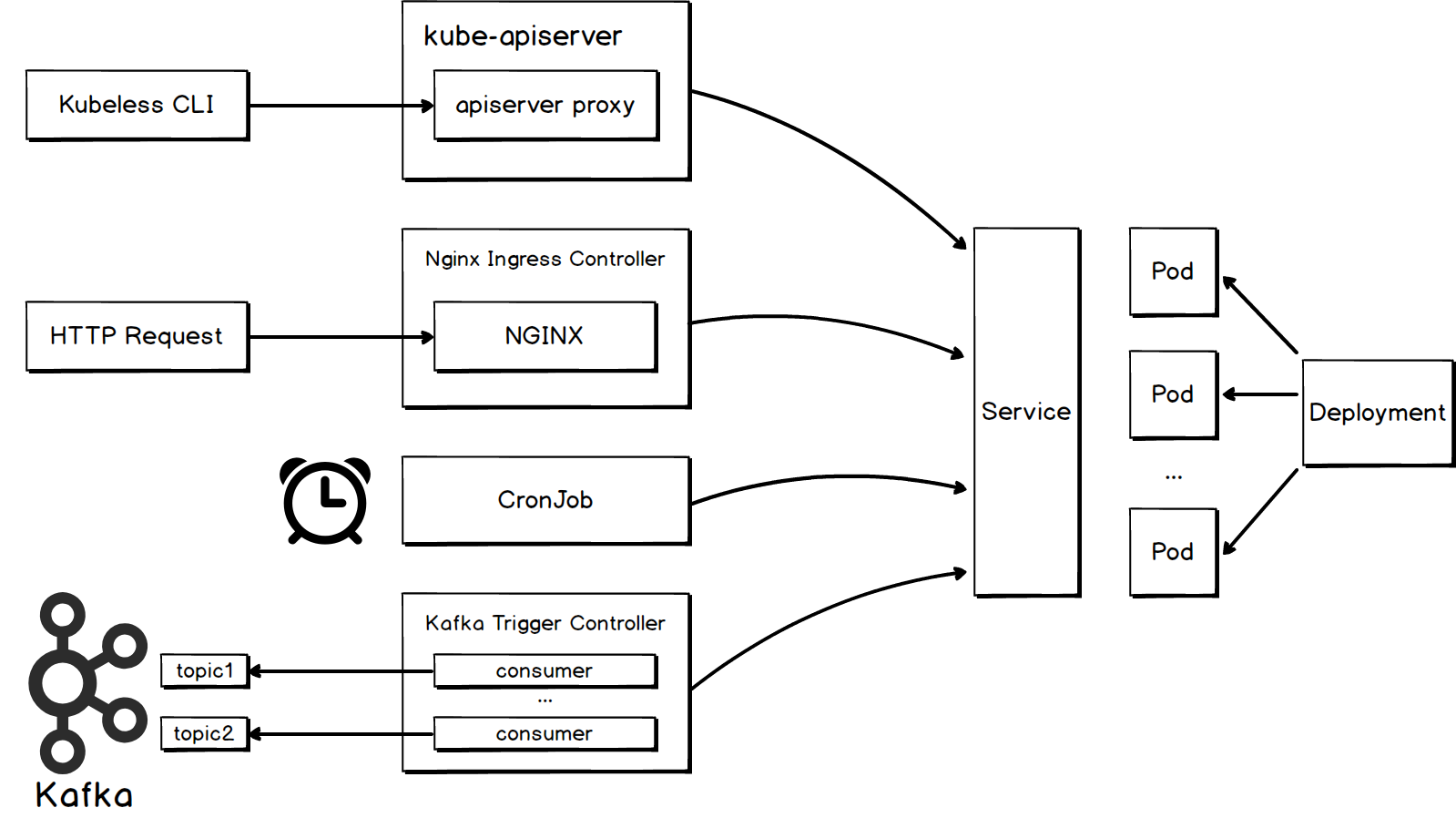
HTTP trigger
如果希望通過傳送 HTTP 請求觸發函式執行,需要為函式建立 HTTP 觸發器。 Kubeless 利用 K8s ingress 機制實現了 http trigger。Kubeless 建立了一個名為httptriggers.kubeless.io的 CRD 來代表 http trigger 物件。同時,kubeless 包含一個名為http-trigger-controller的 CRD controller,它會持續監聽針對 http trigger 和 function 的 ADD、UPDATE、DELETE 事件,並執行對應的操作。
以下命令將為函式 hello 建立一個名為http-hello的 http trigger,並指定選用 nginx 作為 gateway。
kubeless trigger http create http-hello --function-name hello --gateway nginx --path echo --hostname example.com該命令會建立如下 ingress 物件,可以參考 CreateIngress 深入瞭解 ingress 的建立邏輯。
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
# 該 Ingress 的名字,即建立 http trigger 時指定的 name
name: http-hello
...
