
偏度與峰度(附python程式碼)
1 矩
- 對於隨機變數X,X的K階原點矩為
![]()
- X的K階中心矩為
![]()
- 期望實際上是隨機變數X的1階原點矩,方差實際上是隨機變數X的2階中心矩
- 變異係數(Coefficient of Variation):標準差與均值(期望)的比值稱為變異係數,記為C.V
- 偏度Skewness(三階)
- 峰度Kurtosis(四階)
2 偏度與峰度



3 利用matplotlib模擬偏度和峰度
3.1計算期望和方差
import matplotlib.pyplot as plt import math import numpy as np def calc(data): n=len(data) # 10000個數 niu=0.0 # niu表示平均值,即期望. niu2=0.0 # niu2表示平方的平均值 niu3=0.0 # niu3表示三次方的平均值 for a in data: niu += a niu2 += a**2 niu3 += a**3 niu /= n niu2 /= n niu3 /= n sigma = math.sqrt(niu2 - niu*niu) return [niu,sigma,niu3]
其中,
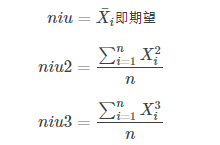
![]()
3.2 計算偏度和峰度
def calc_stat(data): [niu, sigma, niu3]=calc(data) n=len(data) niu4=0.0 # niu4計算峰度計算公式的分子 for a in data: a -= niu niu4 += a**4 niu4 /= n skew =(niu3 -3*niu*sigma**2-niu**3)/(sigma**3) # 偏度計算公式 kurt=niu4/(sigma**4) # 峰度計算公式:下方為方差的平方即為標準差的四次方 return [niu, sigma,skew,kurt]
3.3 利用matplotlib模擬影象
if __name__ == "__main__": data = list(np.random.randn(10000)) # 滿足高斯分佈的10000個數 data2 = list(2*np.random.randn(10000)) # 將滿足好高斯分佈的10000個數乘以兩倍,方差變成四倍 [niu, sigma, skew, kurt] = calc_stat(data) [niu_2, sigma2, skew2, kurt2] = calc_stat(data2) print (niu, sigma, skew, kurt) print (niu_2, sigma2, skew2, kurt2) info = r'$\mu=%.2f,\ \sigma=%.2f,\ skew=%.2f,\ kurt=%.2f$' %(niu,sigma, skew, kurt) # 標註 info2 = r'$\mu=%.2f,\ \sigma=%.2f,\ skew=%.2f,\ kurt=%.2f$' %(niu_2,sigma2, skew2, kurt2) plt.figure(figsize=(10,10)) plt.text(1,0.38,info,bbox=dict(facecolor='red',alpha=0.25)) plt.text(1,0.35,info2,bbox=dict(facecolor='green',alpha=0.25)) plt.hist(data,100,normed=True,facecolor='r',alpha=0.9) plt.hist(data2,100,normed=True,facecolor='g',alpha=0.8) plt.grid(True) plt.show()
得到的影象如下

4 python中已實現的方法
當然,python中也有已經封裝好的方法可以直接呼叫。
>>import pandas as pd
>>import numpy as np
>>data = list(np.random.randn(10000))
>>print(pd.Series(data).skew())
>>print(pd.Series(data).kurt())
0.008183135640179836
