
python網路爬蟲入門簡介
python爬蟲的一些理解
(整理的有點亂,請多多關照)
1 . 爬蟲簡介
爬蟲: 一段自動抓取網際網路資訊的程式

2. 爬蟲價值
資訊資料
3. 爬蟲架構

4. 執行流程
(解:執行從上到下流程)
排程器 **** URL管理器 **** 下載器 **** 解析器 ***** 應用
-----有待爬URL—→
←-----是/否--------
-----獲取1個帶爬URL→
←----- URL --------
----------------下載URL內容-------- →
----------------URL的內容----------- →
------------------------解析URL內容------------- -→
--------------------價值資料,新URL列表----------- →
------------------------------收集價值資料------------------------→
-----新增到待爬URL—→
URL管理器
URL管理器:管理待抓取URL集合和已抓取URL集合
防止重複抓取、防止迴圈抓取
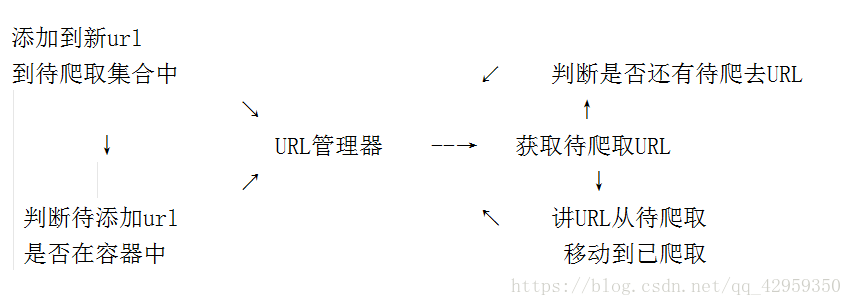
URL管理器 : 實現方式

網頁下載器

網頁下載器 - urllib2
- urllib2下載網頁的方法1:

直接請求
response = urllib2.urlopen(‘http://www.baidu.com’)
獲取狀態碼,如果是200表示獲取成功
print response.getcode()
讀取內容
cont = response.read()
第二種方法
-
urllib2下載網頁方法2: 新增data、http header
url data header ↘ ↓ ↙ urllib2.Request ↓ urllib2.urlopen(request)
操作程式碼
import urllib2
#建立Request物件
request = urllib2.Request(url)
#新增資料
request.add_header(‘User-Agent’, ‘Mozilla/S.0’)
傳送請求獲取結果
response = urllib2.urlopen(request)
第三種辦法(登陸才能訪問)
urllib2下載網頁方法3: 新增特殊場景的處理器
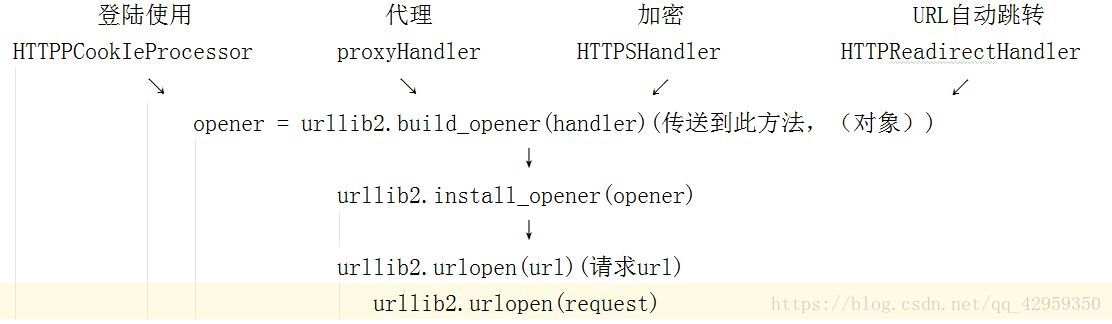
操作程式碼
import urllib2, cookielib
建立cookie容器
cj = cookielib.CookieJar()
建立1個opener
opener = urllib2.build_opener(urllib2.HTTPCookiePRocessor(cj))
給urllib2安裝opener
urllib2.install_opener(opener)
使用帶有cookie的urllib2訪問網頁
response = urllib2.urlopen(“http://www.baidu.com/”)