
python網路爬蟲之入門[一]
目錄
- 前言
- 一、探討什麼是python網路爬蟲?
- 二、一個針對於網路傳輸的抓包工具fiddler
- 三、學習request模組來爬取第一個網頁
- * 擴充套件內容(爬取top250的網頁)
- 後記
@(目錄)
前言
hello,接下來就學習如何使用Python爬蟲功能。
在接下來的章節中可以給大家整理一個完整的學習要點,當然都是一個簡單的知識點,
喔,本人認為就是一個入門,不會講的特別深入,因為接下來的一章中可能有多個知識點,
不過自主的學習才是王道
奧力給!!!
廢話不多說,先整理一下本次內容:
1、探討什麼是python網路爬蟲?
2、一個針對於網路傳輸的抓包工具fiddler
3、學習request模組來爬取第一個網頁
一、探討什麼是python網路爬蟲?
相信大家如果是剛學python或是剛學java的各位來說的話,一定會有來自靈魂深處的四問。。。
我是誰?,我在那?.....額,不是
咳咳,是這個:
1、什麼是網路爬蟲?
2、為什麼要學網路爬蟲?
3、網路爬蟲用在什麼地方?
4、網路爬蟲是否合法?
喲西,放馬過來,一個一個來。
1、什麼是網路爬蟲?
如果說網路就是一張網的話,那麼網路爬蟲就是可以在網上獲取食物的蜘蛛(spider)

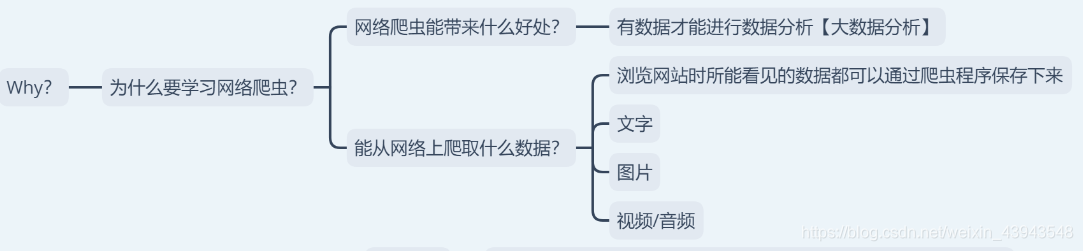
2、為什麼要學網路爬蟲?
這個的話,就感覺是在問你為什麼要學習python一樣。。(~ ̄▽ ̄)~
嘛,總的來說就是教你可以在網上爬取到什麼樣的資料以及學到神馬東西。
3、網路爬蟲用在什麼地方?
額,用在什麼地方,什麼地方都能用到哦,比如:在找工作的時候把所有的招聘資訊爬取下來,然後再自己慢慢解析,又比如:爬取某些網站的圖片.....

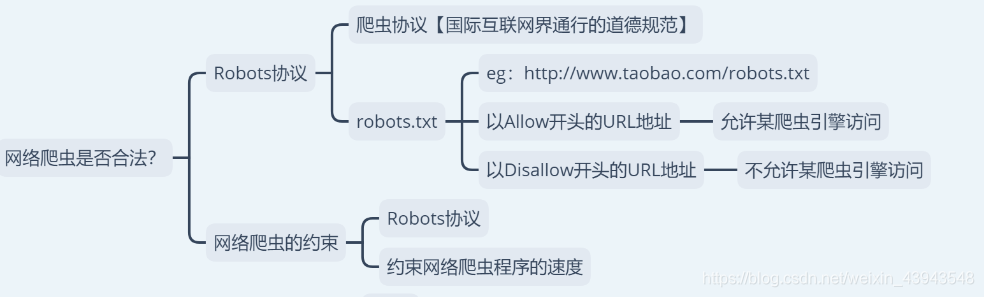
4、網路爬蟲是否合法?
