
為什麼說LAXCUS顛覆了我的大資料使用體驗
切入正題前,先做個自我介紹。
本人是從業三年的大資料小碼農一枚,在帝都一家有點名氣的廣告公司工作,同時兼著大資料管理員的職責。
平時主要的工作是配合業務部門,做各種廣告大資料計算分析工作,然後製成各種圖表,提供給領導和客戶,做為他們業務決策的輔助依據。
因為敏感性和安全的原因,我們的廣告資料都是儲存在公司自己的伺服器裡,而不是雲上,並且做了各種隔離,防止有人盜取。大資料平臺用的是目前流行的OpenStack + Hadoop譜系組合。
這套軟體組合雖然時不時給我出點難題,但是好在部門裡還有兩位技術大牛幫忙盯著,有了問題都能在他們的輔導下及時排除,所以也還湊合著用。
今年三月,因為一位領導的推薦,開始試用一套叫“Laxcus大資料作業系統”的開源軟體。半年使用下來,結果完全出乎我們的意料,不光使用操作簡單,而且管理維護和開發方面也很完善,少了許多開發和維護工作,感覺整體大大超越了OpenStack/Hadoop組合。
這個月初,我們部門先進行了一次內部投票,最後經領導拍板同意,決定把我們的廣告大資料業務全部轉移到Laxcus上去執行。現在,我們部門正在做後續工作,把原來在OpenStack/Hadoop上的廣告業務,逐步遷移到Laxcus大資料作業系統平臺上。
在這次內部投票中,我投了贊成票,如果說問我為什麼支援這個出力還要給自己找麻煩的決定,我想如果做過大資料管理員的兄弟,一定能夠理解我這個選擇。
比如,你剛上手部署叢集的時候,一定有這樣的經歷:手頭一堆軟體模組,面前成堆的伺服器,藉著從書本和網上學來的星星點點的知識,努力理解著各個模組之間相似又不盡相同的功能,感覺象老虎咬刺蝟--無從下口。
好吧,終於咬著牙去嘗試了,小心翼翼改配置,調引數,費了九牛二虎之力,總算把幾個模組連上了,也跑通了,突然,系統報警,一個節點崩潰,流程中斷!趕緊去網上找資料,論壇去求助,等了好久,有了回覆,照著去做,嗯,問題解決了,好了,OK,繼續下一個...還是不行,暈!再試試...
如果說我不想做管理員,轉行做大資料程式設計師,那麼需要了解、理解的技術,花費的精力就更多了。不止是這些軟體模組框架的功能、特點、運作流程,還要學習使用各種程式語言,貌似很神祕很牛X的演算法,形形色色的開發規則和技巧。
幾個月閉門苦讀下來,終於寫出一段DEMO,編譯也通過了,部署到叢集裡,啟動執行,故障!心裡一萬個草泥馬狂奔!...冷靜下來,開啟IDE,一行行尋找故障點排錯...
這些都是我的經歷,我想做過大資料叢集管理和程式開發工作的,這些淚噴的經歷一定不比我少。實際上,這些還只是開始,以後隨著工作業務逐漸展開,將會有更多坑冒出來。比如,怎樣根據公司的業務需求,在幾個功能相近又不盡相同的模組裡,選擇最適合的模組?模組與模組之間怎麼搭配組合執行?怎樣在模組、網路、業務之間進行調整優化,提高資料處理能力?發生故障後,怎樣快速判斷出故障點然後恢復叢集執行?這些貼近實戰的工作,都需要一點點積累經驗知識,慢慢掌握。
而自從轉向Laxcus大資料作業系統平臺後,我發現,這些原本在Hadoop頻頻出現的坑,到了Laxcus已經被填平了。叢集管理員和程式設計師,只要掌握一套介面,就可以管理大資料叢集和進行程式開發,這比Hadoop譜系的多介面管理開發方案簡單太多,我的整個學習曲線相當平緩,到現在也沒有出現任何不可解決的問題。由於我不是技術專家,對Laxcus的認識有限,不敢妄談很深入的技術細節,就想以一個普通大資料管理員和程式設計師的身份,根據我半年多使用Laxcus的經驗,從正反兩方面,從儘量公平的角度,談談我的Laxcus體驗感受。先從它的優點說起。
優點
1. 功能全棧整合
如果說Laxcus最鮮明的特點,應該就是它集成了雲端計算和大資料所需要的主要功能,而且是從底層開始做起的全棧技術實現。這應該是這個產品最牛的地方。目前能做到這種技術水平的雲端計算大資料軟體,我還沒有發現第二個。
