
深入理解PHP Opcode快取原理
什麼是opcode快取?
當直譯器完成對指令碼程式碼的分析後,便將它們生成可以直接執行的中間程式碼,也稱為操作碼
(Operate Code,opcode)。Opcode cache的目地是避免重複編譯,減少CPU和記憶體開銷。
如果動態內容的效能瓶頸不在於CPU和記憶體,而在於I/O操作,比如資料庫查詢帶來的磁碟I/O開銷,
那麼opcode cache的效能提升是非常有限的。但是既然opcode cache能帶來CPU和記憶體開銷的降低,
這總歸是好事。現代操作碼快取器(Optimizer+,APC2.0+,其他)使用共享記憶體進行儲存,並且可以
直接從中執行檔案,而不用在執行前“反序列化”程式碼。
這將帶來顯著的效能加速,通常降低了整體伺服器的記憶體消耗,而且很少有缺點。
為什麼要使用Opcode快取?
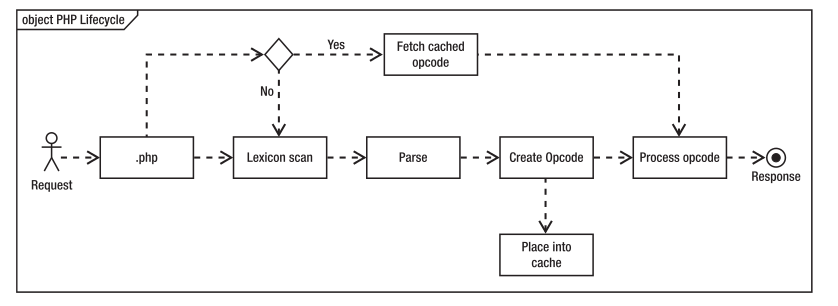
這得從PHP程式碼的生命週期說起,請求PHP指令碼時,會經過五個步驟,如下圖所示:

Zend引擎必須從檔案系統讀取檔案、掃描其詞典和表示式、解析檔案、建立要執行的計算機程式碼(稱為Opcode),
最後執行Opcode。每一次請求PHP指令碼都會執行一遍以上步驟,如果PHP原始碼沒有變化,那麼Opcode也不會
變化,顯然沒有必要每次都重行生成Opcode,結合在Web中無所不在的快取機制,我們可以把Opcode快取下來,
以後直接訪問快取的Opcode豈不是更快,啟用Opcode快取之後的流程圖如下所示:
有那些PHP opcode快取外掛?
Optimizer+(Optimizer+於2013年3月中旬改名為Opcache,PHP 5.5整合Opcache,其他的會不會消失?)、
eAccelerator、xcache、APC …
PHP opcode原理:
Opcode是一種PHP指令碼編譯後的中間語言,就像Java的ByteCode,或者.NET的MSL,舉個例子,比如你寫下了
如下的PHP程式碼:
-
<?php -
echo "Hello World"; -
$a = 1 + 1; -
echo $a; -
?>
PHP執行這段程式碼會經過如下4個步驟(確切的來說,應該是PHP的語言引擎Zend)
1.Scanning(Lexing) ,將PHP程式碼轉換為語言片段(Tokens) 2.Parsing, 將Tokens轉換成簡單而有意義的表示式 3.Compilation, 將表示式編譯成Opocdes 4.Execution, 順次執行Opcodes,每次一條,從而實現PHP指令碼的功能。
題外話:現在有的Cache比如APC,可以使得PHP快取住Opcodes,這樣,每次有請求來臨的時候,
就不需要重複執行前面3步,從而能大幅的提高PHP的執行速度。
那什麼是Lexing? 學過編譯原理的同學都應該對編譯原理中的詞法分析步驟有所瞭解,Lex就是一個
詞法分析的依據表。 Zend/zend_language_scanner.c會根據Zend/zend_language_scanner.l(Lex檔案),
來輸入的 PHP程式碼進行詞法分析,從而得到一個一個的“詞”,PHP4.2開始提供了一個函式叫token_get_all,
這個函式就可以講一段PHP程式碼 Scanning成Tokens;
如果用這個函式處理我們開頭提到的PHP程式碼,將會得到如下結果:
-
Array -
( -
[0] => Array -
( -
[0] => 367 -
[1] => Array -
( -
[0] => 316 -
[1] => echo -
) -
[2] => Array -
( -
[0] => 370 -
[1] => -
) -
[3] => Array -
( -
[0] => 315 -
[1] => "Hello World" -
) -
[4] => ; -
[5] => Array -
( -
[0] => 370 -
[1] => -
) -
[6] => = -
[7] => Array -
( -
[0] => 370 -
[1] => -
) -
[8] => Array -
( -
[0] => 305 -
[1] => 1 -
) -
[9] => Array -
( -
[0] => 370 -
[1] => -
) -
[10] => + -
[11] => Array -
( -
[0] => 370 -
[1] => -
) -
[12] => Array -
( -
[0] => 305 -
[1] => 1 -
) -
[13] => ; -
[14] => Array -
( -
[0] => 370 -
[1] => -
) -
[15] => Array -
( -
[0] => 316 -
[1] => echo -
) -
[16] => Array -
( -
[0] => 370 -
[1] => -
) -
[17] => ; -
)
分析這個返回結果我們可以發現,原始碼中的字串,字元,空格,都會原樣返回。每個原始碼中的
字元,都會出現在相應的順序處。而,其他的比如標籤,操作符,語句,都會被轉換成一個包含倆
部分的Array: Token ID (也就是在Zend內部的改Token的對應碼,比如,T_ECHO,T_STRING),和源
碼中的原來的內容。
接下來,就是Parsing階段了,Parsing首先會丟棄Tokens Array中的多於的空格,然後將剩餘的
Tokens轉換成一個一個的簡單的表示式
1.echo a constant string 2.add two numbers together 3.store the result of the prior expression to a variable 4.echo a variable
然後就改Compilation階段了,它會把Tokens編譯成一個個op_array, 每個op_arrayd包含如下5個部分:
1.Opcode數字的標識,指明瞭每個op_array的操作型別,比如add , echo 2.結果 存放Opcode結果 3.運算元1 給Opcode的運算元 4.運算元2 5.擴充套件值1個整形用來區別被過載的操作符
比如,我們的PHP程式碼會被Parsing成:
* ZEND_ECHO 'Hello World' * ZEND_ADD ~0 1 1 * ZEND_ASSIGN !0 ~0 * ZEND_ECHO !0
你可能會問了,我們的$a去那裡了?
這個要介紹操作數了,每個運算元都是由以下倆個部分組成:
a)op_type : 為IS_CONST, IS_TMP_VAR, IS_VAR, IS_UNUSED, or IS_CV b)u,一個聯合體,根據op_type的不同,分別用不同的型別儲存了這個運算元的值(const)或者左值(var)
而對於var來說,每個var也不一樣
IS_TMP_VAR, 顧名思義,這個是一個臨時變數,儲存一些op_array的結果,以便接下來的op_array使用,
這種的運算元的u儲存著一個指向變量表的一個控制代碼(整數),這種運算元一般用~開頭,比如~0,表示變
量表的0號未知的臨時變數
IS_VAR 這種就是我們一般意義上的變量了,他們以$開頭表示
IS_CV 表示ZE2.1/PHP5.1以後的編譯器使用的一種cache機制,這種變數儲存著被它引用的變數的地址,
當一個變數第一次被引用的時候,就會被CV起來,以後對這個變數的引用就不需要再次去查詢active符號
表了,CV變數以!開頭表示。
這麼看來,我們的$a被優化成!0了。