
XGBoost引數調優完全指南(附Python程式碼)
1. 簡介
如果你的預測模型表現得有些不盡如人意,那就用XGBoost吧。XGBoost演算法現在已經成為很多資料工程師的重要武器。它是一種十分精緻的演算法,可以處理各種不規則的資料。
構造一個使用XGBoost的模型十分簡單。但是,提高這個模型的表現就有些困難(至少我覺得十分糾結)。這個演算法使用了好幾個引數。所以為了提高模型的表現,引數的調整十分必要。在解決實際問題的時候,有些問題是很難回答的——你需要調整哪些引數?這些引數要調到什麼值,才能達到理想的輸出?
這篇文章最適合剛剛接觸XGBoost的人閱讀。在這篇文章中,我們會學到引數調優的技巧,以及XGboost相關的一些有用的知識。以及,我們會用Python在一個數據集上實踐一下這個演算法。
2. 你需要知道的
XGBoost(eXtreme Gradient Boosting)是Gradient Boosting演算法的一個優化的版本。因為我在前一篇文章,基於Python的Gradient Boosting演算法引數調整完全指南,裡面已經涵蓋了Gradient Boosting演算法的很多細節了。我強烈建議大家在讀本篇文章之前,把那篇文章好好讀一遍。它會幫助你對Boosting演算法有一個巨集觀的理解,同時也會對GBM的引數調整有更好的體會。
特別鳴謝:我個人十分感謝Mr Sudalai Rajkumar (aka SRK)大神的支援,目前他在AV Rank中位列第二。如果沒有他的幫助,就沒有這篇文章。在他的幫助下,我們才能給無數的資料科學家指點迷津。給他一個大大的贊!
3. 內容列表
1、XGBoost的優勢
2、理解XGBoost的引數
3、調參示例
4. XGBoost的優勢
XGBoost演算法可以給預測模型帶來能力的提升。當我對它的表現有更多瞭解的時候,當我對它的高準確率背後的原理有更多瞭解的時候,我發現它具有很多優勢:
4.1 正則化
- 標準GBM的實現沒有像XGBoost這樣的正則化步驟。正則化對減少過擬合也是有幫助的。
- 實際上,XGBoost以“正則化提升(regularized boosting)”技術而聞名。
4.2 並行處理
- XGBoost可以實現並行處理,相比GBM有了速度的飛躍。
- 不過,眾所周知,Boosting演算法是順序處理的,它怎麼可能並行呢?每一課樹的構造都依賴於前一棵樹,那具體是什麼讓我們能用多核處理器去構造一個樹呢?我希望你理解了這句話的意思。如果你希望瞭解更多,點選這個連結。
- XGBoost 也支援Hadoop實現。
4.3 高度的靈活性
- XGBoost 允許使用者定義自定義優化目標和評價標準
- 它對模型增加了一個全新的維度,所以我們的處理不會受到任何限制。
4.4 缺失值處理
- XGBoost內建處理缺失值的規則。
- 使用者需要提供一個和其它樣本不同的值,然後把它作為一個引數傳進去,以此來作為缺失值的取值。XGBoost在不同節點遇到缺失值時採用不同的處理方法,並且會學習未來遇到缺失值時的處理方法。
4.5 剪枝
- 當分裂時遇到一個負損失時,GBM會停止分裂。因此GBM實際上是一個貪心演算法。
- XGBoost會一直分裂到指定的最大深度(max_depth),然後回過頭來剪枝。如果某個節點之後不再有正值,它會去除這個分裂。
- 這種做法的優點,當一個負損失(如-2)後面有個正損失(如+10)的時候,就顯現出來了。GBM會在-2處停下來,因為它遇到了一個負值。但是XGBoost會繼續分裂,然後發現這兩個分裂綜合起來會得到+8,因此會保留這兩個分裂。
4.6 內建交叉驗證
- XGBoost允許在每一輪boosting迭代中使用交叉驗證。因此,可以方便地獲得最優boosting迭代次數。
- 而GBM使用網格搜尋,只能檢測有限個值。
4.7、在已有的模型基礎上繼續
- XGBoost可以在上一輪的結果上繼續訓練。這個特性在某些特定的應用上是一個巨大的優勢。
- sklearn中的GBM的實現也有這個功能,兩種演算法在這一點上是一致的。
相信你已經對XGBoost強大的功能有了點概念。注意這是我自己總結出來的幾點,你如果有更多的想法,儘管在下面評論指出,我會更新這個列表的!
