CS224n學習筆記1
CS224n學習筆記 Lecture 2: Word Vector
參考連結:Word2Vec Tutorial - The Skip-Gram Model
[NLP] 秒懂詞向量Word2vec的本質
CS224n筆記2 詞的向量表示:word2vec
word2vec是如何得到詞向量的(crystalajj的回答)
前言:
本人還是小白,開通此部落格是作為筆記使用,記錄平時的學習心得。數學公式雖有涉及,但暫且不會放在部落格上,著重記錄演算法思想。如有錯誤,歡迎交流指正,不勝感激!
skpi-gram模型訓練
在skpi-gram模型中,我們最終目的是獲得模型基於訓練資料學得的隱層權重。
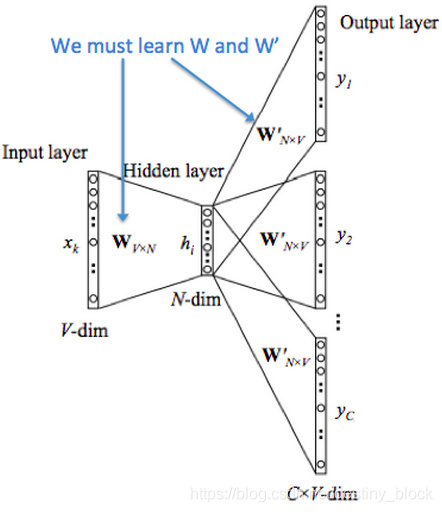
訓練資料:詞對(input word,output word)。輸入層輸入的是input word 的one-hot vector(但在實際程式碼中, 輸入的並不是one-hot vector,因為獨熱向量編碼有很多都是0,所以也會轉成雜湊特徵,加快效率),輸出層輸出的是output word 的one-hot編碼。
開始訓練:初始化權重W、W`為隨機值,前向傳播,得到輸出層的概率分佈,使用交叉熵作為代價函式,反向傳播,採用梯度下降演算法更新權重。
完成訓練:權重W就是我們要的詞向量矩陣。輸入層的每個單詞(one-hot vector)與矩陣W相乘得到的向量的就是我們想要的詞向量(word embedding)。輸出層得到的是概率分佈,意思是當前位置代表的詞與input word 共現的概率。 eg:假設字典是【我,你,好,是】,在訓練完模型後,輸入“是”,one-hot編碼為[0,0,0,1],如果輸出層輸出的概率是[0.4,0.4,0.1,0.1],第一個0.4就代表“我”與“是”共現的概率。
NB:W中的向量叫input vector,W’中的向量叫output vector。所以每個詞都有兩個向量表示。把所有引數寫進向量θ,CS224n assignment1 q2_neural.py 中是將兩個權重矩陣拼接起來的。