我曾經仔細讀過Laxcus的產品論文和原始碼,如果拿來對標OpenStack/Hadoop的話,它的裡面其實包含著OpenStack的虛擬化和租戶管理,HDFS的分佈框架,Yarn的資源管理,Map/Reduce的分佈計算,HBase的儲存,ZooKeeper的分佈鎖,Spark的記憶體計算,Sqoop的資料轉換,Ambari的視覺化管理。
對於這些模組的使用,Laxcus的做法是,把它們的功能分散到不同型別的節點上去實現和處理,每類節點提供其中一種或者幾種,然後裝配起來組成一個叢集。Laxcus叢集是具備級聯關係的主從節點合集,下級節點註冊到上級節點,上級節點管理下級節點。執行過程中,上下級節點、同級節點之間會持續動態協調資源和工作狀態,形成一種"弱中心化的組織管理架構(Laxcus產品說明書原話)“。

如果問Laxcus的叢集構架對我們使用者有什麼好處,那就是,由於Laxcus在軟體層面已經做好了各個模組之間的組織封裝,省去了我們自己做搭配模組的協調對接工作,避免人工搭配過程中的出錯可能。還有就是因為模組在系統內部高度整合封裝的原因,它們之間的內聚性會更好,能夠避免很多因為相容導致的故障錯誤。反饋到運維上,則是降低了我們部門的維護成本,現在我一個人就可以完成整個大資料叢集的維護管理工作。
對比Laxcus和OpenStack/Hadoop這兩個產品風格,它們就好比是原裝車和組裝車的區別。Laxcus是原裝車,不需要使用者做任何準備工作,從4S店買來就可以直接上路,各種可能的問題也在出廠時降到最低。Hadoop是需要DIY的組裝車,使用者拿到手的是一堆配件,然後還需要有足夠的專業水平,知道如何調校、測試,才能把車子組裝起來,確保無誤後上路。雖然這種方式靈活性足夠高,也能有不錯效能,但是需要付出更多的學習和時間成本。
除了上面這些模組,Laxcus還有其他功能。比如它把SQL和儲存過程也整合進來了,這樣看Laxcus又是一個超大號的關係資料庫。還支援了中介軟體,在Laxcus裡,中介軟體有一個專門的名稱:分佈任務元件。如果說它和EJB這樣的中介軟體有什麼區別,那麼應該說EJB是為資料庫分解壓力提供中繼處理的產物,而分佈任務元件是有分佈理論和分佈系統支援、可以併發到成千上萬個節點執行的真分佈。所以Laxcus其實也是一箇中間件伺服器。
另外一些創新是其它大資料平臺沒有的。比如Laxcus能夠同時支援列儲存和行儲存兩種資料儲存方案,這個使用者需要同時處理OLAP和OLTP兩種資料業務時,就可以在一個平臺上完成了。還有為了彌補分佈環境CAP理論這個短板,Laxcus實現一種叫“可調CAP策略”的技術,讓使用者根據自己業務需要,來選擇解決CAP三選二的問題。
另外Laxcus有一個叫“跨賬號資源共享”的技術,解決了多個使用者之間,資料安全、私密性、共享之間的矛盾。我感覺這些技術都是挺重要的,雖然目前對我們公司的廣告資料業務不那麼重要。
Laxcus還有很多功能,因為我自己沒用過不熟悉的原因,這裡就不一一介紹。總之呢,Laxcus是一個龐大的體系,提供的功能非常全面,它把我們常用的各種資料處理需求和業務都整合進去了,幫我們省下很多功夫。剩下的事,就是按照Laxcus的要求,管理員管叢集,程式設計師碼程式碼,哎,又回到咱們碼農的起點。
2. 全命令操作
Laxcus是一個完全由命令驅動的系統。所有叢集管理和資料處理工作,都是用字元控制檯、圖形終端、驅動程式這三種互動介面,通過輸入字串語句的方式,轉義成命令,提交到叢集分散執行來完成。包括很複雜的分散式儲存和分散式計算工作,也是這樣處理。這是我感覺Laxcus和OpenStack/Hadoop很不一樣,而更像Linux的地方。其實我一直深度懷疑Laxcus的設計者是一個Linux粉,要不怎麼會想到這樣的招式?
