
機器學習之LDA主題模型演算法
阿新 • • 發佈:2018-12-13
1、知道LDA的特點和應用方向
1.1、特點
知道LDA說的降維代表什麼含義:將一篇分詞後的文章降維為一個主題分佈(即如20個特徵向量主題)。
根據對應的特徵向量中的相關主題概率(20個主題的概率相加為1即為主題分佈)得到對應的文件主題,屬於無監督學習(你沒有給每個資料打標籤)
1.2、應用方向
資訊提取與搜尋(語義分析),文件的分、聚類,文章摘要,計算機視覺,生物資訊等方向(只要包含隱變數都可考慮使用)
PS:知道樸素貝葉斯在文字分析的劣勢:無法識別一詞多義和多詞一意。
2、知道Beta分佈和Dirichlet分佈數學含義
Beta分佈概率密度表示式是一條曲線,係數B的表示式是曲線下的面積。
知道二項分佈的共軛先驗分佈是Beta分佈,多項分佈的共軛先驗分佈是Dirichlet分佈。


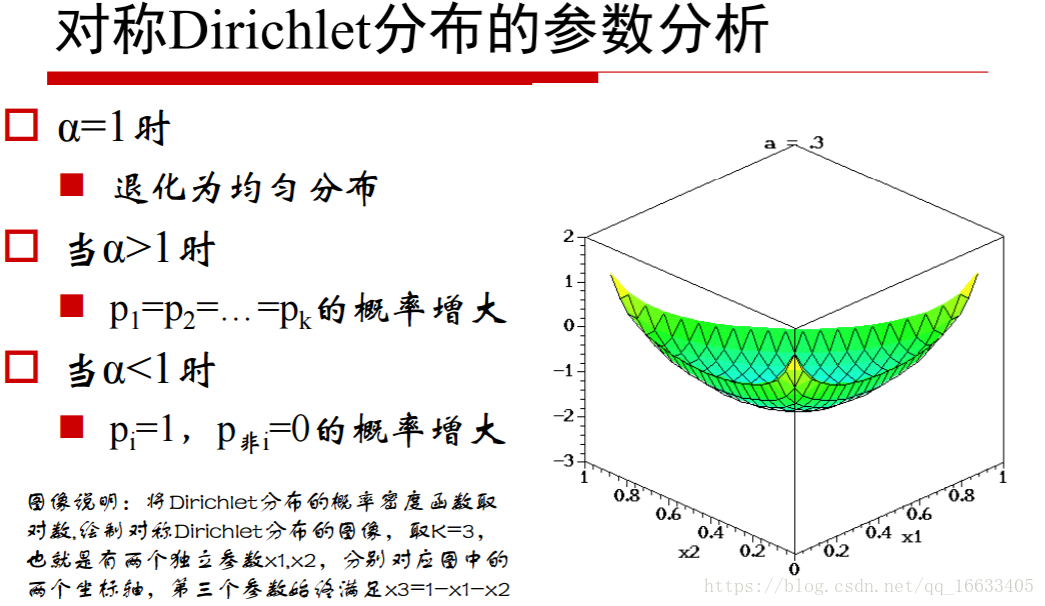
知道Dirichlet分佈的概率密度函式的數學含義:當K=3時,密度函式數學含義也就是一個曲面