enn,先說好啊,本章部落格是用來學習部落格,不會用來做任何商業用途
5、最後說一下,接下來會學習的內容,不過可能會有些變動
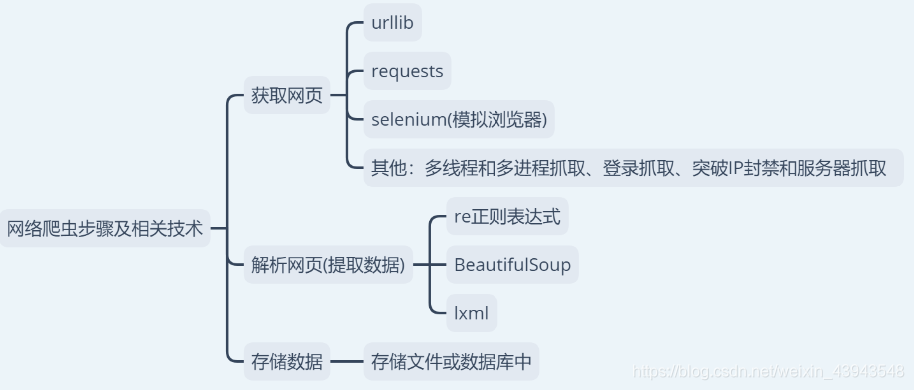
let`go
二、一個針對於網路傳輸的抓包工具fiddler
這個我就不講了,因為之前做過之類的部落格。額,有不懂的可以私信