對於命令這種人機互動設計,我的感受是,管理員管理叢集和使用者操縱資料的工作都簡單了,靈活性也不錯,稍微學習一下就能上手。另外,Laxcus還做了一個很貼心的設計:允許使用者定義私有命令。這些私有命令用專門的API支援,如果使用者想在Laxcus大資料叢集裡,為自己的業務開發某些個性化的功能,就按照Laxcus規範要求用這套API,把自己的業務編碼包裝進去,然後釋出上叢集。Laxcus會自動識別它們,和標準的命令一起被執行。
3. 穩定性超好
Laxcus是我使用過的大資料軟體裡,穩定性最好的一個,沒有之一!這套軟體從我們開始試執行到現在,還沒有發生宕機和故障停擺故障(因為停電造成的宕機除外),這和時不時給我找點麻煩的OpenStack/Hadoop這對組合相比,不能不說是一個奇蹟。我曾經仔細思考過這個問題,還看了Laxcus的原始碼,感覺應該和Laxcus的系統設計有直接關係。上面說過,因為OpenStack/Hadoop這對組合,各個模組之間是高度分離的,需要管理員來組合搭配它們,還需要程式設計師理解熟悉它們並且能夠正確程式設計,才能保證叢集穩定執行。
實際上,我在使用OpenStack/Hadoop的過程中,發現有很多的故障,就是由於我們對OpenStack/Hadoop不熟悉不理解和程式設計錯誤造成的。而Laxcus各個模組和功能介面之間是高度內聚的,不開放給使用者,我們無法直接呼叫操作它們(除非直接修改原始碼),這樣就直接避免了許多不必要的故障。
另外一個原因,按照Laxcus技術白皮書所說,Laxcus採用了兩個叫做“鬆耦合架構和負載自適應”的兩個關鍵技術。對於鬆耦合架構,它的官方解釋是:“為適應複雜分佈網路環境,可以臨時組織和動態調配的工作模型。在這個架構下,所有硬體裝置和軟體模組,以及其上執行的資料處理工作,都被視為服務。它們在獲得授權的情況下,可以自由的加入和退出,以離散、獨立、弱依賴的形態存在”。
這段描述不知大家聽懂沒,反正我不大懂。但是以我的使用理解,這個鬆耦合架構的優勢主要就是用非同步會話減少了資源佔用。因為在分佈計算過程中,每個節點時刻都會產生大量的網路連線和資料計算,非同步會話把很多同步完成的工作,切割成多段來處理。
它們只在需要的時候才產生連線和佔用計算機資源,不需要的時候就斷開網路和釋放資源,空出的網路通道和資源會留給其它業務。這樣就提高了計算機並行處理能力,改善了分佈計算裡最重要的資源使用佔用的問題。負載自適應這個技術,是解決計算機物理壓力和叢集負載不均衡的問題。
它能根據計算機和叢集執行中的負載狀況,自動調整負載比率。達到或者接近負載範圍會限載,超過就降載,強制所有業務在要求範圍內執行,這樣就把每個節點的物理資源控制在一個合理的範圍內。我想這應該是Laxcus至今沒有出現宕機現象的主要原因,感覺它比目前普遍用的負載均衡機制前進了一大步。
4. 規模大
按Laxcus產品說明書中的介紹,Laxcus的叢集規模可以達到百萬級物理節點和EB級的資料量(1000+PB)。我仔細看了這一段的技術文件,裡面提到是採用了一個叫做“多域並行”的技術來實現的。按它文件的說法,以現有硬體的處理效能,一個叢集的節點規模達到“千”級時,叢集的資源管理和資料承載能力就會接近物理極限,很難再通過增加機器的方式,做更大規模的資料處理,而使用者的資料處理需求總是在增長。
所以,為了解決這個矛盾,Laxcus採用這樣一個做法:在單個叢集之上,再建立一套管理模型,用一個並行的叢集資源管理池來管理多個叢集,然後讓這些叢集之間相互通訊,實現跨叢集跨節點的分散式儲存和計算。
當然,百萬級的計算機節點,EB級的資料,這種巨量的大資料叢集我也沒有試過。截止到這個月,我們部門的計算機還不到一百臺,廣告資料不過320TB,一個叢集處理起來已經綽綽有餘。TB距離EB,中間隔著PB,差了N個量級。但是給我的感覺,這套軟體挺牛的,雖然對我們公司沒什麼用處,但是對那些資料量會持續快速增長的公司,尤其是雲端計算服務商,應該會非常有用。這個功能給他們的業務擴張留出了充足的空間。
5. 第三方友好,遷移成本低
