
Centos7上搭建hadoop3.0.3完全分散式 (.tar.gz)
這裡搭建的是3個節點的完全分散式,即1個nameNode,2個dataNode,分別如下:
master nameNode 192.168.0.249
node1 dataNode 192.168.0.251
node2 dataNode 192.168.0.252
1.首先建立好一個CentOS虛擬機器,將它作為主節點我這裡起名為master,起什麼都行,不固定要求
2.VMware中開啟虛擬機器,輸入java -version,檢查是否有JDK環境,不要用系統自帶的openJDK版本,要自己安裝的版本
3.輸入 firewall-cmd --state,若防火牆處於running狀態,則關閉防火牆
systemctl stop firewalld.service 關閉防火牆
systemctl disable firewalld.service 禁用防火牆
4.輸入mkdir /usr/local/hadoop 建立一個hadoop資料夾
5.將hadoop-3.0.3.tar.gz放到剛建立好的hadoop資料夾中
6.進入hadoop目錄,輸入tar -xvf hadoop-3.0.3.tar.gz 解壓tar包
[[email protected] sbin]# cd /usr/local/hadoop/
[[email protected]hadoop]# ls
hadoop-3.0.3 hadoop-3.0.3.tar.gz
7.輸入 vi /etc/profile,配置環境變數。加入如如下內容
export HADOOP_HOME=/usr/local/hadoop/hadoop-3.0.3
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin
eg:
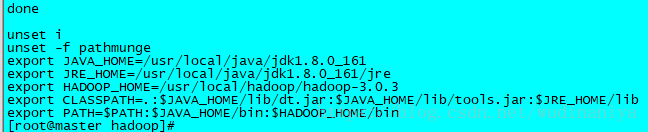
8. 輸入 souce /etc/profile ,使環境變數改動生效
9.任意目錄輸入hado,然後按Tab,如果自動補全為hadoop,則說明環境變數配的沒問題,否則檢查環境變數哪出錯了
[[email protected] 10.建立3個之後要用到的資料夾,分別如下:
mkdir /usr/local/hadoop/tmp
mkdir -p /usr/local/hadoop/hdfs/name
mkdir /usr/local/hadoop/hdfs/data
建立結果如下:
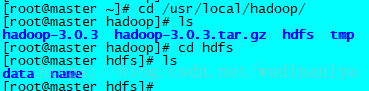
11.進入hadoop-3.0.3解壓後的 /etc/hadoop 目錄,裡面存放的是hadoop的配置檔案,接下來要修改裡面一些配置檔案
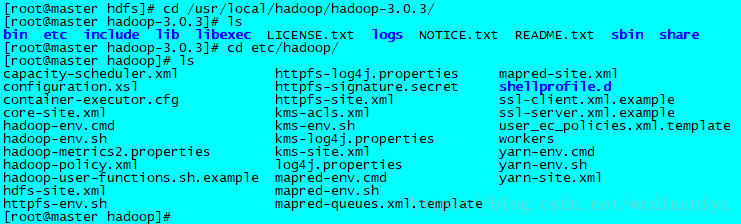
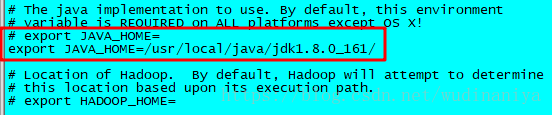
12. 有兩個 .sh 檔案,需要指定一下java的目錄,首先輸入 vi hadoop-env.sh 修改配置檔案
[[email protected] hadoop]# vi hadoop-env.sh將原有的JAVA_HOME註釋掉,根據自己的JDK安裝位置,精確配置JAVA_HOME如下,儲存並退出
export JAVA_HOME=/usr/local/java/jdk1.8.0_161/
13. 輸入 vi yarn-env.sh 修改配置檔案
[[email protected] hadoop]# vi yarn-env.sh加入如下內容,指定JAVA_HOME,儲存並退出
export JAVA_HOME=/usr/local/java/jdk1.8.0_161/

14. 輸入 vi core-site.xml 修改配置檔案
[[email protected] hadoop]# vi core-site.xml 在configuration標籤中,新增如下內容,儲存並退出,注意這裡配置的hdfs:master:9000是不能在瀏覽器訪問的
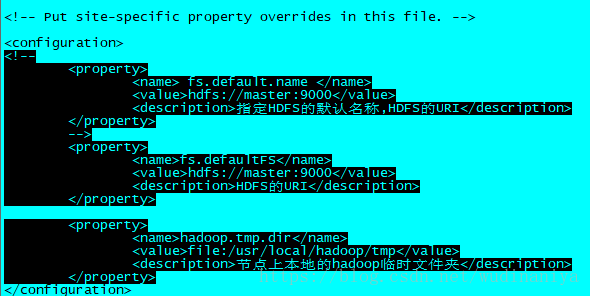
<!--
<property>
<name> fs.default.name </name>
<value>hdfs://master:9000</value>
<description>指定HDFS的預設名稱,HDFS的URI</description>
</property>
-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