5. XGBoost的引數
XGBoost的作者把所有的引數分成了三類:
- 通用引數:巨集觀函式控制。
- Booster引數:控制每一步的booster(tree/regression)。
- 學習目標引數:控制訓練目標的表現。
在這裡我會類比GBM來講解,所以作為一種基礎知識,強烈推薦先閱讀這篇文章。
5.1 通用引數
這些引數用來控制XGBoost的巨集觀功能。
1、booster[預設gbtree]
- 選擇每次迭代的模型,有兩種選擇:
gbtree:基於樹的模型
gbliner:線性模型
2、silent[預設0]
- 當這個引數值為1時,靜默模式開啟,不會輸出任何資訊。
- 一般這個引數就保持預設的0,因為這樣能幫我們更好地理解模型。
3、nthread[預設值為最大可能的執行緒數]
- 這個引數用來進行多執行緒控制,應當輸入系統的核數。
- 如果你希望使用CPU全部的核,那就不要輸入這個引數,演算法會自動檢測它。
還有兩個引數,XGBoost會自動設定,目前你不用管它。接下來咱們一起看booster引數。
5.2 booster引數
儘管有兩種booster可供選擇,我這裡只介紹tree booster,因為它的表現遠遠勝過linear booster,所以linear booster很少用到。
1、eta[預設0.3]
- 和GBM中的 learning rate 引數類似。
- 通過減少每一步的權重,可以提高模型的魯棒性。
- 典型值為0.01-0.2。
2、min_child_weight[預設1]
- 決定最小葉子節點樣本權重和。
- 和GBM的 min_child_leaf 引數類似,但不完全一樣。XGBoost的這個引數是最小樣本權重的和,而GBM引數是最小樣本總數。
- 這個引數用於避免過擬合。當它的值較大時,可以避免模型學習到區域性的特殊樣本。
- 但是如果這個值過高,會導致欠擬合。這個引數需要使用CV來調整。
3、max_depth[預設6]
- 和GBM中的引數相同,這個值為樹的最大深度。
- 這個值也是用來避免過擬合的。max_depth越大,模型會學到更具體更區域性的樣本。
- 需要使用CV函式來進行調優。
- 典型值:3-10
4、max_leaf_nodes
- 樹上最大的節點或葉子的數量。
- 可以替代max_depth的作用。因為如果生成的是二叉樹,一個深度為n的樹最多生成n2個葉子。
- 如果定義了這個引數,GBM會忽略max_depth引數。
5、gamma[預設0]
- 在節點分裂時,只有分裂後損失函式的值下降了,才會分裂這個節點。Gamma指定了節點分裂所需的最小損失函式下降值。
- 這個引數的值越大,演算法越保守。這個引數的值和損失函式息息相關,所以是需要調整的。
6、max_delta_step[預設0]
- 這引數限制每棵樹權重改變的最大步長。如果這個引數的值為0,那就意味著沒有約束。如果它被賦予了某個正值,那麼它會讓這個演算法更加保守。
- 通常,這個引數不需要設定。但是當各類別的樣本十分不平衡時,它對邏輯迴歸是很有幫助的。
- 這個引數一般用不到,但是你可以挖掘出來它更多的用處。
7、subsample[預設1]
- 和GBM中的subsample引數一模一樣。這個引數控制對於每棵樹,隨機取樣的比例。
- 減小這個引數的值,演算法會更加保守,避免過擬合。但是,如果這個值設定得過小,它可能會導致欠擬合。
- 典型值:0.5-1
8、colsample_bytree[預設1]
- 和GBM裡面的max_features引數類似。用來控制每棵隨機取樣的列數的佔比(每一列是一個特徵)。
- 典型值:0.5-1
9、colsample_bylevel[預設1]
- 用來控制樹的每一級的每一次分裂,對列數的取樣的佔比。
- 我個人一般不太用這個引數,因為subsample引數和colsample_bytree引數可以起到相同的作用。但是如果感興趣,可以挖掘這個引數更多的用處。
10、lambda[預設1]
- 權重的L2正則化項。(和Ridge regression類似)。
- 這個引數是用來控制XGBoost的正則化部分的。雖然大部分資料科學家很少用到這個引數,但是這個引數在減少過擬合上還是可以挖掘出更多用處的。
11、alpha[預設1]
