
Ubuntu16.04環境下搭建Hadoop3.0.3偽分散式叢集
最近剛好趕上雙11騰訊促銷,於是搶購了一個8核16G記憶體的雲伺服器,加上業務上需要用到hadoop,hive,於是想搭建搭建一個hadoop分散式叢集,但是限於自己手頭上伺服器數量不多,因此打算先搭建一個hadoop偽分散式叢集。
首先介紹一下我的安裝環境:
(1)java version

(2)hadopp version

接下來,開始我的環境搭建之旅,由於在上學期間已經搭建過,所以這裡就不再很詳細的闡述,只是記錄重要的關鍵點。
目錄
(1)建立hadoop使用者
其實,完全可以用root使用者來操作hadoop的,但是畢竟root的許可權太高了,我們還是要令建立一個專門來管理hadoop的使用者,這裡就取名叫hadoop 。(以下是root模式下操作的)
useradd -m hadoop -s /bin/bash這條命令建立了可以登入的hadoop使用者,並使用/bin/bash作為shell。
接著使用如下命令設定密碼,可簡單的設定為hadoop,按提示輸入兩次密碼:
sudo passwd hadoop可為hadoop使用者增加管理員許可權,方便部署,避免一些對新手來說比較棘手的許可權問題
adduser hadoop sudo至此已經建立好了hadoop使用者
(2)ssh免密登陸
使用su hadoop 切換到使用者hadoop
su hadoop切換到hadoop使用者後,先更新一些apt,後續會使用apt安裝軟體,如果沒更新可能有一些軟體安裝不了。按ctrl+alt+t開啟終端視窗或者使用xshell建立遠端連線,執行如下命令:
sudo apt-get update叢集,單節點模式都需要用到SSH登入(類似於遠端登入,你可以登入某臺Linux主機,並且在上面執行命令),Ubuntu預設已安裝了SSH client,此外還需要安裝SSH server:
sudo apt-get install openssh-server安裝後,可以使用命令登入本機:
ssh localhost此時會有如下提示(SSH首次登陸提示),輸入yes。然後按提示輸入密碼hadoop,這樣就可以登入到本機。