<description>HDFS的URI</description>
</property><property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>節點上本地的hadoop臨時資料夾</description>
</property>
15. 輸入 vi hdfs-site.xml 修改配置檔案
[[email protected] hadoop]# vi hdfs-site.xml在configuration標籤中,新增如下內容,儲存並退出
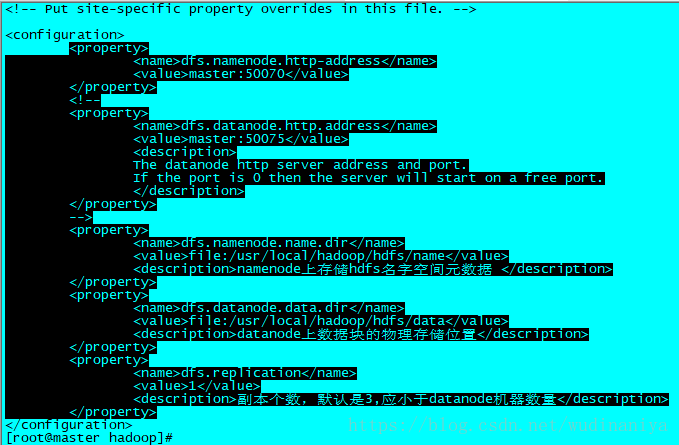
<property>
<name>dfs.namenode.http-address</name>
<value>master:50070</value>
</property>
<!--
<property>
<name>dfs.datanode.http.address</name>
<value>master:50075</value>
<description>
The datanode http server address and port.
If the port is 0 then the server will start on a free port.
</description>
</property>
-->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/hdfs/name</value>
<description>namenode上儲存hdfs名字空間元資料 </description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/hdfs/data</value>
<description>datanode上資料塊的物理儲存位置</description>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
<description>副本個數,預設是3,應小於datanode機器數量</description>
</property><!--後增,如果想讓solr索引存放到hdfs中,則還須新增下面兩個屬性-->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
16. 輸入 vi mapred-site.xml 修改配置檔案
[[email protected] hadoop]# vi mapred-site.xml在configuration標籤中,新增如下內容,儲存並退出

<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>指定mapreduce使用yarn框架</description>
</property>
17. vi yarn-site.xml 修改配置檔案
[[email protected] hadoop]# vi yarn-site.xml在configuration標籤中,新增如下內容,儲存並退出

<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
<description>指定resourcemanager所在的hostname</description>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>
NodeManager上執行的附屬服務。
需配置成mapreduce_shuffle,才可執行MapReduce程式
</description>
</property>
18. 輸入 vi workers 修改配置檔案(老版本是slaves檔案,3.0.3 用 workers 檔案代替 slaves 檔案)
[[email protected] hadoop]# pwd
/usr/local/hadoop/hadoop-3.0.3/etc/hadoop
[[email protected] hadoop]# vi workers 將localhost刪掉,加入如下內容,即dataNode節點的主機名
node1
node2

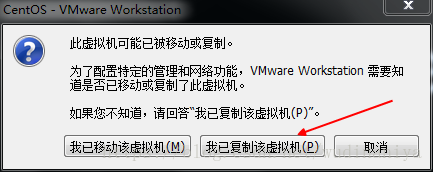
19. 將虛擬機器關閉,再複製兩份虛擬機器,重新命名為node1,node2,注意這裡一定要關閉虛擬機器,再複製
20. 將3臺虛擬機器都開啟,後兩臺複製的虛擬機器開啟時,都選擇“我已複製該虛擬機器”
