
Hadoop叢集安裝Pig
下載壓縮包:http://www.apache.org/dyn/closer.cgi/pig

解壓:
tar -zxvf pig-0.17.0.tar.gz -C ~/
配置:
在 ~/.bashrc 檔案末尾新增,其中HADOOP_HOME為Hadoop安裝路徑,如HADOOP_HOME = /usr/local/hadoop:
export PIG_HOME=/home/hadoop/pig-0.17.0 export PATH=$PATH:$PIG_HOME/bin/ export PIG_CLASSPATH=$HADOOP_HOME/etc/hadoop export PATH=$PATH:$PIG_CLASSPATH
使配置檔案生效:source ~/.bashrc。
使用 Pig:
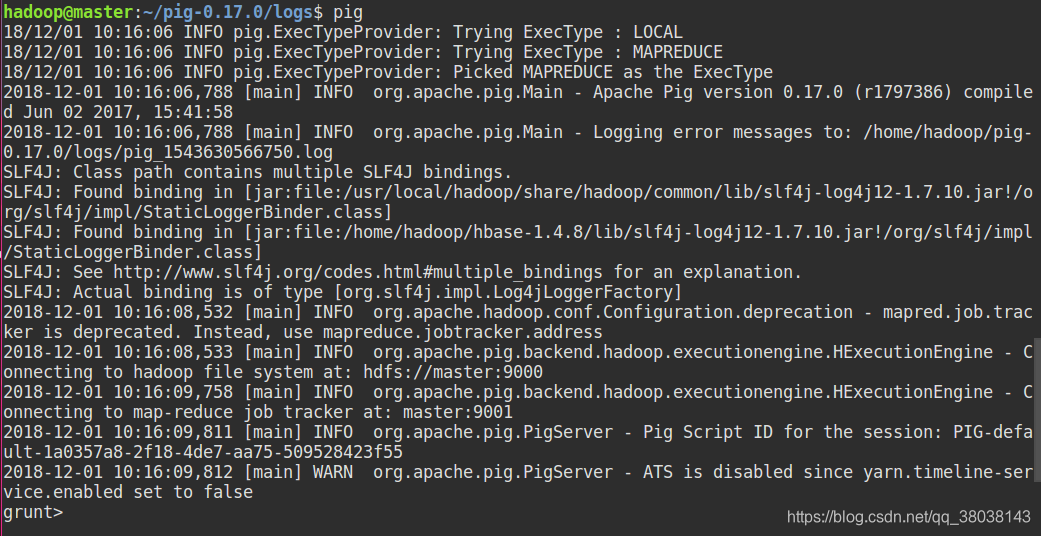
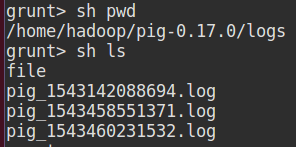
檢視當前所在本地目錄檔案:
相關推薦
Hadoop叢集安裝Pig
下載壓縮包:http://www.apache.org/dyn/closer.cgi/pig 解壓: tar -zxvf pig-0.17.0.tar.gz -C ~/ 配置: 在 ~/.bashrc 檔案末尾新增,其中HADOOP_HOME為Hadoop安裝路徑,如HA
vmware中hadoop叢集安裝指南
1、準備Linux環境 1.0先將虛擬機器的網路模式選為NAT 1.1修改主機名 vi /etc/sysconfig/network &n
hadoop叢集安裝20181016
安裝jdk 一、通過ppa源下載: 1.新增ppa元, sudo add-apt-repository ppa:webupd8team/java #等待一會兒 sudo apt-get update 2.安裝oracle-java-installer sudo apt-get install
hadoop叢集安裝前環境的配置
1.1增加hadoop使用者 一)建立一個admin使用者 [[email protected] home]# adduser hadoop 沒輸出?沒有輸出在linux下就是操作正確 (二)為admin使用者設定密碼 [[email protected]
1.Hadoop叢集安裝部署
Hadoop叢集安裝部署 1.介紹 (1)架構模型 (2)使用工具 VMWARE cenos7 Xshell Xftp jdk-8u91-linux-x64.rpm hadoop-2.7.3.tar.gz 2.安裝步驟 (1)部署master 建立一臺虛擬機器 Xftp傳輸jdk、hadhoop安裝
2.Hadoop叢集安裝進階
Hadoop進階 1.配置SSH免密 (1)修改slaves檔案 切換到master機器,本節操作全在master進行。 進入/usr/hadoop/etc/hadoop目錄下,找到slaves檔案,修改: slave1 slave2 slave3 (2)傳送公鑰 進入根目錄下的.ssh目錄: 生成公私鑰
Hadoop叢集安裝配置
Hadoop的安裝分為單機方式、偽分散式方式 和 完全分散式方式。 單機模式 : Hadoop的預設模式。當首次解壓Hadoop的原始碼包時,Hadoop無法瞭解硬體安裝環境,便保守地選擇了最小配置。在這種預設模式下所有3個XML檔案均為空。當配置檔案為空時,Hadoop會完全執行在本地
VMWare14中Hadoop叢集安裝記錄
標籤(空格分隔): Hadoop --- 軟體: [VMWare14](https://pan.baidu.com/s/1_fZPVguQGPbXH-fMmc68YQ) (提取碼:2rsq), [CentOS 7](http://isoredirect.centos.