- 權重的L1正則化項。(和Lasso regression類似)。
- 可以應用在很高維度的情況下,使得演算法的速度更快。
12、scale_pos_weight[預設1]
- 在各類別樣本十分不平衡時,把這個引數設定為一個正值,可以使演算法更快收斂。
5.3學習目標引數
這個引數用來控制理想的優化目標和每一步結果的度量方法。
1、objective[預設reg:linear]
- 這個引數定義需要被最小化的損失函式。最常用的值有:
- binary:logistic 二分類的邏輯迴歸,返回預測的概率(不是類別)。
- multi:softmax 使用softmax的多分類器,返回預測的類別(不是概率)。
- 在這種情況下,你還需要多設一個引數:num_class(類別數目)。
- multi:softprob 和multi:softmax引數一樣,但是返回的是每個資料屬於各個類別的概率。
2、eval_metric[預設值取決於objective引數的取值]
- 對於有效資料的度量方法。
- 對於迴歸問題,預設值是rmse,對於分類問題,預設值是error。
- 典型值有:
- rmse 均方根誤差(∑Ni=1ϵ2N−−−−−−√)
- mae 平均絕對誤差(∑Ni=1|ϵ|N)
- logloss 負對數似然函式值
- error 二分類錯誤率(閾值為0.5)
- merror 多分類錯誤率
- mlogloss 多分類logloss損失函式
- auc 曲線下面積
3、seed(預設0)
- 隨機數的種子
- 設定它可以復現隨機資料的結果,也可以用於調整引數
如果你之前用的是Scikit-learn,你可能不太熟悉這些引數。但是有個好訊息,python的XGBoost模組有一個sklearn包,XGBClassifier。這個包中的引數是按sklearn風格命名的。會改變的函式名是:
1、eta -> learning_rate
2、lambda -> reg_lambda
3、alpha -> reg_alpha
你肯定在疑惑為啥咱們沒有介紹和GBM中的n_estimators類似的引數。XGBClassifier中確實有一個類似的引數,但是,是在標準XGBoost實現中呼叫擬合函式時,把它作為num_boosting_rounds引數傳入。
XGBoost Guide 的一些部分是我強烈推薦大家閱讀的,通過它可以對程式碼和引數有一個更好的瞭解:
6. 調參示例
我們從Data Hackathon 3.x AV版的hackathon中獲得資料集,和GBM
介紹文章中是一樣的。更多的細節可以參考competition page
資料集可以從這裡下載。我已經對這些資料進行了一些處理:
City變數,因為類別太多,所以刪掉了一些類別。DOB變數換算成年齡,並刪除了一些資料。- 增加了
EMI_Loan_Submitted_Missing變數。如果EMI_Loan_Submitted變數的資料缺失,則這個引數的值為1。否則為0。刪除了原先的EMI_Loan_Submitted變數。 EmployerName變數,因為類別太多,所以刪掉了一些類別。- 因為
Existing_EMI變數只有111個值缺失,所以缺失值補充為中位數0。 - 增加了
Interest_Rate_Missing變數。如果Interest_Rate變數的資料缺失,則這個引數的值為1。否則為0。刪除了原先的Interest_Rate變數。 - 刪除了
Lead_Creation_Date,從直覺上這個特徵就對最終結果沒什麼幫助。 Loan_Amount_Applied, Loan_Tenure_Applied兩個變數的缺項用中位數補足。- 增加了
Loan_Amount_Submitted_Missing變數。如果Loan_Amount_Submitted變數的資料缺失,則這個引數的值為1。否則為0。刪除了原先的Loan_Amount_Submitted變數。 - 增加了
Loan_Tenure_Submitted_Missing變數。如果Loan_Tenure_Submitted變數的資料缺失,則這個引數的值為1。否則為0。刪除了原先的Loan_Tenure_Submitted變數。 - 刪除了