21. 在master機器上,輸入vi /etc/hostname,將localhost改為master,儲存並退出

22. 在node1機器上,輸入 vi /etc/hostname,將localhost改為node1,儲存並退出
23. 在node2機器上,輸入 vi /etc/hostname,將localhost改為node2,儲存並退出

24. 在三臺機器分別輸入 vi /etc/hosts 修改檔案,其作用是將一些常用的網址域名與其對應的IP地址建立一個關聯,當用戶在訪問網址時,系統會首先自動從Hosts檔案中尋找對應的IP地址
三個檔案中都加入如下內容,儲存並退出,注意這裡要根據自己實際IP和節點主機名進行更改,IP和主機名中間要有一個空格
192.168.0.249 master
192.168.0.251 node1
192.168.0.252 node2

25. 配置三臺機器間的免密登入ssh (搭hadoop必須要配免密登入)
26. 如果node節點還沒有hadoop,則master機器上分別輸入如下命令將hadoop複製
scp /usr/local/hadoop/* [email protected]:/usr/local/hadoop
scp /usr/local/hadoop/* [email protected]:/usr/local/hadoop
27. 在master機器上,任意目錄輸入 hdfs namenode -format 格式化namenode,第一次使用需格式化一次,之後就不用再格式化,如果改一些配置檔案了,可能還需要再次格式化
hdfs namenode -format格式化完成。
28. 在master機器上,進入hadoop的sbin目錄,輸入 ./start-all.sh 啟動hadoop(若只配了hdfs,則可以 輸入 ./start-dfs.sh 啟動hdfs)
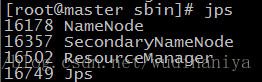
[[email protected] sbin]# ./start-dfs.sh 29. 輸入jps檢視當前java的程序,
該命令是JDK1.5開始有的,作用是列出當前java程序的PID和Java主類名,nameNode節點除了JPS,還有3個程序,啟動成功
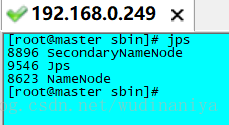
若為了只使用hdfs而只配了hdfs,採用 ./start-dfs.sh 啟動, 則
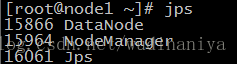
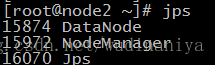
30. 在node1機器和node2機器上分別輸入 jps 檢視程序如下,說明配置成功
若只配置了hdfs, 採用 ./start-dfs.sh 啟動。 則
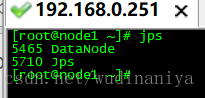
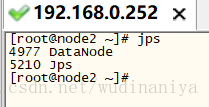
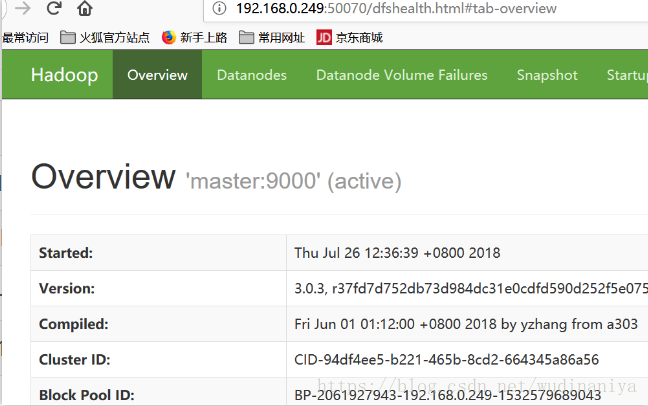
31. 在瀏覽器訪問nameNode節點的8088埠和50070埠可以檢視hadoop的執行狀況
32. 在master機器上,進入hadoop的sbin目錄,輸入 ./stop-all.sh 關閉hadoop 或 輸入 ./stop-dfs.sh 關閉dfs
遇到的坑:Attempting to operate on hdfs namenode as root
寫在最前注意:
1、master,slave都需要修改start-dfs.sh,stop-dfs.sh,start-yarn.sh,stop-yarn.sh四個檔案
2、如果你的Hadoop是另外啟用其它使用者來啟動,記得將root改為對應使用者
HDFS格式化後啟動dfs出現以下錯誤:
[[email protected] sbin]# ./start-dfs.sh
Starting namenodes on [master]
ERROR: Attempting to operate on hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
Starting datanodes
ERROR: Attempting to operate on hdfs datanode as root
ERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation.