直接上傳送門:Fiddler抓包工具
三、學習request模組來爬取第一個網頁
喔,因為我沒有整理其他的比如:python直譯器的安裝之類的,額,不懂的暫時先可以去看看基礎之類的。
python入門【一】
這個內容可能比較的枯燥啊。
1、下載requesets模組
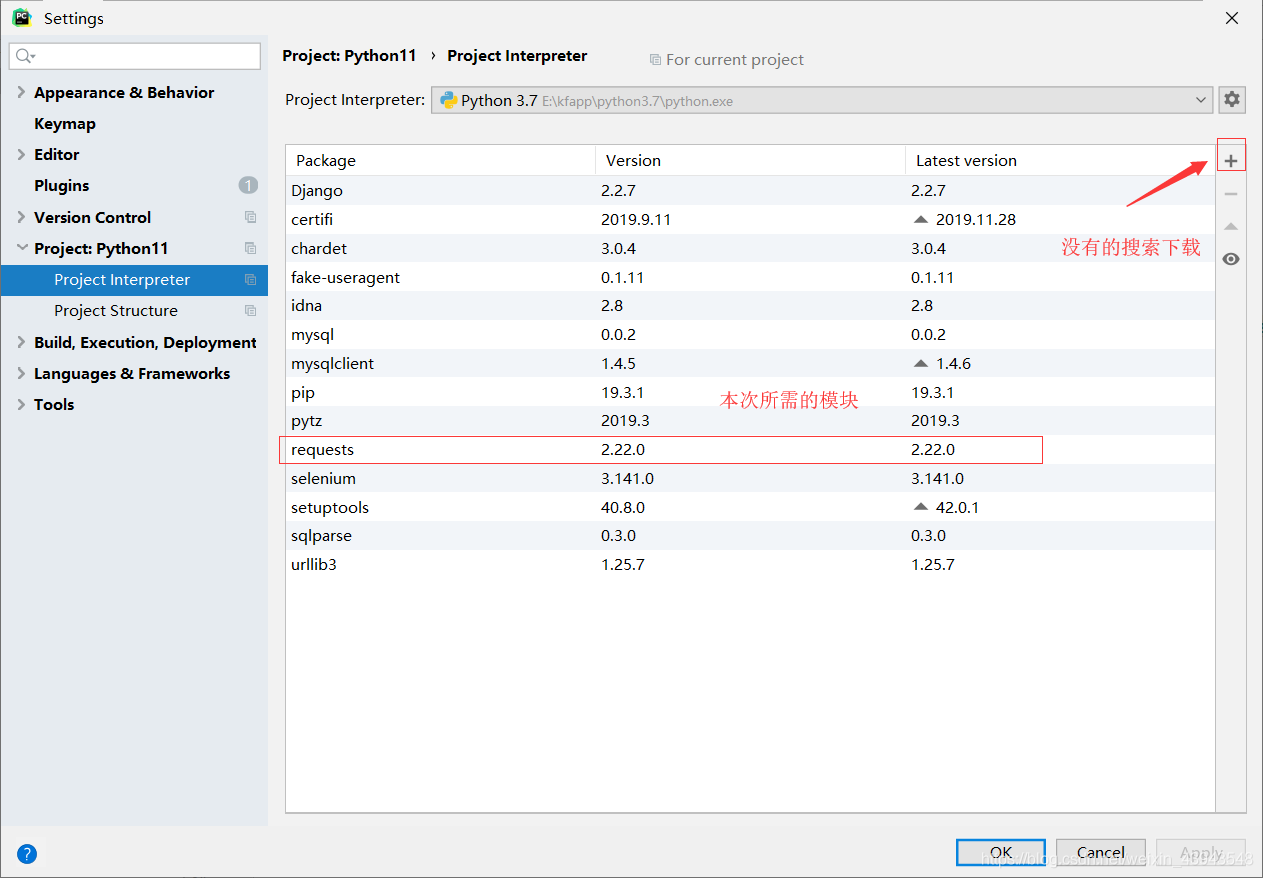
沒有的話就下載
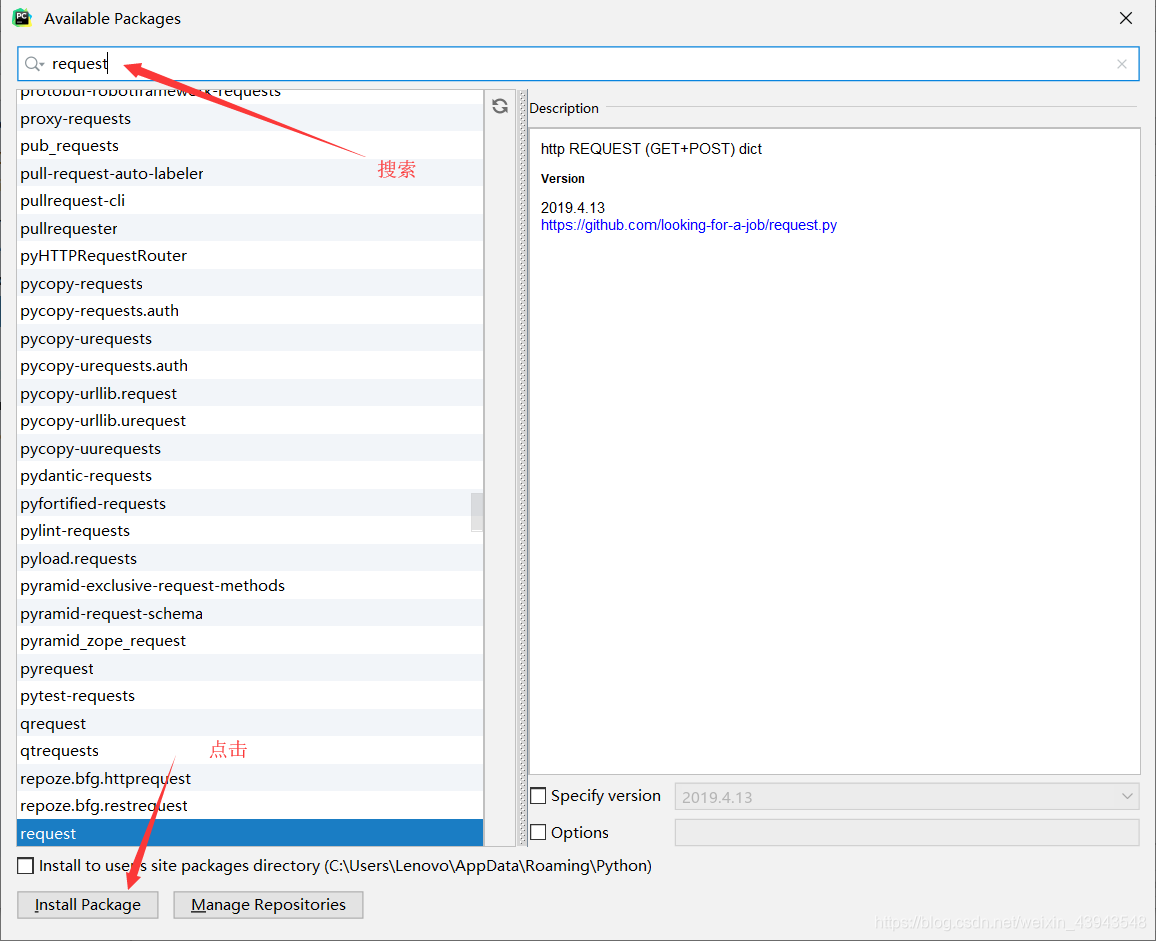
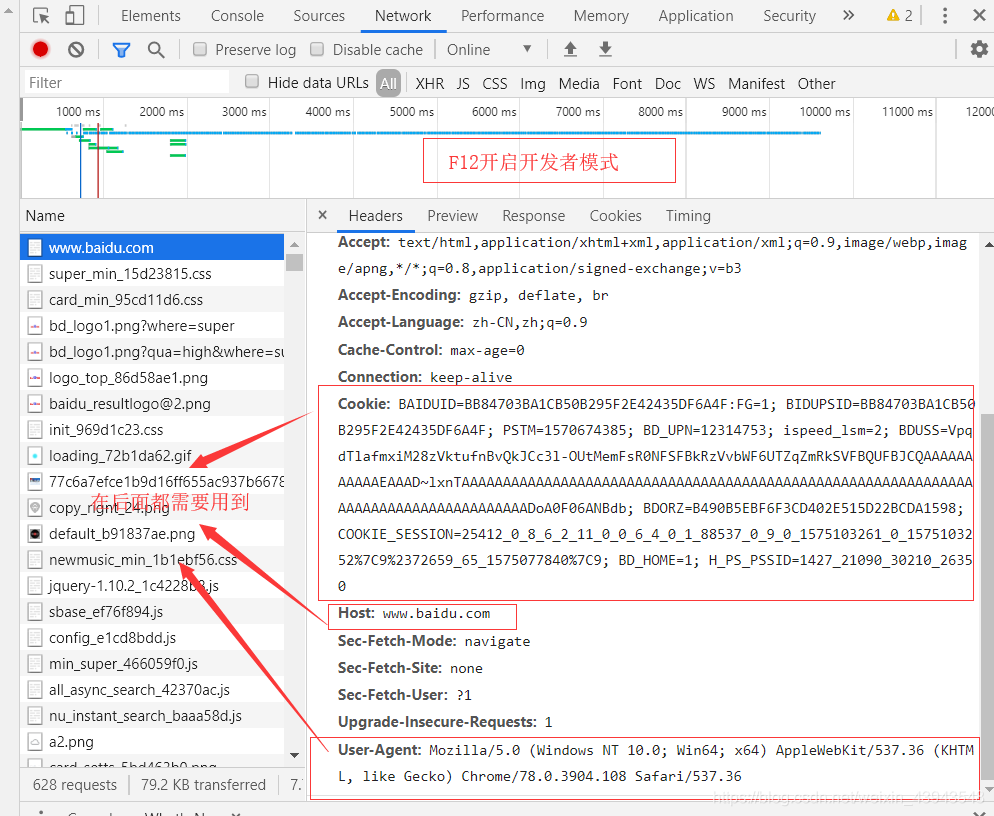
2、對網頁的解析(百度www.baidu.com)
按F進入坦克...