LoggedIn,Salary_Account兩個變數 - 增加了
Processing_Fee_Missing變數。如果Processing_Fee變數的資料缺失,則這個引數的值為1。否則為0。刪除了原先的Processing_Fee變數。 Source前兩位不變,其它分成不同的類別。- 進行了離散化和獨熱編碼(一位有效編碼)。
如果你有原始資料,可以從資源庫裡面下載data_preparation的Ipython
notebook 檔案,然後自己過一遍這些步驟。
首先,import必要的庫,然後載入資料。
#Import libraries:
import pandas as pd
import numpy as np
import xgboost as xgb
from xgboost.sklearn import XGBClassifier
from sklearn import cross_validation, metrics #Additional scklearn functions
from sklearn.grid_search import GridSearchCV #Perforing grid search
import matplotlib.pylab as plt
%matplotlib inline
from matplotlib.pylab import rcParams
rcParams['figure.figsize'] = 12, 4
train = pd.read_csv('train_modified.csv')
target = 'Disbursed'
IDcol = 'ID'- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
注意我import了兩種XGBoost:
- xgb - 直接引用xgboost。接下來會用到其中的“cv”函式。
- XGBClassifier - 是xgboost的sklearn包。這個包允許我們像GBM一樣使用Grid Search 和並行處理。
在向下進行之前,我們先定義一個函式,它可以幫助我們建立XGBoost models 並進行交叉驗證。好訊息是你可以直接用下面的函式,以後再自己的models中也可以使用它。
def modelfit(alg, dtrain, predictors,useTrainCV=True, cv_folds=5, early_stopping_rounds=50):
if useTrainCV:
xgb_param = alg.get_xgb_params()
xgtrain = xgb.DMatrix(dtrain[predictors].values, label=dtrain[target].values)
cvresult = xgb.cv(xgb_param, xgtrain, num_boost_round=alg.get_params()['n_estimators'], nfold=cv_folds,
metrics='auc', early_stopping_rounds=early_stopping_rounds, show_progress=False)
alg.set_params(n_estimators=cvresult.shape[0])
#Fit the algorithm on the data
alg.fit(dtrain[predictors], dtrain['Disbursed'],eval_metric='auc')
#Predict training set:
dtrain_predictions = alg.predict(dtrain[predictors])
dtrain_predprob = alg.predict_proba(dtrain[predictors])[:,1]
#Print model report:
print "\nModel Report"
print "Accuracy : %.4g" % metrics.accuracy_score(dtrain['Disbursed'].values, dtrain_predictions)