如果說上面這些特點還不足以讓我們放棄OpenStack/Hadoop這對組合,那麼最終讓我們下定決心遷移平臺的原因,是Laxcus的第三方友好特性。在此之前,我們為了支援自己的廣告大資料分析業務,已經開發了很多廣告業務工具包和分散式應用,並部署在Hadoop叢集裡執行。在做遷移決定前,我們最擔心的就是這些工具包和應用要推倒重寫。
如果真的需要這樣做,那就顯得得不償失了,況且我們也沒有足夠的人力,把幾年積累下的程式碼重新設計開發一遍。這個問題我們先是請教Laxcus的技術支援工程師,通過和他們的接觸討論,我們發現這個擔心是多餘的。
首先Laxcus和Hadoop都是基於Java開發出來的,語言層面可以相容。在系統架構、儲存、分佈計算這些底層核心要點上,它們都有可以對照類比的模組,整體設計思路也比較接近。區別是Hadoop譜系是多個團隊開發,做得比較分散;而Laxcus是一個團隊開發,軟體內部的整合度更高,結構更緊湊。
後來,經過我們和Laxcus技術服務工程師的協調,我們只做了少量的改動,主要是一些配置上的調整和匯入介面的修改,就把我們的應用轉移到Laxcus平臺,避免了我們重複開發的麻煩。這個擔心消除後,我們部門才決定把遷移平臺的決定提請給領導,並得到領導的同意。
6. 支援線上升級
Laxcus是能夠線上升級和更新的,這也是我上個月前才注意到的功能。我統計了一下,目前Laxcus能夠升級的部件包括:
1)使用者釋出到平臺和使用的分散式應用
2)管理員釋出和使用的分佈應用
3)各種驅動和動態連結庫
4)網路通訊配置和安全授權許可
5)系統的幾個核心包
這些部件除了使用者的分散式應用是自己控制和釋出外,其它都屬於管理員的權利。所以算下來,每個節點其實除了負責啟動的“殼程式”和通訊介面,其它部分都可以線上升級。
我不太肯定這算不算是重要的技術特點,但是我感覺很方便實用,它讓我實現了不停機狀態下的系統升級,避免了停機升級的業務停擺問題。這就象是一個太空裡的宇宙飛船,我一邊給它維修更換零件,一邊繼續駕駛它繞軌飛行,這感覺真的很酷!
7. 中文化做得很棒
在中文化支援方面,Laxcus做得確實沒話說,畢竟是國人團隊開發的產品,無論是字元控制檯還是圖形介面,都提供了很棒的中文化支援。對於我這樣長期在英語環境中浸泡著,飽受各種英文提示和故障錯誤的小碼農來說,看到自己熟悉的文字,有一種發自心底的親近感。
為了寫好這段文字,也出於好奇,我昨天打開了Laxcus原始碼,想了解一下Laxcus的中文化是怎麼做的,發現裡面一個小祕密。原來Laxcus把各種語言文字都做在配置檔案裡,軟體啟動的時候,會根據計算機作業系統的語言環境,自動適配對應的語言包,然後倒入執行環境,顯示在螢幕介面上。這個設計很有新意,按照這個思路,如果我想支援更多的語言,不用修改原始碼,只需要做些不同的語言包,就能實現我的目標。這是一個很有創意的妙招!

8. 配置極簡
目前Laxcus每個節點都有這樣三個配置檔案:
1)節點配置。只在啟動時載入,包括了日誌引數、資料存取引數、非同步處理引數,本地節點地址,上級伺服器節點地址。
2)網路安全通訊配置。在啟動時載入或者執行過程中過載。配置由多個地址段組成,每個地址段有一組可受理的IP地址和RSA金鑰。
3)沙箱配置。被容器使用,在啟動時載入或者執行過程中過載。包括允許使用者使用的物理裝置、能夠呼叫的API介面和動態連結庫,能夠讀寫的磁碟目錄和檔案 、是否可以儲存自己的工作日誌和何種型別的日誌。
三個配置檔案裡,除了節點配置裡的本地節點地址和伺服器節點地址需要管理員根據網路環境手工配置外,其它都可以使用系統的預設配置。
Laxcus配置是我做大資料以來,接觸的最簡單的配置,比Hadoop譜系的配置實在簡單太多!配置簡單的好處,做管理員的應該是最有體會了,除了省事,更主要是減少了我們工作中的誤操作,這是我又一個非常滿意Laxcus的地方。
能把配置做得如此簡單,又能保證系統足夠穩定,還不失靈活性,Laxcus大資料作業系統的設計師應該是花了不少心思,同步感謝一下為Laxcus辛苦碼字的碼農同行們!