spec:
rules:
- host: example.com
http:
paths:
- backend:
# 指向 kubeless 為函式 hello 建立的 ClusterIP 型別的 Service
serviceName: hello
servicePort: 8080
path: /echoIngress 只是用於描述路由規則,要讓規則生效、實現請求轉發,叢集中需要有一個正在執行的 ingress controller。可供選擇的 ingress controller 有 Contour、F5 BIG-IP Controller for Kubernetes、Kong Ingress Controllerfor Kubernetes、NGINX Ingress Controller for Kubernetes、Traefik 等。這種路由規則描述和路由功能實現相分離的思想很好地提現了 K8s 始終堅持的需求和供給分離的設計理念。
上文中的命令在建立 trigger 時指定了 nginx 作為 gateway,因此需要部署一個 nginx-ingress-controller。該 controller 的基本工作原理如下:
- 以 pod 的形式執行在獨立的名稱空間中;
- 以 hostPort 的形式暴露出來供外界訪問;
- 內部執行著一個 nginx 例項;
- 監聽和 ingress、service 等資源相關的事件。如果發現這些事件最終會影響到路由規則,ingress controller 會採用向 Lua hander 傳送新的 endpoints 列表或者直接修改 nginx.conf 並 reload nginx 等手段達到更新路由規則的目的。
想要更深入地瞭解 nginx-ingress-controller 的工作原理可參考文章 how-it-works。
完成上述工作後,我們便可以通過傳送 HTTP 請求觸發函式 hello 的執行:
- HTTP 請求首先會由 nginx-ingress-controller 中的 nginx 處理;
- Nginx 根據 nginx.conf 中的路由規則將請求轉發給函式對應的 service;
- 最後,請求會轉發至掛載在 service 後的某個函式進行處理。
樣例如下:
curl --data '{"Another": "Echo"}' \
--header "Host: example.com" \
--header "Content-Type:application/json" \
example.com/echo
# 函式返回
{"Another": "Echo"}Cronjob trigger
如果希望定期觸發函式執行,需要為函式建立 cronjob 觸發器。K8s 支援通過 CronJob 定期執行任務,kubeless 利用這個特性實現了 cronjob trigger。Kubeless 建立了一個名為cronjobtriggers.kubeless.io的 CRD 來代表 cronjob trigger 物件。同時,kubeless 包含一個名為cronjob-trigger-controller的 CRD controller,它會持續監聽針對 cronjob trigger 和 function 的 ADD、UPDATE、DELETE 事件,並執行對應的操作。
以下命令將為函式 hello 建立一個名為scheduled-invoke-hello的 cronjob trigger,該觸發器每分鐘會觸發函式 hello 執行一次。
kubeless trigger cronjob create scheduled-invoke-hello --function=hello --schedule="*/1 * * * *"該命令會建立如下 CronJob 物件,可以參考 EnsureCronJob 深入瞭解 CronJob 的建立邏輯。
apiVersion: batch/v1beta1
kind: CronJob
metadata:
# 該 CronJob 的名字,即建立 cronjob trigger 時指定的 name
name: scheduled-invoke-hello
...
spec:
# 該 CronJob 的執行計劃,即建立 cronjob trigger 時指定的 schedule
schedule: */1 * * * *
...
