
2.5 WordContent簡單應用
第2章 Hadoop快速入門
2.5 WordContent簡單應用
Hadoop的HelloWorld程式
2.5.1 建立HDFS目錄
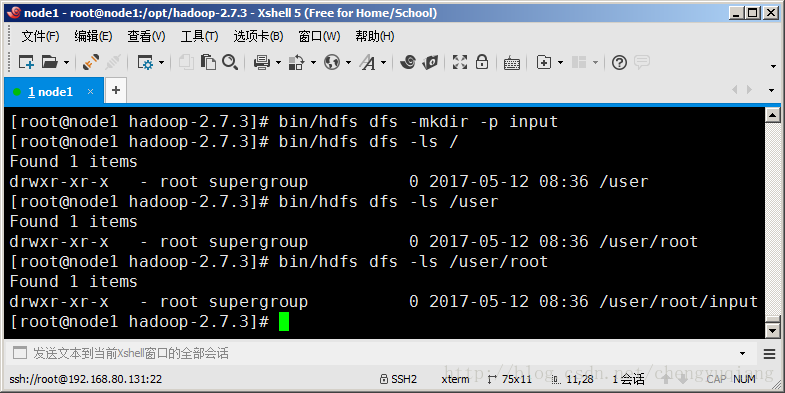
hdfs命令位於bin目錄下,通過hdfs dfs -mkdir命令可以建立一個目錄。
[root@node1 hadoop-2.7.3]# bin/hdfs dfs -mkdir -p input
- 1
hdfs建立的目錄預設會放到/user/{username}/目錄下面,其中{username}是當前使用者名稱。所以input目錄應該在/user/root/下面。
下面通過`hdfs dfs -ls`命令可以檢視HDFS目錄檔案
[root@node1 hadoop-2.7.3]# bin/hdfs dfs -ls /
- 1
2.5.2 上傳檔案到HDFS
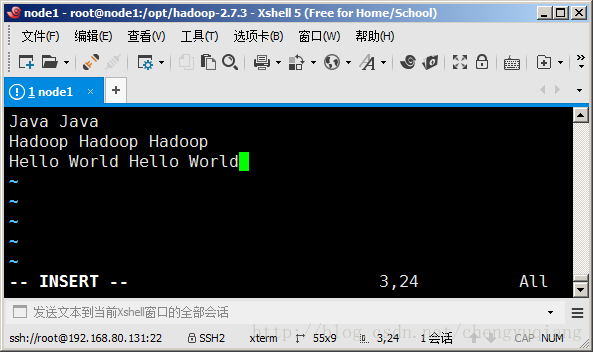
在本地新建一個文字檔案
vi /root/words.txt
[root@node1 hadoop-2.7.3]# vi /root/words.txt
- 1
隨便輸入幾個單詞,儲存退出。
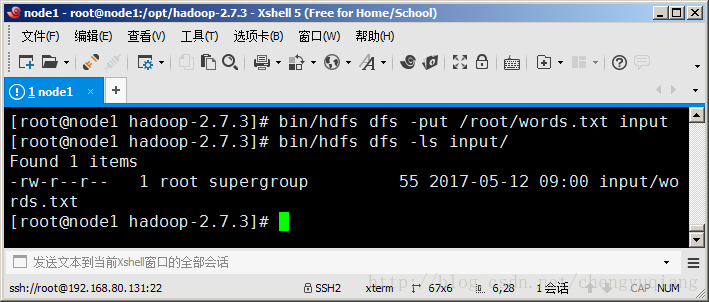
將本地檔案/root/words.txt上傳到HDFS bin/hdfs dfs -put /root/words.txt input
bin/hdfs dfs -ls input
2.5.3 執行WordContent
執行下面命令:
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount input output
-
[[email protected] hadoop-
2.7
.3
-
17/
05/
12
09:
04:
39 INFO client.RMProxy: Connecting
to ResourceManager at /
0.0
.0
.0:
8032
-
17/
05/
12
09:
04:
41 INFO input.FileInputFormat: Total input paths
to
process :
1
-
17/
05/
12
09:
04:
41 INFO mapreduce.JobSubmitter: number
of splits:
1
-
17/
05/
12
09:
04:
42 INFO mapreduce.JobSubmitter: Submitting tokens
for job: job_1494590593576_0001
-
17/
05/
12
09:
04:
43 INFO impl.YarnClientImpl: Submitted application application_1494590593576_0001
-
17/
05/
12
09:
04:
43 INFO mapreduce.Job: The url
to track the job: http:
//node1:
8088
/proxy/application_1494590593576_0001/
-
17/
05/
12
09:
04:
43 INFO mapreduce.Job: Running job: job_1494590593576_0001
-
17/
05/
12
09:
05:
08 INFO mapreduce.Job: Job job_1494590593576_0001 running
in uber mode : false
-
17/
05/
12
09:
05:
08 INFO mapreduce.Job:
map
0% reduce
0%
-
17/
05/
12
09:
05:
19 INFO mapreduce.Job:
map
100% reduce
0%
-
17/
05/
12
09:
05:
31 INFO mapreduce.Job:
map
100% reduce
100%
-
17/
05/
12
09:
05:
32 INFO mapreduce.Job: Job job_1494590593576_0001 completed successfully
-
17/
05/
12
09:
05:
32 INFO mapreduce.Job: Counters:
49
-