額,不是 按F12進入開發者模式
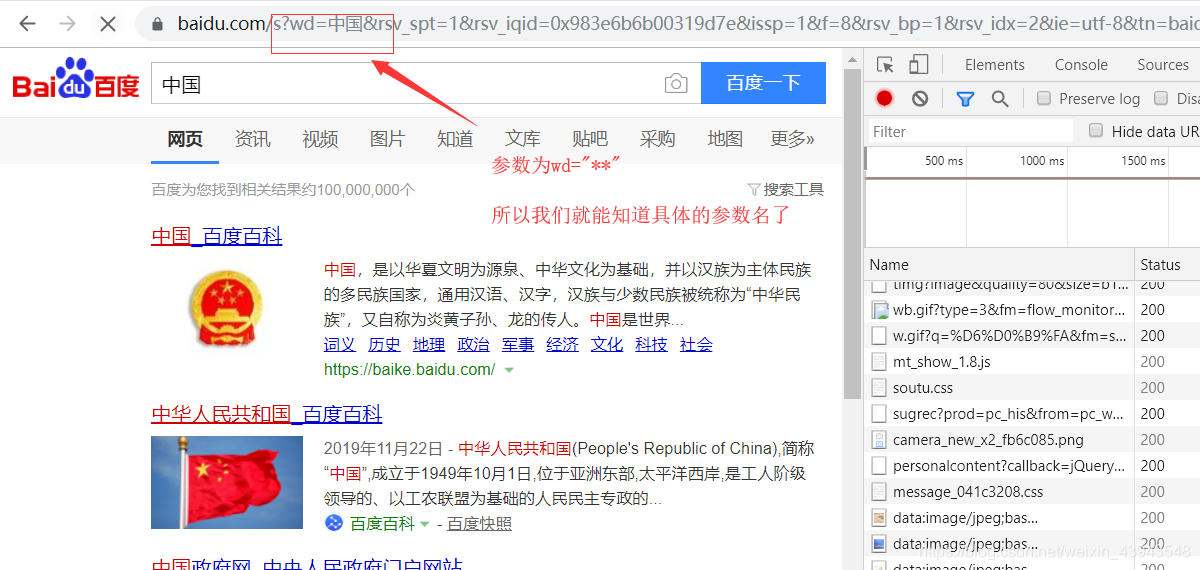
搜尋"中國"
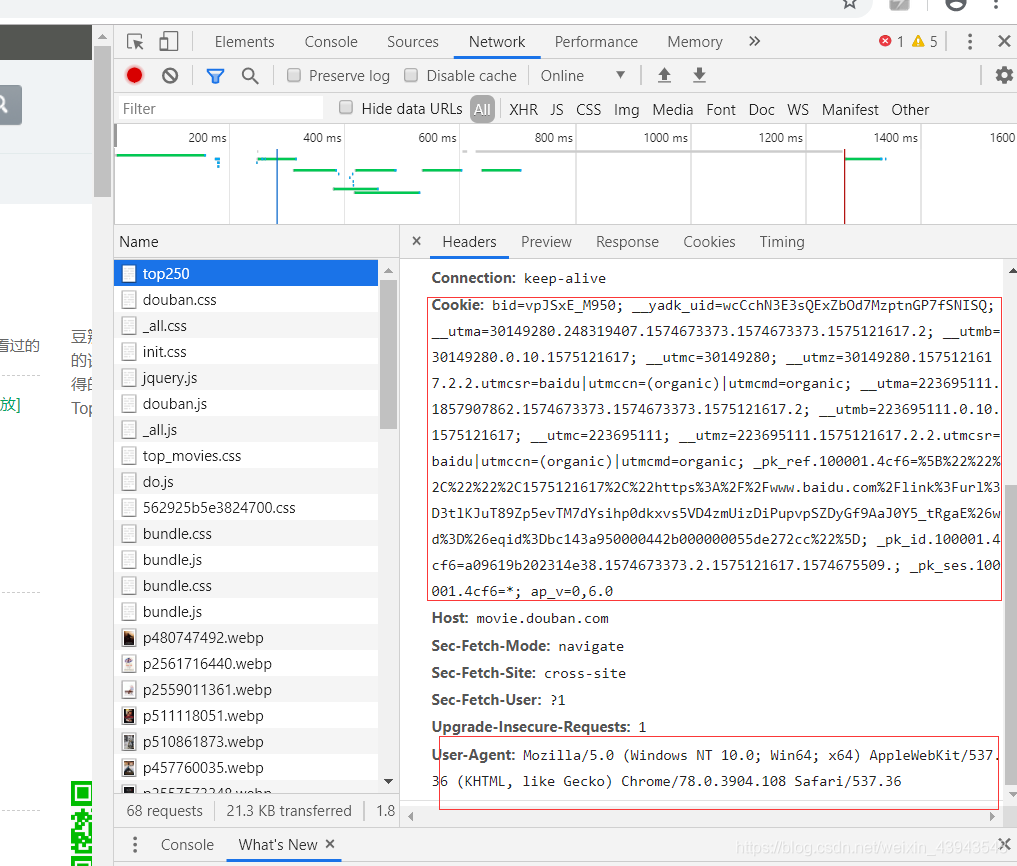
3、開始爬取(嘿嘿,因為本人感覺一個一個放上去忒麻煩了吧,一張圖給你解決)
