
pytorch系列13 ---優化演算法optim類
本文主要講解pytorch中的optim累以及lr_schdule類和optim優化器的配置,使用方法。
在https://blog.csdn.net/dss_dssssd/article/details/83892824中提及優化演算法的使用步驟,
-
optimer = optim.SGD()先初始化 -
反向傳播更新引數
- 將上次迭代計算的梯度值清0
optimizer.zero_grad() - 反向傳播,計算梯度值
loss.backward() - 更新權值引數
optimizer.step()
一. 使用optimizer的步驟
SGD原始碼: https://pytorch.org/docs/stable/_modules/torch/optim/sgd.html
- 將上次迭代計算的梯度值清0
1. 構造optimizer
1.1 初始化函式__init__:

引數:
-
params: 包含引數的可迭代物件,必須為Tensor
-
其餘的引數來配置學習過程中的行為
optimizer = optim.SGD(model.parameters(), lr = 0.01, momentum=0.9)
optimizer = optim.Adam([var1, var2], lr = 0.0001)
1.2. per-parameter 選擇
不是傳入Tensor的可迭代物件,而是傳入
dict的可迭代物件,每一個字典定義一個獨立的引數組,每一個dict必須包含一個params鍵,和一系列與該優化函式對應的引數。
optim.SGD([
{'params': model.base.parameters()},
{'params': model.classifier.parameters(), 'lr': 1e-3}
], lr=1e-2, momentum=0.9)
上述程式碼,model.base中的引數更新使用learning rate
1e-2的SGD演算法,而model.classifier中的引數更新使用learning rate 為 1e-2, momentum為0.9的SGD演算法
下面用一個兩層的線性迴歸的例子說明一下:
輸入為[11, 1], 第一層為[1, 10], 第二層為[10, 1],最後的輸出為[11,1]。在優化演算法中,第一層和第二層分別使用不同的優化器配置方案。
class model_(nn.Module):
def __init__(self, in_dim):
super().__init__()
self.first_layer = nn.Sequential(
nn.Linear(in_dim, 10)
)
self.second_layer = nn.Sequential(
nn.Linear(10, 1)
)
def forward(self, x):
x = F.Relu(self.first_layer(x))
x = self.second_layer(x)
return x
x = np.arange(1, 11).reshape(-1, 1)
x = torch.from_numpy(x)
model =model_(1)
使用parameters()打印出weight和bias,注意函式返回的是迭代器
print("the first params:")
# 返回的是迭代器
for param in model.first_layer.parameters():
print(param)
print("the second params:")
print(list(model.second_layer.parameters()))
out:
the first params:
Parameter containing:
tensor([[ 0.7895],
[ 0.4697],
[-0.0534],
[ 0.8223],
[ 0.9414],
[-0.5877],
[-0.4069],
[-0.6598],
[-0.1982],
[-0.2233]], requires_grad=True)
Parameter containing:
tensor([-0.9338, -0.9721, 0.3418, -0.4599, 0.1251, -0.2313, 0.9735, -0.1804,
0.0935, 0.9205], requires_grad=True)
the second params:
[Parameter containing:
tensor([[-0.0765, -0.1632, 0.0979, 0.2206, -0.0102, -0.0452, -0.3096, 0.0189,
-0.0240, -0.0900]], requires_grad=True), Parameter containing:
tensor([-0.1148], requires_grad=True)]
在接收了外部輸入的引數params以後,優化器會把params存在self.param_groups裡(是一個字典的列表)。每一個字典除了儲存引數的[‘params’]鍵以外,Optimizer還維護著其他的優化係數,例如學習率和衰減率等
optimizer = optim.SGD(
[
{'params': model.first_layer.parameters()},
{'params': model.second_layer.parameters(), 'lr': 1e-3}
],
lr=1e-2, momentum=0.9)