9. 全域安全
由於廣告資料具有很強的私密性和敏感性,公司一直高度重視安全問題,所以Laxcus的安全管理方案,也是我最感興趣研究時間最久的一個部分。按照Laxcus官方的說法,Laxcus做的是“全域安全管理”。
如果這個詞不好理解,他們還有一個通俗的解釋:“從鍵盤到硬碟”的安全管理。這個方案的特點是,只要使用者登入大資料叢集那一刻起,就被置於安全監管裡。使用者發出的每一條命令,命令中的每一步驟,步驟中的每一項操作,其中涉及到API介面、動態連結庫、網路、記憶體、CPU、GPU、各種輸入輸出的時候,都在會在系統監管下執行,並且被記錄下來。
任何一項操作被限制拒絕,都會導致整個分佈處理的失敗。所以,Laxcus安全管理方案的安全度非常高,它全棧式的安全控制,覆蓋叢集所有分佈環節,把業務置於其中。
下面以我的經驗,試著說說Laxcus的安全管理方案。
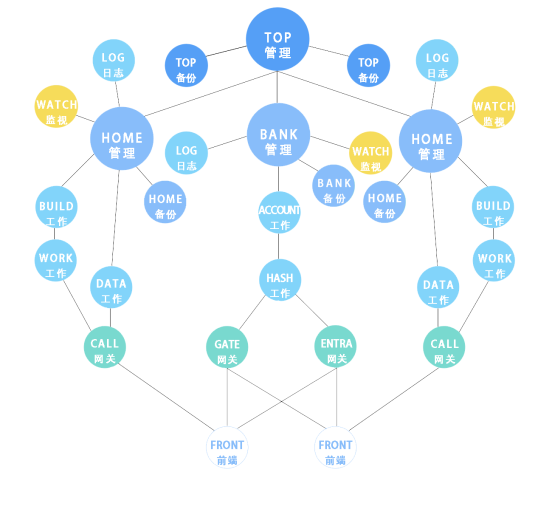
先說一下環境安全,這是Laxcus整個安全方案的基礎。請看上面的架構圖。雖然Laxcus以一個叢集的面貌出現,但是它實際上是分成了內外兩個網路。內部是管理員控制,叢集各種主要工作,包括大資料的儲存和計算,都位於內網。
外部給使用者使用,Front是外部網路的唯一節點,它的作用是發出大資料命令和接受大資料處理結果。連線它們的是閘道器,閘道器實質就是一個反向代理伺服器,在這裡它有兩個作用:識別使用者身份,轉發使用者命令,和遮蔽內部網路拓撲結構。
我個人覺得閘道器主要作用還是遮蔽內網,這樣即使發生DDOS這樣的攻擊行為,因為閘道器的中介位置和安全識別的原因,攻擊也只能到此為止,內部網路可以不受影響。從應用角度看,由於私有云本身就在內部網路裡,被攻擊的可能性很小,所以我覺得這項設計應該還是針對公有云做的。
下面就進入了實際的安全處理流程,請看下面這幅Laxcus產品說明書裡提供的安全流程圖。
Laxcus是一個叢集軟體,所有節點都需要通過網路連線才能工作,所以網路通訊的安全就成了安全方案的第一道關口。Laxcus在這裡用的是RSA+SHA的雙重安全驗證。這個驗證特點是,只要使用者與叢集發生網路通訊,都會面臨RSA+SHA的檢查。
咱們寫碼的都知道,RSA是非對稱加密,防止資料竊取,SHA是數字簽名,用來保證網路兩端的資料一致性,這兩個是目前業內安全度最高的加密演算法和簽名演算法。即使給RSA用上暴力破解,以現有技術條件,使用GPU/FPGA這些算力超強的晶片來做,加上Laxcus這種大規模分佈計算系統加持,破解時間也需要以“年”計。
就算到時破解成功,資料也因為時效性而失去意義。所以網路通訊這一層的安全還是很有保障的。另外這裡還有一個安全設計:Laxcus的RSA加密針對的是單個使用者,允許每個使用者有一個自己的金鑰,而不是所有使用者共用一個金鑰,這樣就算某個使用者的金鑰遺失或者被盜,也不影響其他使用者的通訊安全。
往下一層是“對稱加密”,這一層仍然和RSA有關。原因是RSA雖然提供了很強的安全保密手段,但是由於它的加密解密都非常消耗CPU算力,時間成本高,所以行業內的通行做法是資料加密解密由對稱金鑰來做,RSA給對稱金鑰提供外層保護,把對稱金鑰包含在RSA的資料域裡。Laxcus也是這個路數,目前它支援的對稱加密演算法有DES、DES3、AES五六種。
如果使用者希望用自己的對稱加密演算法,Laxcus也支援,只是過程有點麻煩,要按照它的規範實現加解密介面和寫配置檔案,然後匯入系統。這些對稱金鑰都是在通訊時由系統隨機生成,通訊完成後銷燬,所以只要RSA安全的,破解對稱金鑰的可能性基本是零。
再往下就進入了“資源安全策略”層。這一層主要檢查節點和接入操作的匹配關係,判斷節點能不能支援接入的操作,操作有沒有得到授權或者發生越權,如果存在問題,系統將直接拒絕這個操作。舉個栗子,Laxcus強制規定大資料儲存動作只能發生在Data節點上,其他任何節點出現這個操作,系統會不加思索地直接反饋錯誤。
