
文字主題模型之LDA(二) LDA求解之Gibbs取樣演算法
阿新 • • 發佈:2018-12-04
本文是LDA主題模型的第二篇,讀這一篇之前建議先讀文字主題模型之LDA(一) LDA基礎,同時由於使用了基於MCMC的Gibbs取樣演算法,如果你對MCMC和Gibbs取樣不熟悉,建議閱讀之前寫的MCMC系列MCMC(四)Gibbs取樣。
1. Gibbs取樣演算法求解LDA的思路
首先,回顧LDA的模型圖如下:
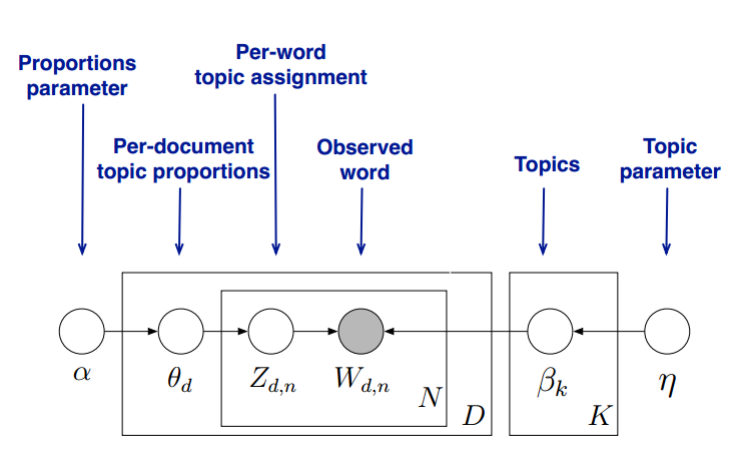
在Gibbs取樣演算法求解LDA的方法中,我們的α,ηα,η是已知的先驗輸入,我們的目標是得到各個zdn,wknzdn,wkn對應的整體
具體到我們的問題,我們的所有文件聯合起來形成的詞向量w⃗ w→是已知的資料,不知道的是語料庫主題z⃗ z→的分佈。假如我們可以先求出w,zw,z的聯合分佈p(w⃗ ,z⃗ )p(w→,z→),進而可以求出某一個詞