Starting secondary namenodes [slave1]
ERROR: Attempting to operate on hdfs secondarynamenode as root
ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting operation.
在/usr/local/hadoop/hadoop-3.0.3/sbin路徑下:
將start-dfs.sh,stop-dfs.sh兩個檔案頂部新增以下引數
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root還有,start-yarn.sh,stop-yarn.sh頂部也需新增以下:
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root修改後重啟 ./start-dfs.sh,成功!
相關推薦
Centos7上搭建hadoop3.0.3完全分散式 (.tar.gz)
這裡搭建的是3個節點的完全分散式,即1個nameNode,2個dataNode,分別如下: master nameNode 192.168.0.249 node1 dataNode 192.168.0.251 node2 dataNode
Ubuntu16.04環境下搭建Hadoop3.0.3偽分散式叢集
最近剛好趕上雙11騰訊促銷,於是搶購了一個8核16G記憶體的雲伺服器,加上業務上需要用到hadoop,hive,於是想搭建搭建一個hadoop分散式叢集,但是限於自己手頭上伺服器數量不多,因此打算先搭建一個hadoop偽分散式叢集。 首先介紹一下我的安裝
CentOS7下搭建hadoop2.7.3完全分散式
這裡搭建的是3個節點的完全分散式,即1個nameNode,2個dataNode,分別如下: CentOS-master nameNode 192.168.11.128 CentOS-node1 dataNode 192.168.11.131 Cen
Centos7.5搭建Hadoop2.8.5完全分散式叢集
一、基礎環境設定 1. 準備4臺客戶機(VMware虛擬機器) 系統版本:Centos7.5 192.168.208.128 ——Master 192.168.208.129 ——Slaver-1 192.168.208.130 ——Slaver-2 192.168.208.130 ——Slaver-3
Linux核心0.11完全註釋(修正版) --讀書筆記(1)
RTFSC 閱讀0.11核心版本的原因: 適合作業系統初學者的入門學習起點 閱讀早期核心的好處: 簡化的核心程式碼,避免現有核心的複雜性,能夠透徹的說明問題 -- Leland
在VM虛擬機器上搭建Hadoop2.7.3+Spark2.1.0完全分散式叢集
1.選取三臺伺服器(CentOS系統64位) 114.55.246.88主節點 114.55.246.77 從節點 114.55.246.93 從節點 之後的操作如果是用普通使用者操作的話也必須知道root使用者的密碼,因為有些操作是得
大資料之(1)Centos7上搭建全分散式Hadoop叢集
本文介紹搭建一個Namenode兩個DataNode的Hadoop全分散式叢集的全部步驟及方法。具體環境如下: 一、環境準備 3個Centos7虛擬機器或者3個在一個區域網內的實際Centos7機器,機器上已安裝JDK1.8,至於不會安裝Centos7或者JDK1.8的同
Hadoop從入門到精通系列之--3.完全分散式環境搭建
目錄 一 什麼是完全分散式 二 準備伺服器 三 叢集分發指令碼 3.1 scp(secure copy)安全拷貝 3.2 rsync遠端同步 3.3 叢集分發指令碼 四 叢集規劃 4.1 規劃思想 4.2 具體配置 4.3 ssh免密登陸 一 什麼
Hbase2.1.0 on Hadoop3.0.3叢集(基於CentOS7.5)
完全分散式叢集搭建請移步: 在CentOS7.5上搭建Hadoop3.0.3完全分散式叢集 當前CentOS,JDK和Hadoop版本: [[email protected] ~]# cat /etc/redhat-release CentOS Linux rel