接著就進入了“簽名管理”層,這一層是處理使用者虛擬化的工作。系統將根據使用者簽名,判斷使用者身份的合法性,和可以處理哪些具體的資料操作。另外,如果叢集做為雲服務使用時,系統還會檢查使用者的資源佔比。這些資源包括了網路頻寬、記憶體、硬碟、CPU/GPU。如果使用者資源充足時,系統會啟動使用者業務。可用資源不足時,系統會讓它轉入休眠狀態,直到前面的資料業務完成,使用者重新擁有足夠的資源時,系統才會重啟這個業務。
再往下就是“使用者安全策略”和“業務安全策略”。在我看來,它們是同一層,因為這兩層的編碼是混合在一起的,並沒有清楚的層次分別。到了這一層,使用者的資料處理工作將被放入沙箱,系統檢查也轉為監視使用者的資料處理行為。比如,使用者想把資料寫入記憶體或者硬碟,系統會判斷它的寫入許可權和可用空間。如果使用者想呼叫系統的API介面,系統將檢查他有沒有呼叫許可權。總之,系統會追蹤使用者在沙箱裡的每一個操作行為,確保資料處理在規定的範圍內執行。
Laxcus的安全設計大概就是這樣,我歸納一下它的特點:Laxcus先用一個內外網的設計,把不安全因素隔離在外網,再用分層策略,加上加密、相關性、身份驗證、虛擬化、行為監視手段,把使用者和資料處理行為限制在規定空間裡,通過這樣一層層的安全控制,實現它全方位的安全管理。
10. 分散式程式設計和人工智慧
現在我說一下Laxcus平臺上的大資料應用開發,我想這應該是程式設計師們最關心的部分了。正好我這幾個月一直做Laxcus大資料平臺上的開發,現在也算是小有經驗,所以可以和大家仔細說說這個事。
先說點理論的。按Laxcus產品說明書,Laxcus採用了一種叫做“模板化程式設計”的技術,而以我對Laxcus大資料平臺程式設計的理解,這是一個經過高度封裝的分佈程式設計框架,所有大資料應用都在這個框架下實現。在這個框架裡,它包含了兩種程式設計模型,一個是用於分散式計算,背後的支援演算法叫Diffuse/Converge,可以對標的是Hadoop的Map/Reduce演算法,同時它還融合了基於CNN演算法的人工智慧技術,現在我們部門的各種廣告大資料計算和分析業務,都是用它來實現,尤其是分支較多和散射型的分析業務,就大量使用了Diffuse/Converge裡提供的CNN演算法介面。
另一個是分佈資料構建,背後的支援演算法是Scan/Sift,這在Hadoop裡還沒有對標的演算法,它屬於ETL業務,工作重點是資料的重組、優化、清洗之類,資料倉庫上會用得比較多,我們部門現在還比較少用。
雖然兩個程式設計模型處理的業務不同,但是在分佈程式設計框架裡,它們遵循一樣的分佈處理規則。這個分佈處理規則,Laxcus有一個專業的描述:“階段(Phase)”。如果這個詞不好理解,或者你把它理解成與業務場景匹配的作業需求,一個業務在不同場景下有不同的作業需求。
階段根據應用場景,分為迭代和非迭代兩種,迭代就是能夠連續多次執行,非迭代只允許執行一次。一個階段是不是支援迭代,Laxcus有明確規定。為了在執行時識別各種階段,Laxcus還定義了各階段的名稱。大資料應用執行的時候,系統通過命名識別,將階段分發到關聯節點上,計算過程中,上個階段的資料輸出會成為下個階段的資料輸入,經過一系列節點上連續的分散和聚合,序列與並行的處理,最終輸出計算結果。
技術實現上,對應各種作業需求,Laxcus給每個階段設計了一個或者幾個抽象介面。程式設計師們要做的事,就是實現這些介面,將自己的大資料業務程式設計嵌入進去,然後編譯,打包成程式段,做成一個個即獨立又聯絡的模組,Laxcus稱這個為“分佈任務元件”,其實也可以理解為一種中介軟體。
最後,程式設計師把分佈任務元件組織到一起,起一個名字,包裝成大資料應用,釋出到叢集上。系統會全程維護管理大資料應用,不用使用者參與。另外大資料開發中的其他部分,比如網路通訊、分佈排程、資料IO、資源檢索和獲取這些功能,都在分佈程式設計框架裡封裝好了,程式設計師用API直接呼叫。