File System Counters
-
FILE: Number
of bytes
read=
54
-
FILE: Number
of bytes written=
237325
-
FILE: Number
of
read operations=
0
-
FILE: Number
of large
read operations=
0
-
FILE: Number
of
write operations=
0
-
HDFS: Number
of bytes
read=
163
-
HDFS: Number
of bytes written=
32
-
HDFS: Number
of
read operations=
6
-
HDFS: Number
of large
read operations=
0
-
HDFS: Number
of
write operations=
2
-
Job Counters
-
Launched
map tasks=
1
-
Launched reduce tasks=
1
-
Data-
local
map tasks=
1
-
Total
time spent by
all maps
in occupied slots (ms)=
8861
-
Total
time spent by
all reduces
in occupied slots (ms)=
8430
-
Total
time spent by
all
map tasks (ms)=
8861
-
Total
time spent by
all reduce tasks (ms)=
8430
-
Total vcore-milliseconds taken by
all
map tasks=
8861
-
Total vcore-milliseconds taken by
all reduce tasks=
8430
-
Total megabyte-milliseconds taken by
all
map tasks=
9073664
-
Total megabyte-milliseconds taken by
all reduce tasks=
8632320
-
Map-Reduce Framework
-
Map input records=
3
-
Map output records=
9
-
Map output bytes=
91
-
Map output materialized bytes=
54
-
Input split bytes=
108
-
Combine input records=
9
-
Combine output records=
4
-
Reduce input groups=
4
-
Reduce shuffle bytes=
54
-
Reduce input records=
4
-
Reduce output records=
4
-
Spilled Records=
8
-
Shuffled Maps =
1
-
Failed Shuffles=
0
-
Merged
Map outputs=
1
-
GC
time elapsed (ms)=
249
-
CPU
time spent (ms)=
2950
-
Physical memory (bytes) snapshot=
303017984
-
Virtual memory (bytes) snapshot=
4157116416
-
Total committed heap usage (bytes)=
165810176
-
Shuffle Errors
-
BAD_ID=
0
-
CONNECTION=
0
-
IO_ERROR=
0
-
WRONG_LENGTH=
0
-
WRONG_MAP=
0
-
WRONG_REDUCE=
0
-
File Input Format Counters
-
Bytes
Read=
55
-
File Output Format Counters
-
Bytes Written=
32
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
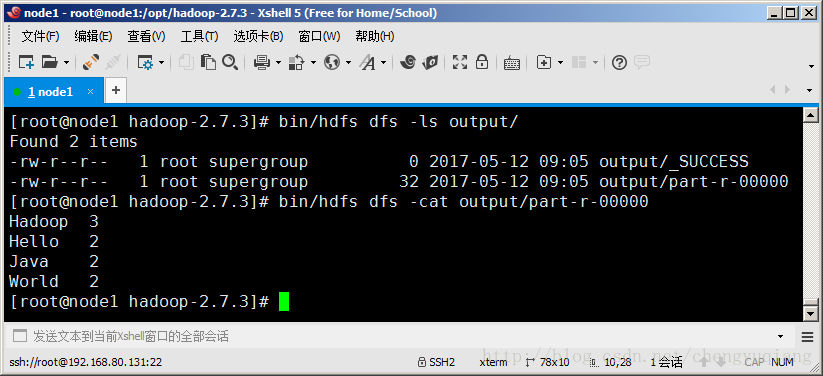
2.5.4 檢視結果
bin/hdfs dfs -ls output
bin/hdfs dfs -cat output/part-r-00000
-
[root
@node1 hadoop-
2.7.