但這樣登入是需要每次輸入密碼的,我們需要配置成SSH無密碼登入比較方便。
首先推出剛才的ssh,就回到了原先的終端視窗,然後利用ssh-keygen生成金鑰,並將金鑰加入到授權中:
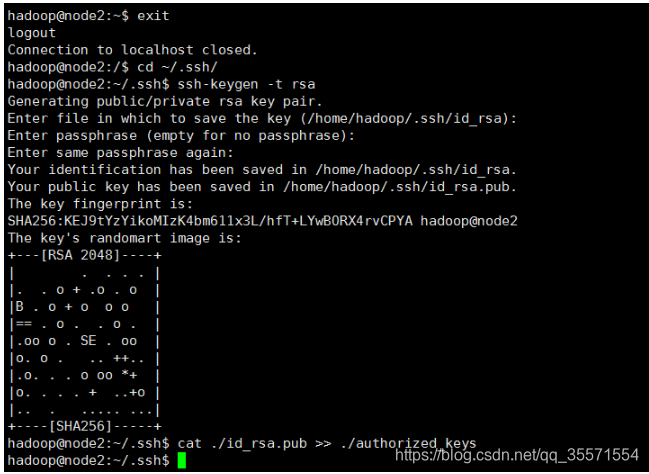
exit 退出剛才的ssh localhost
cd ~/.ssh/ 若沒有該目錄,請執行一次ssh localhost
ssh-keygen -t rsa 會有提示,都按回車就可以
cat ./id_rsa.pub >> ./authorized_keys 加入授權
註釋:~的含義
在Linux中,~代表的是使用者的主資料夾,即”/home/使用者名稱”這個目錄,如你的使用者名稱為hadoop,則~就代表”/home/hadoop”。此外,命令中的#後面的文字是註釋,只需要輸入前面命令即可。此時再用ssh localhost命令,無需輸入密碼就可以直接登入了,如下圖所示。
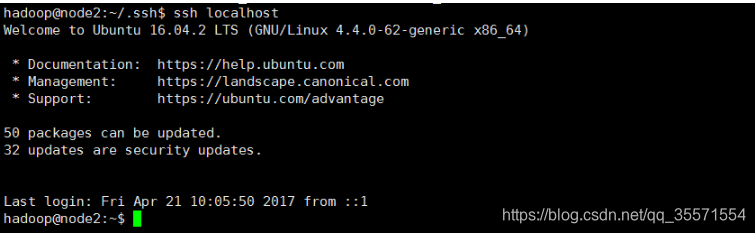
需要注意的一點:
以上只是給hadoop使用者配置了免密登陸,但是root使用者沒有,如果後續想通過root使用者來管理hadoop,這裡建議在root使用者模式下,重複上述ssh免密的過程,具體如下:
1、從hadoop模式進入到root模式
sudo su2、配置免密ssh
cd ~/.ssh/ 若沒有該目錄,請執行一次ssh localhost
ssh-keygen -t rsa 會有提示,都按回車就可以
cat ./id_rsa.pub >> ./authorized_keys 加入授權3、ssh localhost看需不需要密碼來驗證
(2)安裝java環境
這裡就不再贅述。注意jdk版本保持在1.8以上。
(3)安裝hadoop3.0.3
下載完hadoop檔案後一般可以直接使用。我們選擇將Hadoop安裝至/usr/local/中:
sudo tar -zxf ~/Downloads/hadoop-2.7.3.tar.gz -C /usr/local #解壓到/usr/local中
cd /usr/local/
sudo mv ./hadoop-2.7.3/ ./hadoop #將資料夾名改為hadoop
sudo chown -R hadoop ./hadoop #修改檔案許可權 這一步一定要做,因為許可權很重要
Hadoop解壓後即可使用。輸入如下命令來檢查Hadoop是否可用,成功則會顯示Hadoop版本資訊:
cd /usr/local/hadoop
./bin/hadoop version這樣操作還是不方便,我們可以hadoop命令配置成全域性的.
vim /etc/profile新增以下hadoop配置資訊
#hadoop
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/sbin
export PATH=$PATH:$HADOOP_HOME/bin
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
是配置的命令生效:
source /etc/profile 如下圖所示:
(4)搭建hadoop偽分散式叢集
Hadoop可以在單節點上以偽分散式的方式執行,Hadoop程序以分離的java程序來執行,節點既作為NameNode也作為DataNode,同時,讀取的是HDFS中的檔案。
需要對以下檔案進行修改:
1、hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/hadoop/data/dfs/name</value>
<final>true</final>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop/data/dfs/data</value>
</description>
<final>true</final>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.http.address</name>
<value>0.0.0.0:9870</value>
</property>
<property>
<name>fs.checkpoint.dir</name>
<value>/usr/local/hadoop/data/dfs/testdir</value>
</property>
<property>
<name>fs.checkpoint.edits.dir</name>
<value>/usr/local/hadoop/data/dfs/testdir</value>
</property>
<property>
<name>ipc.maximum.data.length</name>
<value>134217728</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
2、core-site.xml檔案(注意建立data資料夾以及裡面的資料夾,具體見下面配置路徑)
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9820</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/data/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>
3、hadoop-env.sh,新增以下兩行程式碼
export JAVA_HOME=/usr/jvm/java
export HADOOP_HOME=/usr/local/hadoop
4、以下四個檔案配置如下資訊(主要是給root使用者操作)
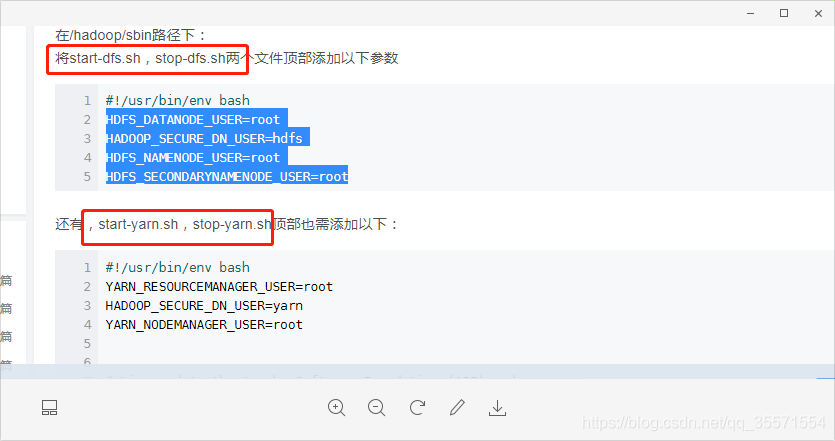
(5)驗證是否安裝成功
1、執行NameNode的格式化
hdfs namenode -format成功的話,會看到”successfully formatted”和”Exitting with status 0”的提示,若為”Exitting with status 1”則是處錯。
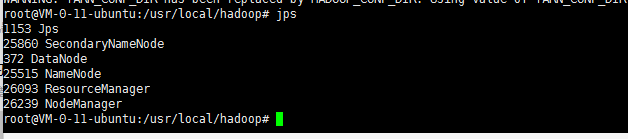
2、開啟所有的程序
sbin/start-dfs.sh3、jps檢視當前程序是否都啟動了(主要是如下截圖的6種)
4、web頁面檢視是否啟動,瀏覽器輸入IP+埠,出現如下截圖表示成功。
至此hadoop3x的偽分散式環境搭建完畢,hive的環境搭建在我的博文其他篇章,歡迎閱讀.
參考文章;