如果給Laxcus的分佈程式設計框架找個類比的物件,我覺得它很象安卓系統的MVP模型 。它們的共同特點是都把公共部分封裝起來,留給程式設計師開發的只是和業務有關的邏輯部分,不同之處是Laxcus做得更徹底些,它的分佈程式設計框架不光告訴我們怎麼走路,連要走的路徑都預設好了,讓大資料開發工作完全有章可循。
目前我已經在Laxcus大資料平臺上開發了許多應用,比如下面這個挖礦的程式,利用分佈程式設計框架,還有計算機叢集和GPU的支援,很快就能挖出我要的礦碼。

綜上所述,由於Laxcus分佈程式設計框架已經把大量功能做了封裝,規範了分佈處理流程,它的開發工作還是比較簡單的,工作量也不大。各位如果要做Laxcus的大資料應用開發,需要做好這三件事:1. 清楚你公司的業務;2. 熟悉Laxcus分佈程式設計框架、理解每個階段和相關介面的功能;3. 把它們結合起來,做成大資料應用。
缺點
任何產品都不是完美的,上面說了Laxcus那麼多好話,本著實事求是的原則,下面我該講講Laxcus的缺點了。這些問題雖然不太嚴重,但是也或多或少影響了我的大資料體驗,給我的使用產生了不小的困擾,使我感覺Laxcus也不是那麼完美。
1. 命令太多
據我不完全統計,Laxcus的命令,包括管理員的叢集管理命令和使用者的資料操縱命令,加起來大約有一百五十多個。如果再考慮到每個命令裡還有許多選項,選項之間隱含的各種組合、前後文關係,並且能在不同場景充分理解和熟練使用它們,真不是一件輕鬆的事。實際上,我為了學習這些命令,已經消耗了很多時間,而效果是到今天我也沒有完全掌握這些命令,很多時候還是藉助幫助文件熟悉後才能去操作。
另外,用敲擊鍵盤來輸入命令,已經是一種非常古老的操作方式了,重複費時費力且不說,效率也實在太低,很容易出錯,這是我不喜歡命令列操作的又一個原因。雖然命令確實簡化了人機互動,但是它更多是把工作壓力轉移到叢集管理員和使用者身上,所以我不認為這是一種好的互動方案。我的想法是,能不能提供一些便捷的互動方式,比如用選單和按紐,勾選各種選項來代替字串輸入,或者更進一步,藉助人工智慧和語音技術,來實現人機互動。希望Laxcus設計師能看到我的這個建議,未來能有更優秀的人機互動模式。
2. 缺少視覺化製作工具
視覺化號稱大資料的最後一公里,Laxcus卻沒有提供一個視覺化工具,不能不說是一個遺憾。這和Laxcus標榜的“一站式大資料解決方案”多少有些不相符。因為Laxcus這個缺失,我們部門製作大資料視覺化的工作量,一點也沒少,仍然要依賴Tableau來完成大資料分析的後期資料視覺化工作。而用過Tableau的人應該都知道,這個圖表軟體是靈活性足夠但是也足夠複雜,而公司的廣告分析主要需求是快速靈活的顯示,所以Tableau對我們的業務來說,並不是最佳的視覺化工具。
其實在我心裡,一直有另外一個大資料視覺化設計方案的構想。它將完全是動態產生,可以解決現在大資料視覺化機械、呆板、耗時耗力問題。今天我藉著Laxcus視覺化這個話題,和各位說說,讓大家幫我參考參考,給個意見,也許是一個創業機會呢。^_^
我的這個大資料視覺化方案的核心是:視覺化圖表將不再由使用者畫出來,而是從資料裡“長出來”。實現的過程是這樣:使用者首先定義一個視覺化模板,模板裡規定好圖表佈局,設定好各種圖表元素的“種子”。圖表種子可以生長,能根據不同的資料長出不同的樣式。當大資料計算結果出來後,把它和視覺化模板一起輸入視覺化生成引擎。引擎根據資料內容,驅動“圖表種子”生長,最後生成我們希望的樣子。
我的這個大資料視覺化的優點是:即有靈活性,也避免了重複工作,還保證了絕對的實時效果,一舉多得,對時效性強的場景特別有用。當然缺點也是有的,就是為了讓視覺化引擎理解資料,驅動圖表生長,還需要在樣板裡配置一個圖表直譯器,由它負責把大資料計算結果轉成引擎理解的格式。這要求使用者能夠理解資料內容,有一定程式設計功底,對初學者有一定的難度。
我的大資料視覺化想法就是這樣。有興趣的網友可以聯絡我,一起嘗試下,現在我已經有了一個初步計劃,很可能這個小小的idea就能成就咱們一番事業!