print "AUC Score (Train): %f" % metrics.roc_auc_score(dtrain['Disbursed'], dtrain_predprob)
feat_imp = pd.Series(alg.booster().get_fscore()).sort_values(ascending=False)
feat_imp.plot(kind='bar', title='Feature Importances')
plt.ylabel('Feature Importance Score')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
這個函式和GBM中使用的有些許不同。不過本文章的重點是講解重要的概念,而不是寫程式碼。如果哪裡有不理解的地方,請在下面評論,不要有壓力。注意xgboost的sklearn包沒有“feature_importance”這個量度,但是get_fscore()函式有相同的功能。
6.1 引數調優的一般方法
我們會使用和GBM中相似的方法。需要進行如下步驟:
-
選擇較高的學習速率(learning rate)。一般情況下,學習速率的值為0.1。但是,對於不同的問題,理想的學習速率有時候會在0.05到0.3之間波動。選擇對應於此學習速率的理想決策樹數量。XGBoost有一個很有用的函式“cv”,這個函式可以在每一次迭代中使用交叉驗證,並返回理想的決策樹數量。
-
對於給定的學習速率和決策樹數量,進行決策樹特定引數調優(max_depth, min_child_weight, gamma, subsample, colsample_bytree)。在確定一棵樹的過程中,我們可以選擇不同的引數,待會兒我會舉例說明。
-
xgboost的正則化引數的調優。(lambda, alpha)。這些引數可以降低模型的複雜度,從而提高模型的表現。
-
降低學習速率,確定理想引數。
咱們一起詳細地一步步進行這些操作。
第一步:確定學習速率和tree_based 引數調優的估計器數目
為了確定boosting引數,我們要先給其它引數一個初始值。咱們先按如下方法取值:
1、max_depth = 5 :這個引數的取值最好在3-10之間。我選的起始值為5,但是你也可以選擇其它的值。起始值在4-6之間都是不錯的選擇。
2、min_child_weight = 1:在這裡選了一個比較小的值,因為這是一個極不平衡的分類問題。因此,某些葉子節點下的值會比較小。
3、gamma = 0: 起始值也可以選其它比較小的值,在0.1到0.2之間就可以。這個引數後繼也是要調整的。
4、subsample, colsample_bytree = 0.8: 這個是最常見的初始值了。典型值的範圍在0.5-0.9之間。
5、scale_pos_weight = 1: 這個值是因為類別十分不平衡。
注意哦,上面這些引數的值只是一個初始的估計值,後繼需要調優。這裡把學習速率就設成預設的0.1。然後用xgboost中的cv函式來確定最佳的決策樹數量。前文中的函式可以完成這個工作。
#Choose all predictors except target & IDcols
predictors = [x for x in train.columns if x not in [target,IDcol]]
xgb1 = XGBClassifier(
learning_rate =0.1,
n_estimators=1000,
max_depth=5,
min_child_weight=1,
gamma=0,
subsample=0.8,
colsample_bytree=0.8,
objective= 'binary:logistic',
nthread=4,
scale_pos_weight=1,
seed=27)
modelfit(xgb1, train, predictors)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
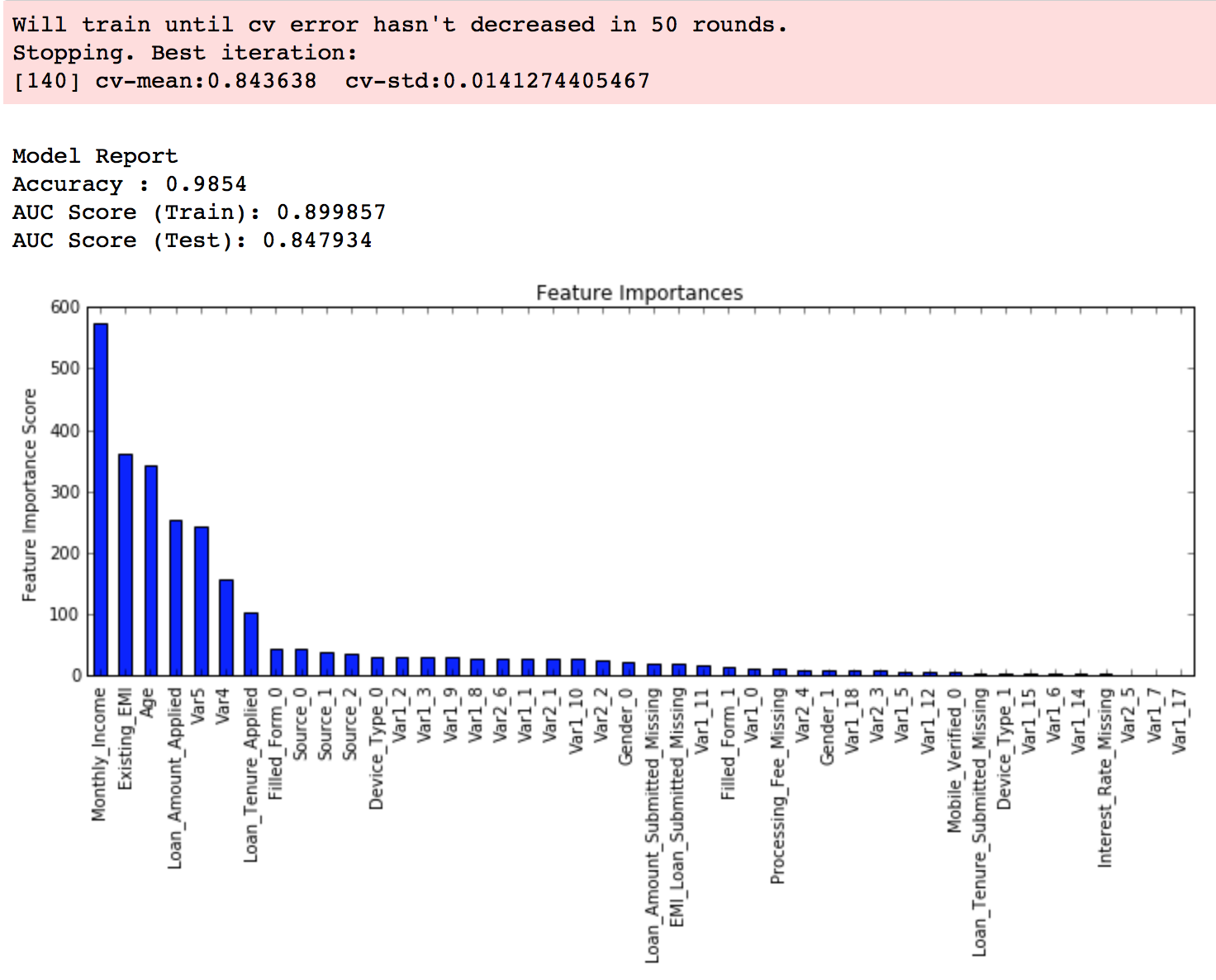
從輸出結果可以看出,在學習速率為0.1時,理想的決策樹數目是140。這個數字對你而言可能比較高,當然這也取決於你的系統的效能。
