
Flink SQL 核心解密 —— 提升吞吐的利器 MicroBatch
之前我們在 Flink SQL 中支援了 MiniBatch, 在支援高吞吐場景發揮了重要作用。今年我們在 Flink SQL 效能優化中一項重要的改進就是升級了微批模型,我們稱之為 MicroBatch,也叫 MiniBatch2.0。
在設計和實現 Flink 的流計算運算元時,我們一般會把“面向狀態程式設計”作為第一準則。因為在流計算中,為了保證狀態(State)的一致性,需要將狀態資料儲存在狀態後端(StateBackend),由框架來做分散式快照。而目前主要使用的RocksDB,Niagara狀態後端都會在每次read和write操作時發生序列化和反序列化操作,甚至是磁碟的 I/O 操作。因此狀態的相關操作通常都會成為整個任務的效能瓶頸,狀態的資料結構設計以及對狀態的每一次訪問都需要特別注意。
微批的核心思想就是快取一小批資料,在訪問狀態狀態時,多個同 key 的資料就只需要發生一次狀態的操作。當批次內資料的 key 重複率較大時,能顯著降低對狀態的訪問頻次,從而大幅提高吞吐。MicroBatch 和 MiniBatch 的核心機制是一樣的,就是攢批,然後觸發計算。只是攢批策略不太一樣。我們先講解觸發計算時是如何節省狀態訪問頻次的。
微批計算
MicroBatch 的一個典型應用場景就是 Group Aggregate。例如簡單的求和例子:
SELECT key, SUM(value) FROM T GROUP BY key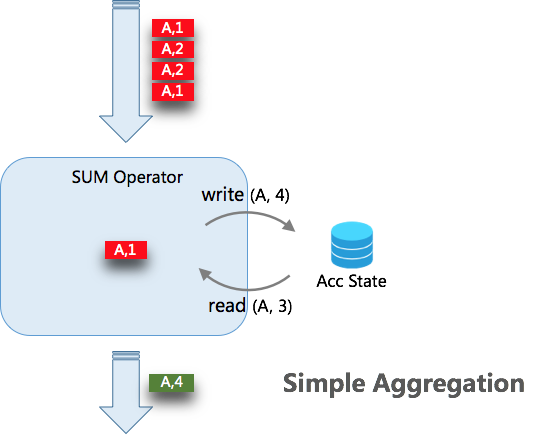
如上圖所示,當未開啟 MicroBatch 時,Aggregate 的處理模式是每來一條資料,查詢一次狀態,進行聚合計算,然後寫入一次狀態。當有 N 條資料時,需要操作 2*N 次狀態。
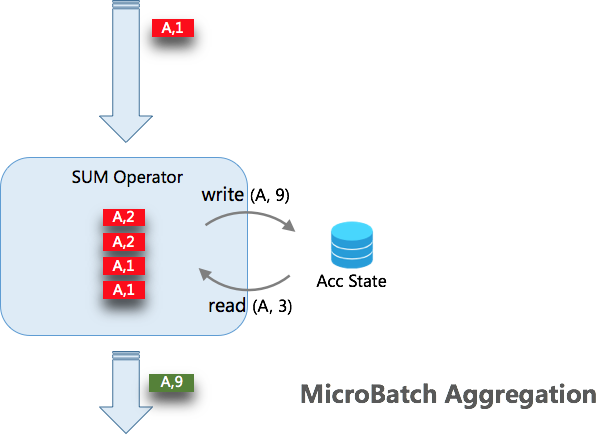
當開啟 MicroBatch 時,對於快取下來的 N 條資料一起觸發,同 key 的資料只會讀寫狀態一次。例如上圖快取的 4 條 A 的記錄,只會對狀態讀寫各一次。所以當資料的 key 的重複率越大,攢批的大小越大,那麼對狀態的訪問會越少,得到的吞吐量越高。
攢批策略
攢批策略一般分成兩個維度,一個是延時,一個是記憶體。延時即控制多久攢一次批,這也是用來權衡吞吐和延遲的重要引數。記憶體即為了避免瞬間 TPS 太大導致記憶體無法存下快取的資料,避免造成 Full GC 和 OOM。下面會分別介紹舊版 MiniBatch 和 新版 MicroBatch 在這兩個維度上的區別。
MiniBatch 攢批策略
MiniBatch 攢批策略的延時維度是通過在每個聚合節點註冊單獨的定時器來實現,時間分配策略採用簡單的均分。比如有4個 aggregate 節點,使用者配置 10s 的 MiniBatch,那麼每個節點會分配2.5s,例如下圖所示:

但是這種策略有以下幾個問題:
- 使用者能容忍 10s 的延時,但是真正用來攢批的只有2.5秒,攢批效率低。拓撲越複雜,差異越明顯。
- 由於上下游的定時器的觸發是純非同步的,可能導致上游觸發微批的時候,下游也正好觸發微批,而處理微批時會一段時間不消費網路資料,導致上游很容易被反壓。
- 計時器會引入額外的執行緒,增加了執行緒排程和搶鎖上的開銷。
MiniBatch 攢批策略在記憶體維度是通過統計輸入條數,當輸入的條數超過使用者配置的 blink.miniBatch.size 時,就會觸發批次以防止 OOM。但是 size 引數並不是很好評估,一方面當 size 配的過大,可能會失去保護記憶體的作用;而當 size 配的太小,又會導致攢批效率降低。
MicroBatch 攢批策略
MicroBatch 的提出就是為了解決 MiniBatch 遇到的上述問題。MicroBatch 引入了 watermark 來控制聚合節點的定時觸發功能,用 watermark 作為特殊事件插入資料流中將資料流切分成相等時間間隔的一個個批次。實現原理如下所示:
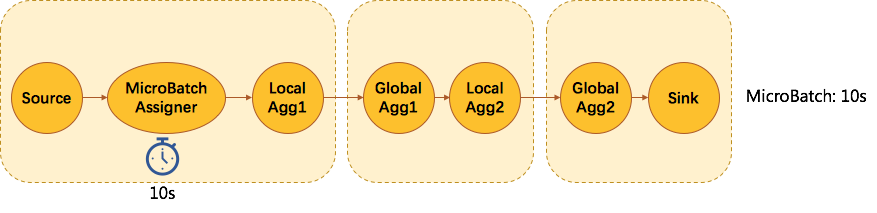
MicroBatch 會在資料來源之後插入一個 MicroBatchAssigner 的節點,用來定時傳送 watermark,其間隔是使用者配置的延時引數,如10s。那麼每隔10s,不管資料來源有沒有資料,都會發一個當前系統時間戳的 watermark 下去。一個節點的當前 watermark 取自所有 channel 的最小 watermark 值,所以當聚合節點的 watermark 值前進時,也就意味著攢齊了上游的一個批次,我們就可以觸發這個批次了。處理完這個批次後,需要將當前 watermark 廣播給下游所有 task。當下遊 task 收齊上游 watermark 時,也會觸發批次。這樣批次的觸發會從上游到下游逐級觸發。
這裡將 watermark 作為劃分批次的特殊事件是很有意思的一點。Watermark 是一個非常強大的工具,一般我們用來衡量業務時間的進度,解決業務時間亂序的問題。但其實換一個維度,它也可以用來衡量全域性系統時間的進度,從而非常巧妙地解決資料劃批的問題。
因此與 MiniBatch 策略相比,MicroBatch 具有以下優點:
- 相同延時下,MicroBatch 的攢批效率更高,能攢更多的資料。
- 由於 MicroBatch 的批次觸發是靠事件的,當上遊觸發時,下游不會同時觸發,所以不像 MiniBatch 那麼容易引起反壓。
- 解決資料抖動問題(下一小節分析)
我們利用一個 DAU 作業進行了效能測試對比,在相同的 allowLatency(6秒)配置的情況下,MicroBatch 能得到更高的吞吐,而且還能得到與 MiniBatch 相同的端到端延遲!

另外,仍然是上述的效能測試對比,可以發現執行穩定後 MicroBatch 的佇列使用率平均值在 50% 以下,而 MiniBatch 基本是一直處於佇列滿載下。說明 MicroBatch 比 MiniBatch 更加穩定,更不容易引起反壓。

MicroBatch 在記憶體維度目前仍然與 MiniBatch 一樣,使用 size 引數來控制條數。但是將來會基於記憶體管理,將快取的資料存於管理好的記憶體塊中(BytesHashMap),從而減少 Java 物件的空間成本,減少 GC 的壓力和防止 OOM。
防止資料抖動
所謂資料抖動問題是指,兩層 AGG 時,第一層 AGG 發出的更新訊息會拆成兩條獨立的訊息被下游消費,分別是retract 訊息和 accumulate 訊息。而當第二層 AGG 消費這兩條訊息時也會發出兩條訊息。從前端看到就是資料會有抖動的現象。例如下面的例子,統計買家數,這裡做了兩層打散,第一層先做 UV 統計,第二級做SUM。
SELECT day, SUM(cnt) total
FROM (
SELECT day, MOD(buy_id, 1024), COUNT(DISTINCT buy_id) as cnt
FROM T GROUP BY day, MOD(buy_id, 1024))
GROUP BY day當第一層count distinct的結果從100上升到101時,它會發出 -100, +101 的兩條訊息。當第二層的 SUM 會依次收到這兩條訊息並處理,假設此時 SUM 值是 900,那麼在處理 -100 時,會先發出 800 的結果值,然後處理 +101 時,再發出 901 的結果值。從使用者端的感受就是買家數從 900 降到了 800 又上升到了 901,我們稱之為資料抖動。而理論上買家數只應該只增不減的,所以我們也一直在思考如何解決這個問題。
資料抖動的本質原因是 retract 和 accumulate 訊息是一個事務中的兩個操作,但是這兩個操作的中間結果被使用者看到了,也就是傳統資料庫 ACID 中的隔離性(I) 中最弱的 READ UNCOMMITTED 的事務保障。要從根本上解決這個問題的思路是,如何原子地處理 retract & accumulate 的訊息。如上文所述的 MicroBatch 策略,藉助 watermark 劃批,watermark 不會插在 retract & accumulate 中間,那麼 watermark 就是事務的天然分界。按照 watermark 來處理批次可以達到原子處理 retract & accumulate 的目的。從而解決抖動問題。
適用場景與使用方式
MicroBatch 是使用一定的延遲來換取大量吞吐的策略,如果使用者有超低延遲的要求的話,不建議開啟微批處理。MicroBatch 目前對於無限流的聚合、Join 都有顯著的效能提升,所以建議開啟。如果遇到了上述的資料抖動問題,也建議開啟。
MicroBatch預設關閉,開啟方式:
# 攢批的間隔時間,使用 microbatch 策略時需要加上該配置,且建議和 blink.miniBatch.allowLatencyMs 保持一致
blink.microBatch.allowLatencyMs=5000
# 使用 microbatch 時需要保留以下兩個 minibatch 配置
blink.miniBatch.allowLatencyMs=5000
# 防止OOM,每個批次最多快取多少條資料
blink.miniBatch.size=20000後續優化
MicroBatch 目前只支援無限流的聚合和 Join,暫不支援 Window Aggregate。所以後續 Window Aggregate 會重點支援 MicroBatch 策略,以提升吞吐效能。另一方面,MicroBatch 的記憶體會考慮使用二進位制的資料結構管理起來,提升記憶體的利用率和減輕 GC 的影響。