print(optimizer.param_groups)
out:
[{‘params’: [Parameter containing:
tensor([[ 0.7895],
[ 0.4697],
[-0.0534],
[ 0.8223],
[ 0.9414],
[-0.5877],
[-0.4069],
[-0.6598],
[-0.1982],
[-0.2233]], requires_grad=True), Parameter containing:
tensor([-0.9338, -0.9721, 0.3418, -0.4599, 0.1251, -0.2313, 0.9735, -0.1804,
0.0935, 0.9205], requires_grad=True)], ‘lr’: 0.01, ‘momentum’: 0.9, ‘dampening’: 0, ‘weight_decay’: 0, ‘nesterov’: False},
{‘params’: [Parameter containing:
tensor([[-0.0765, -0.1632, 0.0979, 0.2206, -0.0102, -0.0452, -0.3096, 0.0189,
-0.0240, -0.0900]], requires_grad=True), Parameter containing:
tensor([-0.1148], requires_grad=True)], ‘lr’: 0.001, ‘momentum’: 0.9, ‘dampening’: 0, ‘weight_decay’: 0, ‘nesterov’: False}]
2. optimizer.zero_grade()
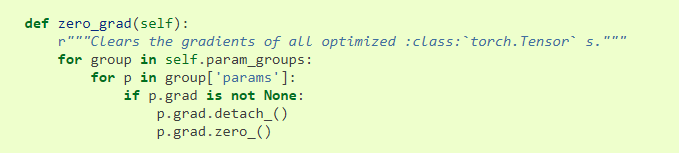
在所有的優化演算法的基類Optimizerhttps://pytorch.org/docs/stable/_modules/torch/optim/optimizer.html中的zero_grad函式對self.param_group中的所有的params清零
3. loss.backward()
4. optimizer.step()
4.1. 直接呼叫step()而不傳入closure引數,大多數優化演算法會用這種方法呼叫ok,因為只涉及到一次呼叫
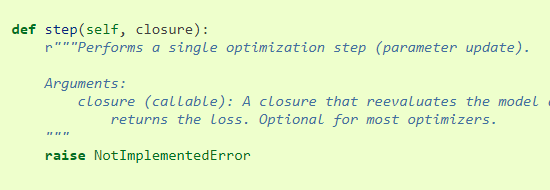
這個方法在Optimizer中是未定義,根據具體的優化器來單獨實現。
以下通過SGD類中的step()函式來說明:
def step(self, closure=None):
"""Performs a single optimization step.
Arguments:
closure (callable, optional): A closure that reevaluates the model
and returns the loss.
"""
loss = None
if closure is not None:
loss = closure()
for group in self.param_groups:
weight_decay = group['weight_decay']
momentum = group['momentum']
dampening = group['dampening']
nesterov = group['nesterov']
for p in group['params']:
if p.grad is None:
continue
d_p = p.grad.data
if weight_decay != 0:
d_p.add_(weight_decay, p.data)
if momentum != 0:
param_state = self.state[p]
if 'momentum_buffer' not in param_state:
buf = param_state['momentum_buffer'] = torch.zeros_like(p.data)
buf.mul_(momentum).add_(d_p)
else:
buf = param_state['momentum_buffer']
buf.mul_(momentum).add_(1 - dampening, d_p)
if nesterov:
d_p = d_p.add(momentum, buf)
else:
d_p = buf
p.data.add_(-group['lr'], d_p)
return loss
取出每個group中的params進行更新,
d_p = p.grad.data將loss.backward()計算的梯度取出,通過weight_decay,momentum,learning_rate等優化器配置方法更新d_p的值,最後賦值給p。
4.2 對於Conjugate Gradient 和 LBFGS等優化演算法,須有多次評估優化函式,因而要傳入closure來多次計算模型。closure完成的操作:
- 清楚梯度值
- 計算損失loss
- 返回loss
for input, target in dataset:
def closure():
optimizer.zero_grad()
output = model(input)
loss = loss_fn(output, target)
loss.backward()
return loss
optimizer.step(closure)