jobTemplate:
spec:
activeDeadlineSeconds: 180
template:
spec:
containers:
- args:
- curl
- -Lv
# HTTP headers,包含 event-id、event-time、event-type、event-namespace 等資訊
- ' -H "event-id: xxx" -H "event-time: yyy" -H "event-type: application/json" -H "event-namespace: cronjobtrigger.kubeless.io"'
# kubeless 會為 function 建立一個 ClusterIP 型別的 Service
# 可以根據 service 的 name、namespace 拼出 endpoint
- http://hello.default.svc.cluster.local:8080
image: kubeless/unzip
name: trigger
restartPolicy: Never
...自定義 trigger
如果發現 kubeless 預設提供的觸發器無法滿足業務需求,可以自定義新的觸發器。新觸發器的構建流程如下:
- 為新的事件源建立一個 CRD 來描述事件源觸發器;
- 在自定義資源物件的 spec 裡描述該事件源的屬性,例如 KafkaTriggerSpec、HTTPTriggerSpec;
-
為該 CRD 建立一個 CRD controller。
- 該 controller 需要持續監聽針對事件源觸發器和 function 的 CRUD 操作並作出正確的處理。例如,controller 監聽到 function 的刪除事件,需要把和該 function 關聯的觸發器一併刪掉;
- 當事件發生時,觸發關聯函式的執行。
我們可以看到,自定義 trigger 的流程遵循了 K8s Operator 設計模式。
小結
- Kubeless 提供了一些基本常用的觸發器,如果有其他事件源也可以通過自定義觸發器接入;
- 不同事件源的接入方式不同,但最終都是通過訪問函式 ClusterIP 型別的 service 觸發函式執行。
自動伸縮
K8s 通過 Horizontal Pod Autoscaler 實現 pod 的自動水平伸縮。Kubeless 的 function 通過 K8s deployment 部署執行,因此天然可以利用 HPA 實現自動伸縮。
度量資料獲取
自動伸縮的第一步是要讓 HPA 能夠獲取度量資料。目前,kubeless 中的函式支援基於 cpu 和 qps 這兩種指標進行自動伸縮。下圖展示了 HPA 獲取這兩種度量資料的途徑。
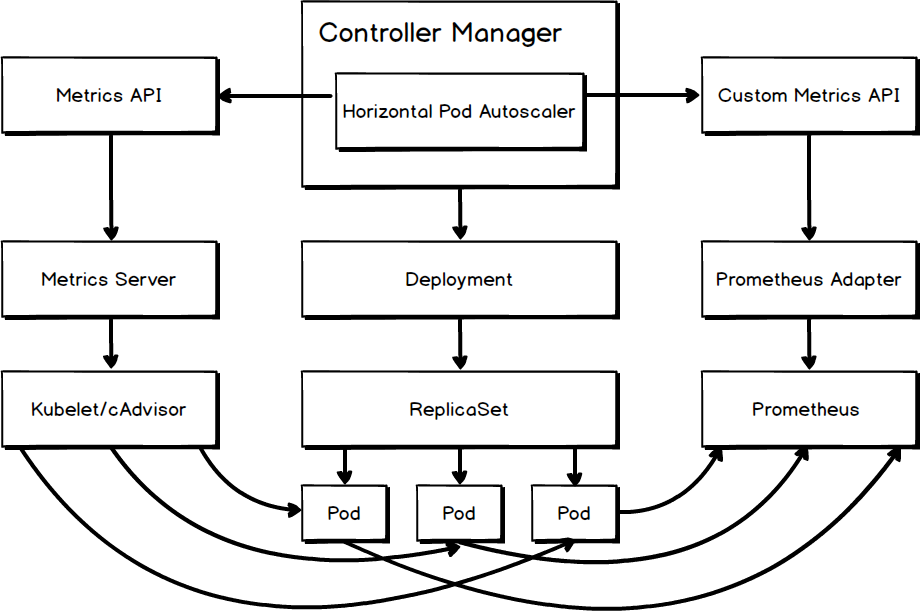
內建度量指標 cpu
CPU 使用率屬於內建度量指標,對於這類指標 HPA 可以通過 metrics API 從 Metrics Server 中獲取資料。Metrics Server 是 Heapster 的繼承者,它可以通過kubernetes.summary_api從 Kubelet、cAdvisor 中獲取度量資料。
自定義度量指標 qps
QPS 屬於自定義度量指標,想要獲取這類指標的度量資料需要完成下列步驟。
- 部署用於儲存度量資料的系統,這裡選擇已經被納入 CNCF 的 Prometheus。Prometheus 是一套開源監控&告警&時序資料解決方案,並且被 DigitalOcean、Red Hat、SUSE 和 Weaveworks 這些 cloud native 領導者廣泛使用;
- 採集度量資料,並寫入部署好的 Prometheus 中。Kubeless 提供的函式框架會在函式每次被呼叫時,將下列度量資料 function_duration_seconds、function_calls_total、function_failures_total 寫入 Prometheus(可參考 python 樣例)。
- 部署實現了 custom metrics API 的 custom API server。這裡,因為度量資料被存入了 Prometheus,因此選擇部署 k8s-prometheus-adapter,它可以從 Prometheus 中獲取度量資料。
完成上述步驟後,HPA 就可以通過 custom metrics API 從 Prometheus Adapter 中獲取 qps 度量資料。詳細配置步驟可參考文章 kubeless-autoscaling。
K8s 度量指標簡介
有時基於 cpu 和 qps 這兩種度量指標對函式進行自動伸縮還遠遠不夠。如果希望基於其它度量指標,需要了解 K8s 定義的度量指標型別及其獲取方式。
目前,K8s 1.13 版本支援的度量指標型別如下:
| 型別 | 簡介 | 獲取方式 |
|---|---|---|
| Object | 代表 k8s 物件的度量指標,例如上文提到的 Service 物件的 function_calls 指標。 | custom.metrics.k8s.io 度量資料採集後,需要通過已有介面卡或自己實現介面卡獲取資料。目前已有的介面卡包括 k8s-prometheus-adapter、azure-k8s-metrics-adapter、k8s-stackdriver等。 |
