
torch.optim優化演算法理解之optim.Adam()
torch.optim是一個實現了多種優化演算法的包,大多數通用的方法都已支援,提供了豐富的介面呼叫,未來更多精煉的優化演算法也將整合進來。
為了使用torch.optim,需先構造一個優化器物件Optimizer,用來儲存當前的狀態,並能夠根據計算得到的梯度來更新引數。
要構建一個優化器optimizer,你必須給它一個可進行迭代優化的包含了所有引數(所有的引數必須是變數s)的列表。 然後,您可以指定程式優化特定的選項,例如學習速率,權重衰減等。
optimizer = optim.SGD(model.parameters(), lr = 0.01, momentum=0.9)
optimizer = optim.Adam Optimizer還支援指定每個引數選項。 只需傳遞一個可迭代的dict來替換先前可迭代的Variable。dict中的每一項都可以定義為一個單獨的引數組,引數組用一個params鍵來包含屬於它的引數列表。其他鍵應該與優化器接受的關鍵字引數相匹配,才能用作此組的優化選項。
optim.SGD([
{'params' 如上,model.base.parameters()將使用1e-2的學習率,model.classifier.parameters()將使用1e-3的學習率。0.9的momentum作用於所有的parameters。
優化步驟:
所有的優化器Optimizer都實現了step()方法來對所有的引數進行更新,它有兩種呼叫方法:
optimizer.step()這是大多數優化器都支援的簡化版本,使用如下的backward()方法來計算梯度的時候會呼叫它。
for input, target in dataset:
optimizer.zero_grad()
output = model(input)
loss = loss_fn(output, target)
loss.backward()
optimizer.step()optimizer.step(closure)一些優化演算法,如共軛梯度和LBFGS需要重新評估目標函式多次,所以你必須傳遞一個closure以重新計算模型。 closure必須清除梯度,計算並返回損失。
for input, target in dataset:
def closure():
optimizer.zero_grad()
output = model(input)
loss = loss_fn(output, target)
loss.backward()
return loss
optimizer.step(closure)Adam演算法:
Adam(Adaptive Moment Estimation)本質上是帶有動量項的RMSprop,它利用梯度的一階矩估計和二階矩估計動態調整每個引數的學習率。它的優點主要在於經過偏置校正後,每一次迭代學習率都有個確定範圍,使得引數比較平穩。其公式如下:
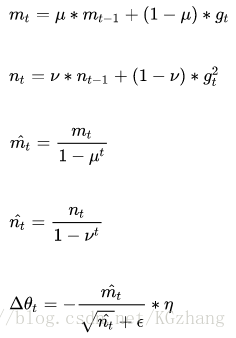
其中,前兩個公式分別是對梯度的一階矩估計和二階矩估計,可以看作是對期望E|gt|,E|gt^2|的估計;
公式3,4是對一階二階矩估計的校正,這樣可以近似為對期望的無偏估計。可以看出,直接對梯度的矩估計對記憶體沒有額外的要求,而且可以根據梯度進行動態調整。最後一項前面部分是對學習率n形成的一個動態約束,而且有明確的範圍。
class torch.optim.Adam(params, lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0)引數:
params(iterable):可用於迭代優化的引數或者定義引數組的dicts。
lr (float, optional) :學習率(預設: 1e-3)
betas (Tuple[float, float], optional):用於計算梯度的平均和平方的係數(預設: (0.9, 0.999))
eps (float, optional):為了提高數值穩定性而新增到分母的一個項(預設: 1e-8)
weight_decay (float, optional):權重衰減(如L2懲罰)(預設: 0)step(closure=None)函式:執行單一的優化步驟
closure (callable, optional):用於重新評估模型並返回損失的一個閉包 torch.optim.adam原始碼:
import math
from .optimizer import Optimizer
class Adam(Optimizer):
def __init__(self, params, lr=1e-3, betas=(0.9, 0.999), eps=1e-8,weight_decay=0):
defaults = dict(lr=lr, betas=betas, eps=eps,weight_decay=weight_decay)
super(Adam, self).__init__(params, defaults)
def step(self, closure=None):
loss = None
if closure is not None:
loss = closure()
for group in self.param_groups:
for p in group['params']:
if p.grad is None:
continue
grad = p.grad.data
state = self.state[p]
# State initialization
if len(state) == 0:
state['step'] = 0
# Exponential moving average of gradient values
state['exp_avg'] = grad.new().resize_as_(grad).zero_()
# Exponential moving average of squared gradient values
state['exp_avg_sq'] = grad.new().resize_as_(grad).zero_()
exp_avg, exp_avg_sq = state['exp_avg'], state['exp_avg_sq']
beta1, beta2 = group['betas']
state['step'] += 1
if group['weight_decay'] != 0:
grad = grad.add(group['weight_decay'], p.data)
# Decay the first and second moment running average coefficient
exp_avg.mul_(beta1).add_(1 - beta1, grad)
exp_avg_sq.mul_(beta2).addcmul_(1 - beta2, grad, grad)
denom = exp_avg_sq.sqrt().add_(group['eps'])
bias_correction1 = 1 - beta1 ** state['step']
bias_correction2 = 1 - beta2 ** state['step']
step_size = group['lr'] * math.sqrt(bias_correction2) / bias_correction1
p.data.addcdiv_(-step_size, exp_avg, denom)
return lossAdam的特點有:
1、結合了Adagrad善於處理稀疏梯度和RMSprop善於處理非平穩目標的優點;
2、對記憶體需求較小;
3、為不同的引數計算不同的自適應學習率;
4、也適用於大多非凸優化-適用於大資料集和高維空間。