Centos7搭建redis4.0.9偽分散式叢集環境
使用系統是Centos7 redis版本:4.0.9 gem版本:4.0.0 ruby版本:2.5.1 1.下載redis 上圖是從redis官網扒下來的,不過單機版安裝使用也沒啥難度,就不談了,make的時候要有C++編譯器,可以get set啥的就算是裝好了 yum
基於CentOS6.5系統Hadoop2.7.3完全分散式叢集搭建詳細步驟
前言:本次搭建hadoop叢集使用虛擬機器克隆方式克隆slave節點,這樣做可以省去很多不必要的操作,來縮短我們的搭建時間。 一、所需硬體,軟體要求 使用 VMWare構建三臺虛擬機器模擬真實物理環境 作業系統:CentOS6.5 二、必備條件 hadoop搭建需
【Zabbix】在CentOS7上安裝Zabbix3.0
led spl clas connector 不同數據庫 自由 sel 做了 之前 Zabbix安裝 首先說明一下,本文主要參考了【http://www.linuxidc.com/Linux/2016-11/137030.htm】和【http://www.cnblog
關於 mysql2 -v '0.3.21'(CentOS7.3)
ssi nec rvm plugin ren single local -o for in 個人由於沒有安裝mysql而是裝的MariaDB,所以網上說安裝mysql,故沒有采用,經查閱資料後,詳細情況如下: Gem時報錯: [[email protected]
在Centos7上搭建局域網的yum源倉庫
不支持 src 安裝包 cto onf 自己 是否 連接 創建文件 1.#輸入命令rmp -q -vsftpd,查看是否安裝了該包。 2.#創建掛載點,把光盤掛載到該點 3.#使用命令用rpm-ivh 安裝vsftpd安裝包 4.#啟動vsftpd服務,設為下次開機
Centos7上搭建Racktables
linux centos7 會裝不會用=。= 1.介紹 Racktables是一個用來管理機房資產的開源工具,可以用來管理成百上千臺的服務器及更多的IP和MAC地址。適用於機房和數據中心的服務器管理 2.安裝配置 安裝教程參考:https://github.com/RackTables/rackta
CentOS7.2 搭建 Jenkins2.107.3
CentOS7.2 Jenkins Jenkins 簡介Jenkins?是一個開源軟件項目,是基於Java開發的一種持續集成工具,用於監控持續重復的工作,旨在提供一個開放易用的軟件平臺,使軟件的持續集成變成可能。Java 安裝 yum -y install java-1.8.0-openjdk-dev
centos7上搭建DHCP服務器
centos7首先打開一個虛擬機,在虛擬機上執行“rpm -q dhcp”命令檢查是否有安裝DHCP安裝包, 在虛擬機上插入裝系統的系統盤並且掛載上,插入光盤方法按下面圖片上順序操作“虛擬機→設置→CD/DVD→瀏覽→找到存放系統盤的位置→打開→已連接→確定”此操作先做或者進入系統後在做效果一樣。如圖所示:
linux,centos7上搭建LVS負載均衡
for rpm -ivh /bin/bash 同步 tab 創建 log BE .rpm 在linux,centos7上搭建LVS負載均衡 實前準備 準備五臺虛擬機 四臺centos7 一臺做調度 一臺做nfs緩存 兩臺做wed群集 一臺windows7 開始逐個配置
centos7+上搭建cobblerweb遠程快速裝機
訪問 輕量級 acf net 管理系統 重啟 status 命令 裝系統 Cobbler介紹 Cobbler(補鞋匠)是一個Linux服務器快速網絡安裝的服務,而且在經過調整也可以支持網絡安裝windows。該工具使用python開發,小巧輕便(才15k行python代碼
高效實用,在centos7上搭建MFS分布式文件系統
使用 原理 source 網絡 組成 tar zxvf sha 變量 系統搭建 MFS原理: MFS是一個具有容錯性的網絡分布式文件系統,他把數據分散存放在多個物理服務器上,而呈現給用戶的則是一個統一的資源 MFS文件系統組成: 1、元數據服務器(master)