
scrapy執行機制
阿新 • • 發佈:2018-12-04
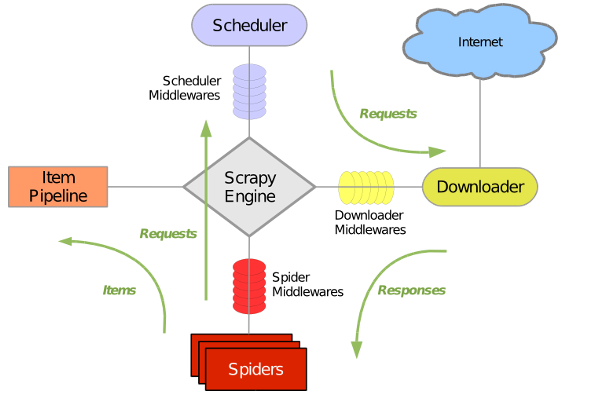
Scrapy主要包括了以下元件:
- 引擎(Scrapy)
用來處理整個系統的資料流, 觸發事務(框架核心) - 排程器(Scheduler)
用來接受引擎發過來的請求, 壓入佇列中, 並在引擎再次請求的時候返回. 可以想像成一個URL(抓取網頁的網址或者說是連結)的優先佇列, 由它來決定下一個要抓取的網址是什麼, 同時去除重複的網址 - 下載器(Downloader)
用於下載網頁內容, 並將網頁內容返回給蜘蛛(Scrapy下載器是建立在twisted這個高效的非同步模型上的) - 爬蟲(Spiders)
爬蟲是主要幹活的, 用於從特定的網頁中提取自己需要的資訊, 即所謂的實體(Item)。使用者也可以從中提取出連結,讓Scrapy繼續抓取下一個頁面 - 專案管道(Pipeline)
負責處理爬蟲從網頁中抽取的實體,主要的功能是持久化實體、驗證實體的有效性、清除不需要的資訊。當頁面被爬蟲解析後,將被髮送到專案管道,並經過幾個特定的次序處理資料。 - 下載器中介軟體(Downloader Middlewares)
位於Scrapy引擎和下載器之間的框架,主要是處理Scrapy引擎與下載器之間的請求及響應。 - 爬蟲中介軟體(Spider Middlewares)
介於Scrapy引擎和爬蟲之間的框架,主要工作是處理蜘蛛的響應輸入和請求輸出。 - 排程中介軟體(Scheduler Middewares)
介於Scrapy引擎和排程之間的中介軟體,從Scrapy引擎傳送到排程的請求和響應。
Scrapy執行流程大概如下:
- 引擎從排程器中取出一個連結(URL)用於接下來的抓取
- 引擎把URL封裝成一個請求(Request)傳給下載器
- 下載器把資源下載下來,並封裝成應答包(Response)
- 爬蟲解析Response
- 解析出實體(Item),則交給實體管道進行進一步的處理
- 解析出的是連結(URL),則把URL交給排程器等待抓取