注意:在AUC(test)這裡你可以看到測試集的AUC值。但是如果你在自己的系統上執行這些命令,並不會出現這個值。因為資料並不公開。這裡提供的值僅供參考。生成這個值的程式碼部分已經被刪掉了。
第二步: max_depth 和 min_weight 引數調優
我們先對這兩個引數調優,是因為它們對最終結果有很大的影響。首先,我們先大範圍地粗調引數,然後再小範圍地微調。
注意:在這一節我會進行高負荷的柵格搜尋(grid search),這個過程大約需要15-30分鐘甚至更久,具體取決於你係統的效能。你也可以根據自己系統的效能選擇不同的值。
param_test1 = {
'max_depth':range(3,10,2),
'min_child_weight':range(1,6,2)
}
gsearch1 = GridSearchCV(estimator = XGBClassifier( learning_rate =0.1, n_estimators=140, max_depth=5,
min_child_weight=1, gamma=0, subsample=0.8, colsample_bytree=0.8,
objective= 'binary:logistic', nthread=4, scale_pos_weight=1, seed=27),
param_grid = param_test1, scoring='roc_auc',n_jobs=4,iid=False, cv=5)
gsearch1.fit(train[predictors],train[target])
gsearch1.grid_scores_, gsearch1.best_params_, gsearch1.best_score_- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10

至此,我們對於數值進行了較大跨度的12中不同的排列組合,可以看出理想的max_depth值為5,理想的min_child_weight值為5。在這個值附近我們可以再進一步調整,來找出理想值。我們把上下範圍各拓展1,因為之前我們進行組合的時候,引數調整的步長是2。
param_test2 = {
'max_depth':[4,5,6],
'min_child_weight':[4,5,6]
}
gsearch2 = GridSearchCV(estimator = XGBClassifier( learning_rate=0.1, n_estimators=140, max_depth=5,
min_child_weight=2, gamma=0, subsample=0.8, colsample_bytree=0.8,
objective= 'binary:logistic', nthread=4, scale_pos_weight=1,seed=27),
param_grid = param_test2, scoring='roc_auc',n_jobs=4,iid=False, cv=5)
gsearch2.fit(train[predictors],train[target])
gsearch2.grid_scores_, gsearch2.best_params_, gsearch2.best_score_- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10

至此,我們得到max_depth的理想取值為4,min_child_weight的理想取值為6。同時,我們還能看到cv的得分有了小小一點提高。需要注意的一點是,隨著模型表現的提升,進一步提升的難度是指數級上升的,尤其是你的表現已經接近完美的時候。當然啦,你會發現,雖然min_child_weight的理想取值是6,但是我們還沒嘗試過大於6的取值。像下面這樣,就可以嘗試其它值。
param_test2b = {
'min_child_weight':[6,8,10,12]
}
gsearch2b = GridSearchCV(estimator = XGBClassifier( learning_rate=0.1, n_estimators=140, max_depth=4,