Hadoop叢集安裝的簡易操作
基於Hadoop分散式叢集的搭建 對於Hadoop叢集的搭建,一直處於摸索狀態,但這個在資料探勘中確實相當的重要,所以總結如下: ssh免密登入 安裝ssh客戶端 $ sudo apt-get install openssh-client 安裝完客戶端後
Hadoop叢集安裝四大模式
叢集的安裝模式: 1.單機模式:只需要解壓即可用,沒有分散式的檔案系統,也沒有namenode datanode Secondar等,檔案系統就是linux/widows的本地檔案系統。 用於:程式碼除錯 2.偽分散式:有相關的hdfs或yar
Hadoop叢集安裝配置教程_Hadoop2.6.0_Ubuntu/CentOS
Hadoop叢集安裝配置教程_Hadoop2.6.0_Ubuntu/CentOS 2014-08-09 (updated: 2016-09-26) 125333 217 本教程適合於原生 Hadoop 2,包括 Hadoop 2.6.0, Hadoop 2.7.1 等
Hadoop 叢集安裝(主節點安裝)
1、下載安裝包及測試文件 切換目錄到/tmp view plain copy cd /tmp 下載Hadoop安裝包 view plain copy wget http://192.168.1.100:60000/hadoop-2.6.0-cdh5.4.5.tar.gz 下載JDK安裝包 view pl
Hadoop 叢集安裝(從節點安裝配置)
1、Java環境配置 view plain copy sudo mv /tmp/java /opt/ jdk安裝完配置環境變數,編輯/etc/profile: view plain copy sudo vim /etc/profile 在檔案末尾,新增如下內容: view plain copy expor
hadoop 叢集安裝與部署(大資料系列)
什麼是大資料 基本概念 《資料處理》 在網際網路技術發展到現今階段,大量日常、工作等事務產生的資料都已經資訊化,人類產生的資料量相比以前有了爆炸式的增長,以前的傳統的資料處理技術已經無法勝任,需求催生技術,一套用來處理海量資料的軟體工具應運而生,這就是大資料!
CentOS7.0基於hadoop叢集安裝配置Hive
前言 安裝Apache Hive前提是要先安裝hadoop叢集,並且hive只需要在hadoop的namenode節點叢集裡安裝即可(需要再有的namenode上安裝),可以不在datanode節點的機器上安裝。還需要說明的是,雖然修改配置檔案並不需要把had
Hadoop叢集安裝、擴容等操作
0 Hadoop叢集機器配置 公司正式叢集機子:記憶體32G儲存24T,另有1塊1T的本地盤 namenode和secondery namenode配Xeon E5-2640,24執行緒 其餘節點配X
Hadoop叢集安裝步驟
大家好,今天講解的是Hadoop安裝步驟,內容下: 一、前期準備 1、必須要有三臺Linux(小編使用的是ubuntu14.04server版,大家也可以使用別的Linux,但三臺電腦必須是統一的Linux版本,ubuntu14.04server下載地址[h
hadoop叢集安裝到centos7
hadoop hdfs叢集(負責檔案讀寫) yam叢集(負責為mapreduce分配硬體資源) name node 預設埠9000(客戶端) resource manage (管理幹活的) data node(node manage)(幹活的) 準備
Apache hadoop叢集安裝的三種方式:本地、偽分佈、完全分佈
四 Hadoop執行模式1)官方網址(1)官方網站:(2)各個版本歸檔庫地址 (3)hadoop2.7.2版本詳情介紹2)Hadoop執行模式(1)本地模式(預設模式):不需要啟用單獨程序,直接可以執行,測試和開發時使用。(2)偽分散式模式:等同於完全分散式,只有一個節點。(
hadoop-2.5.0,hbase,hive,pig,sqoop,zookeeper 叢集安裝
1. 準備工作 軟體準備: 1) Hadoop: hadoop-2.5.0.tar.gz 2) Jdk: jdk-7u71-linux-x64.tar.gz 3) Hive:apache-hive-0.13.1-bin.tar