| Pod | 代表伸縮目標中每個 pod 的自定義度量指標,例如 pod 每秒處理的事務數。在與目標值比較前需要除以 pod 個數。 | 同上 |
| Resource | 代表伸縮目標中每個 pod 的 K8s 內建資源指標(如 CPU、Memory)。在與目標值比較前需要除以 pod 個數。 | metrics.k8s.io 從 Metrics Server 或 Heapster 中獲取度量資料。 |
| External | External 是一個全域性度量指標,它與任何 K8s 物件無關。它允許伸縮目標基於來自 cluster 外部的資訊進行伸縮(如外部負載均衡器的 QPS,雲訊息服務中的佇列長度)。 | external.metrics.k8s.io 度量資料採集後,需要雲平臺廠商提供介面卡或自己實現。目前已有的介面卡包括 azure-k8s-metrics-adapter、k8s-stackdriver等。 |
準備好相應的度量資料和獲取資料的元件,HPA 就能基於它們對函式進行自動伸縮。更多關於 K8s 度量指標的介紹可參考文章 hpa-external-metrics。
度量資料使用
知道了 HPA 獲取度量資料的途徑後,下面描述 HPA 如何基於這些資料對函式進行自動伸縮。
基於 cpu 使用率
假設已經存在一個名為 hello 的函式,以下命令將為該函式建立一個基於 cpu 使用率的 HPA,它將執行該函式的 pod 數量控制在 1 到 3 之間,並通過增加或減少 pod 個數使得所有 pod 的平均 cpu 使用率維持在 70%。
kubeless autoscale create hello --metric=cpu --min=1 --max=3 --value=70Kubeless 使用的是 autoscaling/v2alpha1 版本的 HPA API,該命令將要建立的 HPA 如下:
kind: HorizontalPodAutoscaler
apiVersion: autoscaling/v2alpha1
metadata:
name: hello
namespace: default
labels:
created-by: kubeless
function: hello
spec:
scaleTargetRef:
kind: Deployment
name: hello
minReplicas: 1
maxReplicas: 3
metrics:
- type: Resource
resource:
name: cpu
targetAverageUtilization: 70該 HPA 計算目標 pod 數量的公式如下:
TargetNumOfPods = ceil(sum(CurrentPodsCPUUtilization) / Target)基於 qps
以下命令將為函式 hello 建立一個基於 qps 的 HPA,它將執行該函式的 pod 數量控制在 1 到 5 之間,並通過增加或減少 pod 個數確保所有掛在服務 hello 後的 pod 每秒能處理的請求次數之和達到 2000。
kubeless autoscale create hello --metric=qps --min=1 --max=5 --value=2k該命令將要建立的 HPA 如下:
kind: HorizontalPodAutoscaler
apiVersion: autoscaling/v2alpha1
metadata:
name: hello
namespace: default
labels:
created-by: kubeless
function: hello
spec:
scaleTargetRef:
kind: Deployment
name: hello
minReplicas: 1
maxReplicas: 5
metrics:
- type: Object
object:
metricName: function_calls
target:
apiVersion: autoscaling/v2beta1
kind: Service
name: hello
targetValue: 2k基於多項指標
如果計劃基於多項度量指標對函式進行自動伸縮,需要直接為執行 function 的 deployment 建立 HPA。
使用如下 yaml 檔案可以為函式 hello 建立一個名為hello-cpu-and-memory的 HPA,它將執行該函式的 pod 數量控制在 1 到 10 之間,並嘗試讓所有 pod 的平均 cpu 使用率維持在 50%,平均 memory 使用量維持在 200MB。對於多項度量指標,K8s 會計算出每項指標需要的 pod 數量,取其中的最大值作為最終的目標 pod 數量。
kind: HorizontalPodAutoscaler
apiVersion: autoscaling/v2alpha1
metadata:
name: hello-cpu-and-memory