其實有很多註解了的,多看看,當然對一個網頁的分析尤為重要
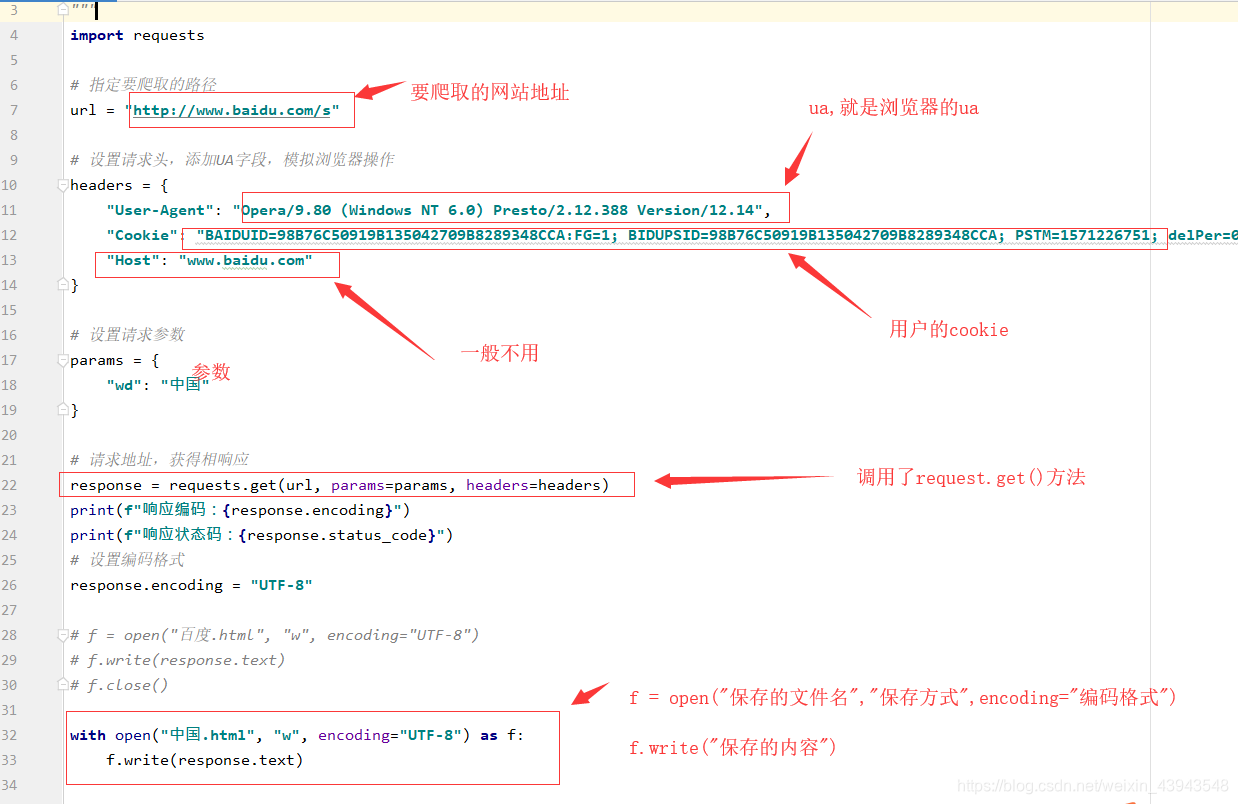
具體程式碼實現:
import requests
# 標明要請求的路徑
url = "http://www.baidu.com/s?"