3. 圖形介面表現不佳
與Laxcus大資料叢集進行直接互動的介面,有字元控制檯和圖形兩種模式。其中字元控制檯的使用感覺還好,但是圖形介面,根據我之前使用NetBeans的經驗,Laxcus的圖形介面是用Swing做的,所以我曾經在NetBeans上遇到的所有與圖形有關的問題,在Laxcus圖形介面上也一個不漏地出現了。
比如,有時候某個控制元件會莫名其妙地失去焦點,或者文字框不能輸出文字了。如果重啟一下,這些故障就會消失。還有,我平時除了使用Windows,有時候也會使用Linux來管理維護Laxcus大資料叢集,而Swing在Linux平臺上的表現更糟,除了上面的諸多問題,還有亂碼現象。我知道如果追蹤下去,這些問題都會匯聚到Swing身上。
如果說上面的問題我還能夠忍受,那麼更嚴重的是Swing執行緩慢和互動遲滯的問題,特別是Swing經過長時間執行,或者與其他節點頻繁互動顯示大量影象時,這種情況尤其明顯,已經幾乎無法忍受。
所以,我非常希望Laxcus的研發團隊用其它圖形介面來取代糟糕的Swing,比如Eclipse平臺的SWT,以我使用Eclipse的經歷,SWT這個圖形介面,無論是介面的美觀度、與本地平臺的契合、對記憶體的佔用、還有互動反應能力上,都比Swing好太多!Swing介面糟糕的表現,我很早就反饋給Laxcus服務支援團隊了,不知道他們什麼時候能解決這個問題。
4. 服務不到位
最後,我不得不吐槽一下Laxcus的技術服務。我不知道我們公司是不是第一個吃Laxcus這隻螃蟹的,但是應該肯定不是最後一個。由於網上Laxcus的技術資料實在太少,很多時候,我們遇到問題的時候,不得不去請教Laxcus的售後服務,而負責解答的兩位售後小哥,顯然也不是專業人士,很多問題,他們都要再去請教他們的技術專家才能回答我們,一來二去,耽誤了我們不少時間。有好幾次,我們已經通過查閱原始碼找到解決問題的方案了,對方的反饋還沒有回覆。到後來,我們乾脆死了這份心,遇到問題都直接看幫助文件和原始碼。雖然這樣做強迫我們提高了自學能力,但是我也不得不說,Laxcus的技術售後服務實在太差了!
結束語
寫到這裡,我的評論準備結束了。因為使用時間和經驗的原因,我的表述可能有不準確的地方,希望有經驗的網友提出批評指證,與我交流切磋。
最後,我再說一點我個人的看法。憑心而論,Laxcus帶給我的驚豔很多,但是缺憾也不少。Laxcus研發團隊能深入理解使用者需求,把那麼多大資料和雲端計算的技術融匯貫通,聚合到一個產品裡,簡化了大資料雲端計算的開發維護管理工作,並且在Hadoop之外,建立了一套全新的大資料技術體系,用一個產品一套介面,完成Hadoop譜系多模組多接口才能實現的事,確實給我很大震撼。
相當程度上,改變了我對大資料的技術認知,顛覆了我原來的大資料使用體驗,這是一件非常了不起的事,非常不容易。我們現在正在從IT時代向DT時代進步,大資料肯定是未來各個行業的基礎,基於大資料的應用和服務會越來越多,簡單、好用、省約成本將是大資料應用開發和維護管理的核心,Laxcus顯然是抓住了這一點,把各方面工作難度降到一個很低的水平。
據我有限的瞭解,目前國內,能開發出Laxcus這種級別軟體的研發團隊屈指可數,我們應該多支援這樣的團隊,希望Laxcus能補齊短板,未來有更多像Laxcus的產品來簡化我們的工作生活,祝Laxcus越做越好!