namespace: default
labels:
created-by: kubeless
function: hello
spec:
scaleTargetRef:
kind: Deployment
name: hello
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
targetAverageUtilization: 50
- type: Resource
resource:
name: memory
targetAverageValue: 200Mi自動伸縮策略
一個理想的自動伸縮策略應當處理好下列場景:
- 當負載激增時,函式能迅速擴充套件以應對突發流量;
- 當負載下降時,函式能立即收縮以節省資源消耗;
- 具備抗噪聲干擾能力,能夠精確計算出目標容量;
- 能夠避免自動伸縮過於頻繁造成系統抖動。
Kubeless 依賴的 HPA 充分考慮了上述情形,不斷改進和完善其使用的自動伸縮策略。下面以 K8s 1.13 版本為例描述該策略。如果想要更加深入地瞭解策略原理請參考連結 horizontal。
HPA 每隔一段時間會根據獲取的度量資料同步一次和該 HPA 關聯的 RC / Deployment 中的 pod 個數,時間間隔通過 kube-controller-manager 的引數--horizontal-pod-autoscaler-sync-period指定,預設為 15s。在每一次同步過程中,HPA 需要經歷如下圖所示的計算流程。

計算目標副本數
分別計算 HPA 列表中每項指標需要的 pod 數量,記為 replicaCountProposal。選擇其中的最大值作為 metricDesiredReplicas。在計算每項指標的 replicaCountProposal 過程中會考慮下列因素:
- 允許目標度量值和實際度量值存在一定程度的誤差,如果在誤差範圍內直接使用 currentReplicas 作為 replicaCountProposal。這樣做是為了在可接受範圍內避免伸縮過於頻繁造成系統抖動,該誤差值可以通過 kube-controller-manager 的引數
--horizontal-pod-autoscaler-tolerance指定,預設值是 0.1。 - 當一個 pod 剛剛啟動時,該 pod 反映的度量值往往不是很準確,HPA 會將這種 pod 視為 unready。在計算度量值時,HPA 會跳過處於 unready 狀態的 pod。這樣做是為了消除噪聲干擾,可以通過 kube-controller-manager 的引數
--horizontal-pod-autoscaler-cpu-initialization-period(預設為 5 分鐘)和--horizontal-pod-autoscaler-initial-readiness-delay(預設為 30 秒)調整 pod 被認為處於 unready 狀態的時間。
平滑目標副本數
將最近一段時間計算出的 metricDesiredReplicas 記錄下來,取其中的最大值作為 stabilizedRecommendation。這樣做是為了讓縮容過程變得平滑,消除度量資料異常波動造成的影響。該時間段可以通過引數--horizontal-pod-autoscaler-downscale-stabilization-window指定,預設為 5 分鐘。
規範目標副本數
- 限制 desiredReplicas 最大為 currentReplicas * scaleUpLimitFactor,這樣做是為了防止因 採集到了“虛假的”度量資料造成擴容過快。目前 scaleUpLimitFactor 無法通過引數設定,其值固定為 2。
- 限制 desiredReplicas 大於等於 hpaMinReplicas,小於等於 hpaMaxReplicas。
執行擴容縮容操作
如果通過上述步驟計算出的 desiredReplicas 不等於 currentReplicas,則“執行”擴容縮容操作。這裡所說的執行只是將 desiredReplicas 賦值給 RC / Deployment 中的 replicas,pod 的建立銷燬會由 kube-scheduler 和 worker node 上的 kubelet 非同步完成的。
小結
- Kubeless 提供的自動伸縮功能是對 K8s HPA 的簡單封裝,避免了將建立 HPA 的複雜細節直接暴露給使用者。
- Kubeless 目前提供的度量指標過少,功能過於簡單。如果使用者希望基於新的度量指標、綜合多項度量指標或者調整自動伸縮的效果,需要深入瞭解 HPA 的細節。
- 目前 HPA 的擴容縮容策略是基於既成事實被動地調整目標副本數,還無法根據歷史規律預測性地進行擴容縮容。
總結
Kubeless 基於 K8s 提供了較為完整的 serverless 解決方案,但和一些商業 serverless 產品還存在一定差距:
- Kubeless 並未在映象拉取、程式碼下載、容器啟動等方面做過多優化,導致函式冷啟動時間過長;
- Kubeless 並未過多考慮多租戶的問題,如果希望多個使用者的函式執行在同一個叢集裡,還需要進行二次開發。