min_child_weight=2, gamma=0, subsample=0.8, colsample_bytree=0.8, objective= 'binary:logistic', nthread=4, scale_pos_weight=1,seed=27), param_grid = param_test2b, scoring='roc_auc',n_jobs=4,iid=False, cv=5)
gsearch2b.fit(train[predictors],train[target])
modelfit(gsearch3.best_estimator_, train, predictors)
gsearch2b.grid_scores_, gsearch2b.best_params_, gsearch2b.best_score_相關推薦
XGBoost引數調優完全指南(附Python程式碼)
1. 簡介 如果你的預測模型表現得有些不盡如人意,那就用XGBoost吧。XGBoost演算法現在已經成為很多資料工程師的重要武器。它是一種十分精緻的演算法,可以處理各種不規則的資料。 構造一個使用XGBoost的模型十分簡單。但是,提高這個模型的表現就有些困難(至少
機器學習系列(12)_XGBoost引數調優完全指南(附Python程式碼)
1. 簡介 如果你的預測模型表現得有些不盡如人意,那就用XGBoost吧。XGBoost演算法現在已經成為很多資料工程師的重要武器。它是一種十分精緻的演算法,可以處理各種不規則的資料。 構造一個使用XGBoost的模型十分簡單。但是,提高這個模型的表現就有些困難(至少我
機器學習系列(12)_XGBoost參數調優完全指南(附Python代碼)
row cti tar libraries 叠代 數據科學家 值範圍 邏輯回歸 doc https://blog.csdn.net/han_xiaoyang/article/details/52665396 轉: 原文地址:Complete Guide to Paramet
(轉)XGBoost引數調優完全指南
原文(英文)地址:https://www.analyticsvidhya.com/blog/2016/03/complete-guide-parameter-tuning-xgboost-with-codes-python/ 原文(翻譯)地址:https://www.2cto.com/kf/
XGBoost引數調優完全指南碰到的小問題
其中有三個地方需要注意一下 首先是要對資料進行預處理 # -*- coding: utf-8 -*- """ Created on Wed Sep 19 14:16:42 2018 @author: Administrator """ #--*- coding:u
spark 引數調優詳解(持續更新中)
spark引數調優需要對各個引數充分理解,沒有一套可以借鑑的引數,因為每個叢集規模都不一樣,只有理解了引數的用途,調試出符合自己業務場景叢集環境,並且能在擴大叢集、業務的情況下,能夠跟著修改引數。這樣才算是正確的引數調優。 1、背景 使用spark-thriftser
自己動手開發智慧聊天機器人完全指南(附python完整原始碼)
一、前言人工智慧時代,開發一款自己的智慧問答機器人,一方面提升自己的AI能力,另一方面作為轉型AI的實戰練習。在此把學習過程記錄下來,算是自己的筆記。二、正文2.1 下載pyaiml下載pyaiml2.2 安裝pip install aiml安裝aiml2.3 檢視安裝完成後
使用條件隨機場模型解決文字分類問題(附Python程式碼)
對深度學習感興趣,熱愛Tensorflow的小夥伴,歡迎關注我們的網站!http://www.tensorflownews.com。我們的公眾號:磐創AI。 一. 介紹 世界上每天都在生成數量驚人的文字資料。Google每秒處理超過40,000次搜尋,而根據福布斯報道,
利用Python實現卷積神經網路的視覺化(附Python程式碼)
對於深度學習這種端到端模型來說,如何說明和理解其中的訓練過程是大多數研究者關注熱點之一,這個問題對於那種高風險行業顯得尤為重視,比如醫療、軍事等。在深度學習中,這個問題被稱作“黑匣子(Black Box)”。如果不能解釋模型的工作過程,我們怎麼能夠就輕易相信模型的輸出結果呢? 以深度學習模型檢測