3、瞭解共軛先驗分佈
含義:找個一個先驗分佈和後驗分佈都滿足於同一種分佈的概率分佈。這樣你知道其中的一個分佈就代表知道了另外一個分佈。

4、知道先驗概率和後驗概率
**先驗概率:**是指根據以往經驗和分析得到的概率.
**後驗概率:**事情已經發生,要求這件事情發生的原因是由某個因素引起的可能性的大小
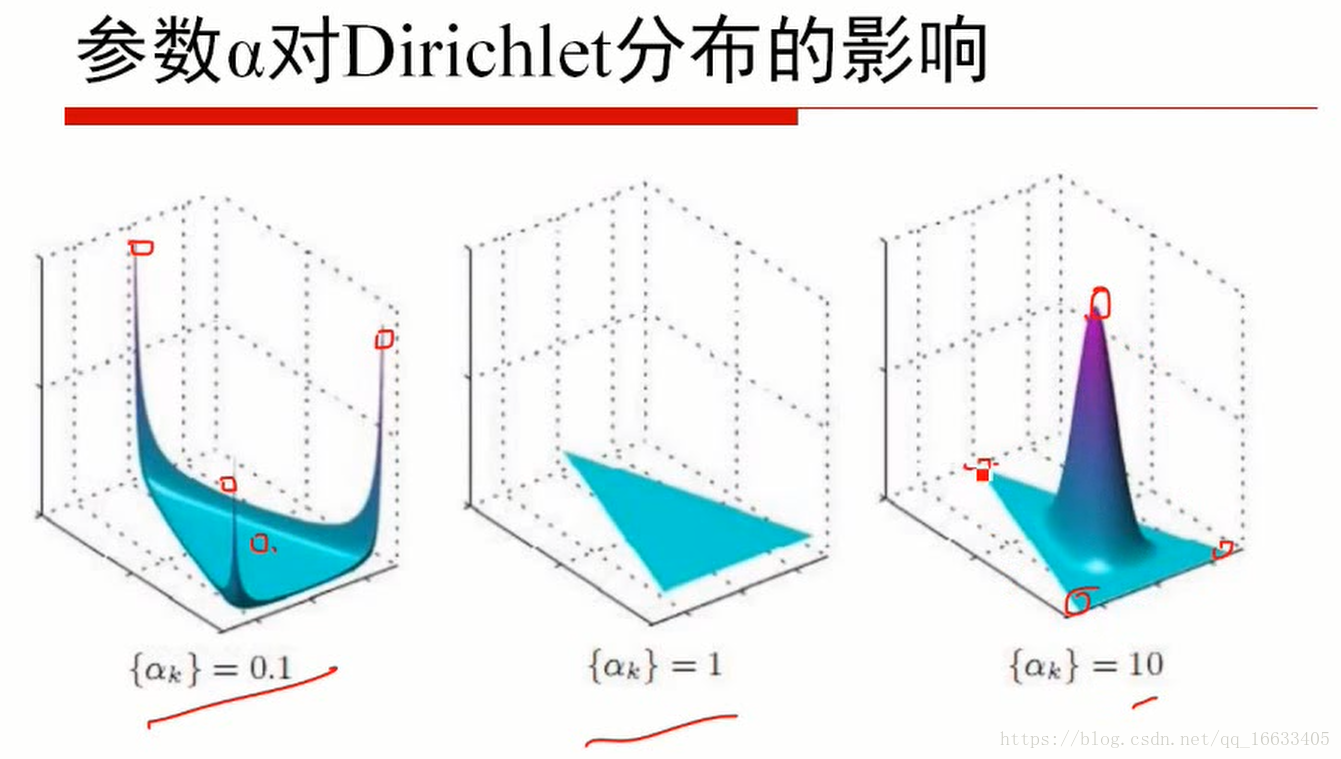
5、知道引數α值的大小對應的含義
當α小於1的時候代表取某一個值的概率很高(即某一主題的概率很高即主題鮮明),=1的時候代表概率為均勻分佈,大於1的時候代表k個p相同的概率增大。
對應的z軸就代表這個點對應的概率
6、掌握LDA主題模型的生成過程
總結一句話:主題概率模型生成一個主題分佈再生成一個主題,詞概率模型生成主題的詞分佈再生成一個詞;最終得到一個主題對應這個詞。(連線的條件主題的標號)
掌握整個過程:
θ代表的一個主題分佈,即K維的主題向量。


- 從α控制的Dirichlet分佈的概率密度函式中採取一個對應的K維的主題分佈即θm(第m篇文件的主題)
- 從β控制的Dirichlet分佈的概率密度函式中生成K個對應的V維的詞分佈即φk
- Zm,n即代表第m個文件的第n個主題。當n=2時即代表採到第m篇文件的第二個主題,就到對應的β生成的第二個主題的詞分佈即φk(對應的第幾個主題的詞分佈)
- 從φk中隨機挑選一個詞作為Wm,n的值(即第m篇文件第n個主題對應的詞)
- 迴圈執行上述步驟得到每個主題對應的詞
PS:各個引數的含義
θm代表第m篇文件的主題分佈(m為文件總數)
φk表示第k個主題的詞分佈(k為主題的個數)
Zm,n代表第m篇文件中的第n個主題
Wm,n代表第m篇文件中的第n個單詞

7、知道超引數α等值的參考值

8、LDA總結
- 由於在詞和文件之間加入的主題的概念,可以較好的解決一詞多義和多詞一義的問題。
- 在實踐中發現,LDA用於短文件往往效果不明顯一這是可以解釋的:因為一個詞被分配給某個主題的次數和一個主題包括的詞數目尚未斂。往往需要通過其他方親“連線”成長文件。
- 使用者評論/Twitter/微博囗LDA可以和其他演算法相結合。首先使用LDA將長度Ni的文件降維到K維(主題的數目),同時給出每個主題的概率(主題分佈),從而可以使用if-idf繼續分析或者直接作為文件的特徵進入聚類或者標籤傳播演算法用於社群發現等問題。
- 知道LDA是一個生成模型,由y得到對應的x(y代表的是主題,x代表的詞)