3]
# bin/hdfs dfs -ls output/
-
Found
2 items
-
-rw-r--r--
1 root supergroup
0
2017-
05-
12 09
:
05 output/_SUCCESS
-
-rw-r--r--
1 root supergroup
32
2017-
05-
12 09
:
05 output/part-r-
00000
-
[root
@node1 hadoop-
2.7.
3]
# bin/hdfs dfs -cat output/part-r-00000
-
Hadoop
3
-
Hello
2
-
Java
2
-
World
2
-
[root
@node1 hadoop-
2.7.
3]
#
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
第2章 Hadoop快速入門
2.5 WordContent簡單應用
Hadoop的HelloWorld程式
2.5.1 建立HDFS目錄
hdfs命令位於bin目錄下,通過hdfs dfs -mkdir命令可以建立一個目錄。
[root@node1 hadoop-2.7.3]# bin/hdfs dfs -mkdir -p input
- 1
hdfs建立的目錄預設會放到/user/{username}/目錄下面,其中{username}是當前使用者名稱。所以input目錄應該在/user/root/下面。
下面通過`hdfs dfs -ls`命令可以檢視HDFS目錄檔案
[root@node1 hadoop-2.7.3]# bin/hdfs dfs -ls /
- 1
2.5.2 上傳檔案到HDFS
在本地新建一個文字檔案
vi /root/words.txt
[root@node1 hadoop-2.7.3]# vi /root/words.txt
- 1
隨便輸入幾個單詞,儲存退出。
將本地檔案/root/words.txt上傳到HDFS bin/hdfs dfs -put /root/words.txt input bin/hdfs dfs -ls input
2.5.3 執行WordContent
執行下面命令:
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount input output
-
[[email protected] hadoop-
2.7
.3]# bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-
2.7
.3.jar wordcount input output
-
17/
05/
12
09:
04:
39 INFO client.RMProxy: Connecting
to ResourceManager at /
0.0
.0
.0:
8032
-
17/
05/
12
09:
04:
41 INFO input.FileInputFormat: Total input paths
to
process :
1
-
17/
05/
12
09:
04:
41 INFO mapreduce.JobSubmitter: number
of splits:
1
-
17/
05/
12
09:
04:
42 INFO mapreduce.JobSubmitter: Submitting tokens
for job: job_1494590593576_0001
-
17/
05/
12
09:
04:
43 INFO impl.YarnClientImpl: Submitted application application_1494590593576_0001
-
17/
05/
12
09:
04:
43 INFO mapreduce.Job: The url
to track the job: http:
//node1:
8088
/proxy/application_1494590593576_0001/
-
17/
05/
12
09:
04:
43 INFO mapreduce.Job: Running job: job_1494590593576_0001
-
17/
05/
12
09:
05:
08 INFO mapreduce.Job: Job job_1494590593576_0001 running
in uber mode : false
-
17/
05/
12
09:
05:
08 INFO mapreduce.Job:
map
0% reduce
0%
-
17/
05/
12
09:
05:
19 INFO mapreduce.Job:
map
100% reduce
0%
-
17/
05/
12
09:
05:
31 INFO mapreduce.Job:
map
100% reduce
100%
-
17/
05/
12
09:
05:
32 INFO mapreduce.Job: Job job_1494590593576_0001 completed successfully
-
17/
05/
12
09:
05:
32 INFO mapreduce.Job: Counters:
49
-
File System Counters
-
FILE: Number
of bytes
read=
54
-
FILE: Number
of bytes written=
237325
-
FILE: Number
of
read operations=
0
-
FILE: Number
of large
read operations=
0
-
FILE: Number
of
write operations=
0
-
HDFS: Number
of bytes
read=
163
-
HDFS: Number
of bytes written=
32
-
HDFS: Number
of
read operations=
6
-