整合學習-模型融合學習筆記(附Python程式碼)
1 整合學習概述 整合學習(Ensemble Learning)是一種能在各種的機器學習任務上提高準確率的強有力技術,其通過組合多個基分類器(base classifier)來完成學習任務。基分類器一般採用的是弱可學習(weakly learnable)分類器,通過整合學習
偏度與峰度(附python程式碼)
1 矩 對於隨機變數X,X的K階原點矩為 X的K階中心矩為 期望實際上是隨機變數X的1階原點矩,方差實際上是隨機變數X的2階中心矩 變異係數(Coefficient of Variation):標準差與均值(期望)的比值稱為變異係數,記為C
基於Redis的Bloomfilter去重(附Python程式碼)
“去重”是日常工作中會經常用到的一項技能,在爬蟲領域更是常用,並且規模一般都比較大。去重需要考慮兩個點:去重的資料量、去重速度。為了保持較快的去重速度,一般選擇在記憶體中進行去重。 資料量不大時,可以直接放在記憶體裡面進行去重,例如python可以使用set()
BAT機器學習特徵工程工作經驗總結(一)如何解決資料不平衡問題(附python程式碼)
很多人其實非常好奇BAT裡機器學習演算法工程師平時工作內容是怎樣?其實大部分人都是在跑資料,各種map-reduce,hive SQL,資料倉庫搬磚,資料清洗、資料清洗、資料清洗,業務分析、分析case、找特徵、找特徵…而複雜的模型都是極少數的資料科學家在做。例
主題模型 LDA 入門(附 Python 程式碼)
一、主題模型 在文字挖掘領域,大量的資料都是非結構化的,很難從資訊中直接獲取相關和期望的資訊,一種文字挖掘的方法:主題模型(Topic Model)能夠識別在文件裡的主題,並且挖掘語料裡隱藏資訊,並且在主題聚合、從非結構化文字中提取資訊、特徵選擇等場景有廣泛的
12種降維方法終極指南(含Python程式碼)
你遇到過特徵超過1000個的資料集嗎?超過5萬個的呢?我遇到過。降維是一個非常具有挑戰性的任務,尤其是當你不知道該從哪裡開始的時候。擁有這麼多變數既是一個恩惠——資料量越大,分析結果越可信;也是一種詛咒——你真的會感到一片茫然,無從下手。 面對這麼多特徵,在微觀層面分析每個
手把手帶你實現 室內使用者移動預測(附python程式碼)
介紹 大多數的時間序列資料主要用於交易生成預測。無論是預測產品的需求量還是銷售量,航空公司的乘客數量還是特定股票的收盤價,我們都可以利用時間序列技術來預測需求。 學習Python中有不明白推薦加入交流群 號:960410445 群裡有志
OpenCV自然場景文字檢測(附Python程式碼)
本文的opencv要求 OpenCV 3.4.2或者OpenCV 4。如果你沒有安裝的話,你可以使用下面的語句進行安裝: pip install opencv-python 我們首先要下載原始碼:之後我們下載模型,放入原始碼中,之後我們看一下目錄結構: 之後我們更新
解析機器中加減法對於二進位制補碼的運用(附python程式碼)
機器中的加減法並不像我們實際生活中一樣,帶有正負號,比較容易運算,機器中只有0和1,那就需要一種演算法來實現加減法運算。 首先,我們要明確目標是要進行帶符號的數字(signed)進行加減法運算。 由於沒有正負號,我們要採取一種措施來使某一位變為符號位,即最高位,如果是負數那
10種機器學習演算法(附Python程式碼)
sklearn python API from sklearn.linear_model import LinearRegression # 線性迴歸 # module = LinearRegression() module.fit(x
作圖直觀理解Parzen窗估計(附Python程式碼)
## 1.簡介 Parzen窗估計屬於**非引數估計**。所謂非引數估計是指,已知樣本所屬的類別,但未知總體概率密度函式的形式,要求我們直接推斷概率密度函式本身。 > 對於不瞭解的可以看一下https://zhuanlan.zhihu.com/p/88562356 **下面僅對《模式分類》(第二版)的內