0.0054282536088923194使用seaborn可以畫出更加美觀的圖,
import numpy as np
from scipy.stats import norm
from matplotlib import pyplot as plt
import seaborn as sns
data = list(np.random.randn(10000)) # 滿足高斯分佈的10000個數
sns.distplot(data, fit=norm)
(mu, sigma) = norm.fit(data)
print( '\n mu = {:.2f} and sigma = {:.2f}\n'.format(mu, sigma))
plt.legend(['Normal dist. ($\mu=$ {:.2f} and $\sigma=$ {:.2f} )'.format(mu, sigma)],loc='best')
plt.ylabel('Frequency')
plt.title('Distribution')
5 總結
偏度這一指標,又稱偏斜係數、偏態係數,是用來幫助判斷資料序列的分佈規律性的指標。
在資料序列呈對稱分佈(正態分佈)的狀態下,其均值、中位數和眾數重合。且在這三個數的兩側,其它所有的資料完全以對稱的方式左右分佈。
如果資料序列的分佈不對稱,則均值、中位數和眾數必定分處不同的位置。這時,若以均值為參照點,則要麼位於均值左側的資料較多,稱之為右偏;要麼位於均值右側的資料較多,稱之為左偏;除此無它。
考慮到所有資料與均值之間的離差之和應為零這一約束,則當均值左側資料較多的時候,均值的右側必定存在數值較大的“離群”資料;同理,當均值右側資料較多的時候,均值的左側必定存在數值較小的“離群”資料。
一般將偏度定義為三階中心矩與標準差的三次冪之比。
在上述定義下,偏度係數的取值無非三種情景:
1.當資料序列呈正態分佈的時候,由於均值兩側的資料完全對稱分佈,其三階中心矩必定為零,於是滿足正態分佈的資料序列的偏度係數必定等於零。
2.當資料序列非對稱分佈的時候,如果均值的左側資料較多,則其右側的“離群”資料對三階中心矩的計算結果影響至巨,乃至於三階中心矩取正值。因此,當資料的分佈呈右偏的時候,其偏度係數將大於零。
3.當資料序列非對稱分佈的時候,如果均值的右側資料較多,則其左側的“離群”資料對三階中心矩的計算結果影響至巨,乃至於三階中心矩取負值。因此,當資料的分佈呈左偏的時候,偏度係數將小於零。
在右偏的分佈中,由於大部分資料都在均值的左側,且均值的右側存在“離群”資料,這就使得分佈曲線的右側出現一個長長的拖尾;而在左偏的分佈中,由於大部分資料都在均值的右側,且均值的左側存在“離群”資料,從而造成分佈曲線的左側出現一個長長的拖尾。
可見,在偏度係數的絕對值較大的時候,最有可能的含義是“離群”資料離群的程度很高(很大或很小),亦即分佈曲線某側的拖尾很長。
但“拖尾很長”與“分佈曲線很偏斜”不完全等價。例如,也不能排除在資料較少的那一側,只是多數資料的離差相對於另一側較大,但不存在明顯“離群”資料的情景。所以,為準確判斷分佈函式的偏斜程度,最好的辦法是直接觀察分佈曲線的幾何圖形。
與偏度(係數)一樣,峰度(係數)也是一個用於評價資料系列分佈特徵的指標。根據這兩個指標,我們可以判斷資料系列的分佈是否滿足正態性,進而評價平均數指標的使用價值。一般地,對於一個偏態分佈、肥尾分佈特徵很明顯的資料序列來說,平均數這個指標極易令人誤解資料序列分佈的集中位置及其集中程度,故此使用起來要極其謹慎。
峰度(係數)等於資料序列的四階中心矩與標準差的四次冪之比。設若先將資料標準化,則峰度(係數)相當於標準化資料序列的四階中心矩。
顯然,一個數據距離均值越遠,其對四階中心矩計算結果的影響越大。是故,峰度(係數)是一個用於衡量離群資料離群度的指標。峰度(係數)越大,說明該資料系列中的極端值越多。這在資料序列的分佈曲線圖中來看,體現為存在明顯的“肥尾”。當然,峰度(係數)較大也可能說明離群資料取值的極端性很嚴重,或者各資料距離均值的距離普遍較遠。可見,峰度(係數)的大小到底能說明什麼問題,最好還是看圖確定。
根據Jensen不等式,可以確定出峰度(係數)的取值範圍:它的下限不會低於1,上限不會高於資料的個數。
有一些典型分佈的峰度(係數)值得特別關注。例如,正態分佈的峰度(係數)為常數3,均勻分佈的峰度(係數)為常數1.6。在統計實踐中,我們經常把這兩個典型的分佈曲線作為評價樣本資料序列分佈性態的參照。