headers = {
"Cookie": "BAIDUID=BB84703BA1CB50B295F2E42435DF6A4F:FG=1; BIDUPSID=BB84703BA1CB50B295F2E42435DF6A4F; PSTM=1570674385; BD_UPN=12314753; ispeed_lsm=2; BDUSS=VpqdTlafmxiM28zVktufnBvQkJCc3l-OUtMemFsR0NFSFBkRzVvbWF6UTZqZmRkSVFBQUFBJCQAAAAAAAAAAAEAAAD~lxnTAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAADoA0F06ANBdb; pgv_pvi=5531878400; COOKIE_SESSION=98297_6_9_8_4_26_0_3_8_7_10_8_18582_21681_0_0_1574259377_1574259241_1574591094%7C9%2321663_55_1574259212%7C9; BD_HOME=1; H_PS_PSSID=1427_21090_29567_29221_26350"
,
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)"
, "Host": "www.baidu.com"
}
params = {
"wd": "中國"
}
# 得到請求後的響應
response = requests.get(url,params=params,headers=headers)
response.encoding = "UTF-8"
print(f"響應的編碼:{response.encoding}")
print(f"響應的狀態碼:{response.status_code}")
print(response.text)
with open("中國.html", "w", encoding="UTF-8") as f:
f.write(response.text)
* 擴充套件內容(爬取top250的網頁)
因為重點程式碼都在上面講了,所以就放如何解析網頁;
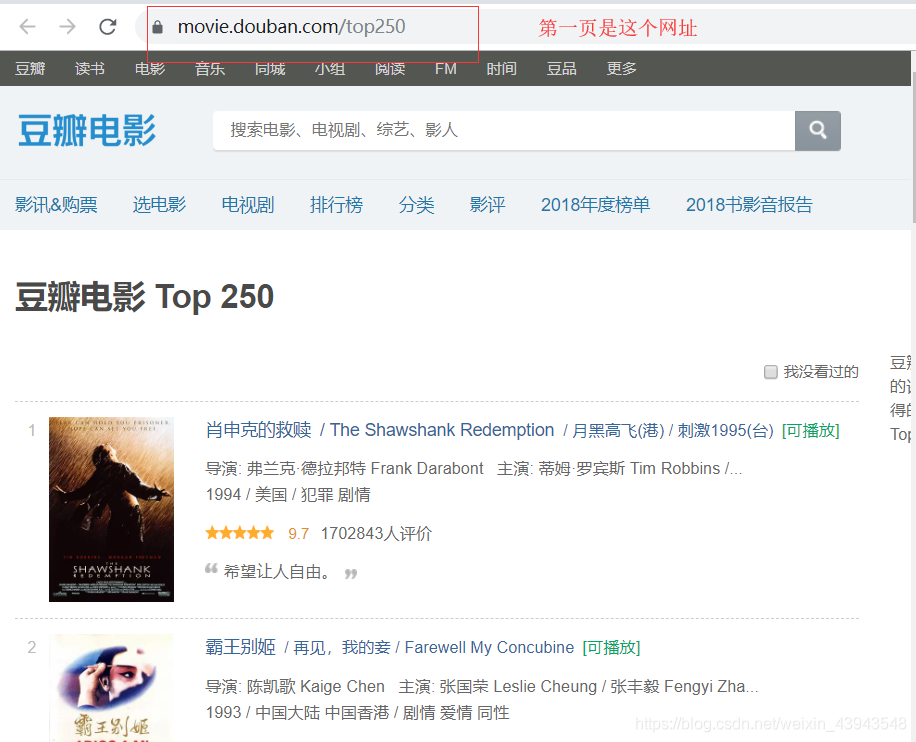
第一頁的資料
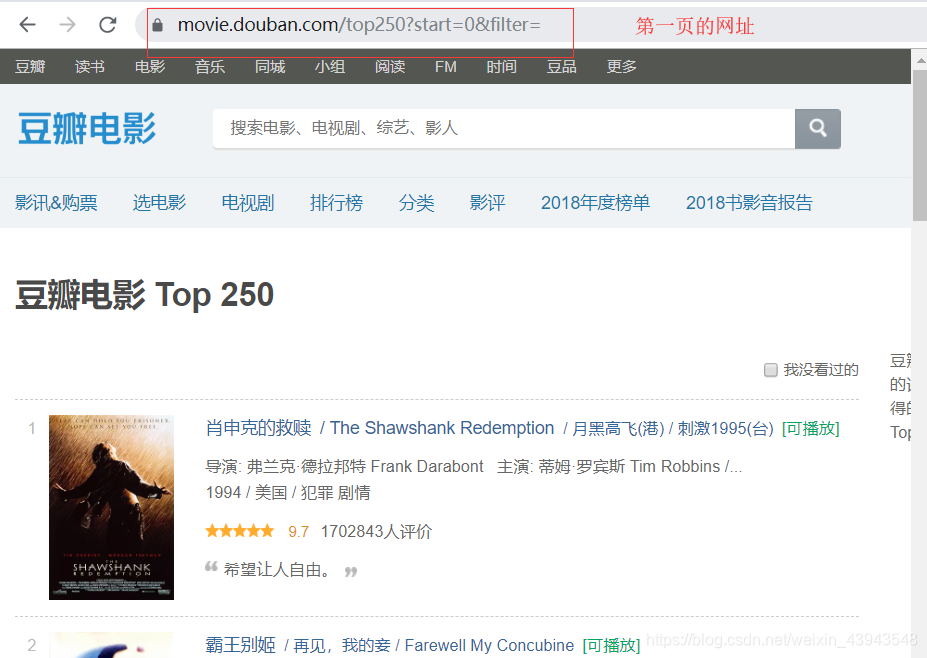
第一頁的猜測網址:結果沒問題。
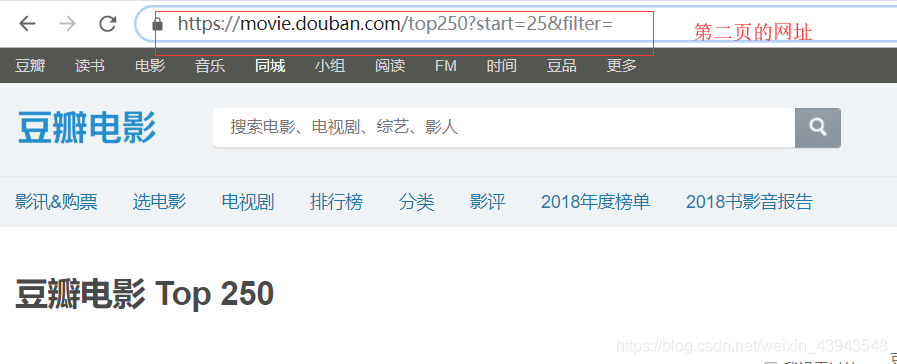
可以直接點選第二頁就看看網址,
然後就可以分析分析網址了
所以我們的一個程式碼就是這個
"""
爬取豆瓣電影TOP250,分頁儲存電影資料
"""
import requests
import time
headers = {
"User-Agent": "Opera/9.80 (Windows NT 6.0) Presto/2.12.388 Version/12.14"
}
for i in range(10):
url = f"https://movie.douban.com/top250?start={i*25}"
response = requests.get(url, headers=headers, verify=False)
print(response.status_code)
if response.status_code == 200:
# 獲取網頁資料
with open(f"第{i+1}頁.txt", "w", encoding="UTF-8") as f:
f.write(response.text)
print(f"{url} 儲存成功")
time.sleep(2)
後記
爬蟲重點在於分析
如果感覺本章寫的還不錯的話,不如。。。。。(~ ̄▽ ̄)~ ,(´▽`ʃ