
實時資料分頁去重問題
1. 問題描述
將分頁、降序資料用瀑布流展示的時候,因為資料總量是不斷變化的,導致之前第一頁的資料可能變成第二頁,第三頁,這樣客戶檢視的時候可能出現重複資料展示。(最新的資料會插到列表的最前端)。 典型的是活動參與人列表頁,因為這部分資料對於業務方來說可能非常重要,不能出現任何的重複或者順序顯示的不對。
2. 實際場景
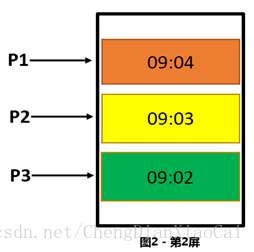
使用者按照分頁降序請求瀑布流資料的時候,請求完第一頁,在該頁停留了 5 分鐘,這段時間內資料庫中可能已經插入了多條新資料,再次請求第二頁的時候就有可能出現一些重複資料,對於客戶體驗很不好,而且很可能引發客戶的投訴。
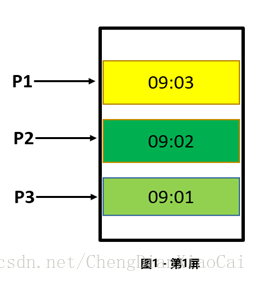
效果圖:
P1 在第一屏的時候在第一頁,如果客戶在一分鐘內沒有做任何操作,下一分鐘下滑頁面的時候去DB中獲取第二頁的時候會拿到重複的資料。
3. 解決方案
(1)新增快取
讓動態資料變成靜態資料,但不能從根本上解決資料重複問題,只能在一個時間段內保證不出現重複資料,快取失效後仍然可能出現重複資料。
(2)增加序列號(唯一有序),
記錄上一頁請求結果的最後一條記錄,請求下一頁的時候加上這條記錄用於後端判斷,後端只取該記錄之後的資料,強行將動態數看做靜態資料處理。
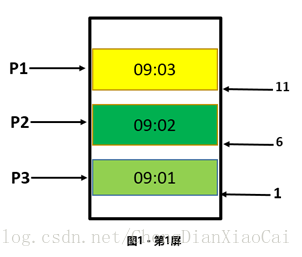
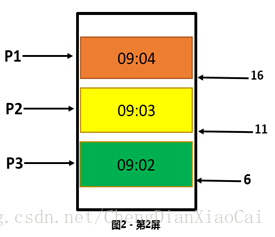
/** * P1 的最後一條記錄序列號是 11, 查詢第二頁的時候加上這個條件,只取 id 小於 11 的資料,可* 以取到正確資料 */ List<User> getUsers(size, serialNo){ List<User> users = selectFromESOrDBWhereIdIsLower(size, serialNo); return users }
這種方案的關鍵在於一個唯一且有序的序列號,根據這個序列號可以進行條件查詢,可以鎖定一個固定的範圍。
目前這種方案也是今日頭條採用的方案:
簡化版頭條分頁資料出參 JSON:

{ "return_count":15, "data":[ { "behot_time":1494381138 }, { "behot_time":1494380958 }, { "behot_time":1494380778 }, { "behot_time":1494380598 }, { "behot_time":1494380238 }, { "behot_time":1494380058 }, { "behot_time":1494379878 }, { "behot_time":1494379698 }, { "behot_time":1494379518 }, { "behot_time":1494379338 }, { "behot_time":1494378978 }, { "behot_time":1494378798 }, { "behot_time":1494378798 } ] }
從這個出參 JSON 我們可以看到每條記錄都有一個唯一有序的序列號。
方案實踐:
參與人列表顯示的是當前期的所有參與人訂單記錄(按支付時間降序顯示),思考過程中我們想過使用 payTime、orderId 作為序列號,但是最後方案都行不通,原因如下:
orderId: 訂單編號:訂單編號對於資料庫來說一定是唯一的,用它可以唯一的定位一條記錄,但是因為 orderId 的生成(下單)與使用者支付之間有一個時差,導致 orderid 小的訂單可能支付時間很晚,也就是 orderId 唯一但是沒有順序。
通過以上的分析:payTime 因為不符合唯一性不能作為序列號,orderId 因為不符合有序性也不能作為序列號。所以第二種方案對於我們的專案來說也不適用,沒有辦法保證資料不重複顯示。
(3)前端維護資料池
如果資料的相對順序不發生變化的話,比如參與人列表資料,按照參與時間降序排列,這種情況可以用增加唯一標識的方式解決,因為資料的相對順序沒有變化,所以之後請求到的資料都是之前沒有請求過的,所以可以很好的保證資料不重複,但是無法保證資料的即時性。
如果資料的相對順序不斷變化,並且這樣的資料還要求絕對不重複的話,比如按銷售進度排序首頁商品資訊,可能一次大的營銷活動會導致之前銷量不高的資料排序迅速躥高,進度快速提升,導致排序發生改變,那麼增加記錄唯一標識的方法也不能保證資料的不重複性,這個時候只能通過前端維護一個數據池,將之前已經請求到的資料存放進去,從後臺請求到新的資料後檢視資料池中是否已經存在,只顯示不存在的部分,新請求到的資料也都不斷的維護到資料池中。
(4)順序分頁,逆序顯示
前端維護資料池的方式雖然可以保證不出現重複資料,但是如果資料量很大的時候可能會導致資料池很大,而且前端做去重操作可能會導致資料量少於請求數量,而且順序無法保證,影響客戶體驗,這樣我們就必須思考新的方案,最後的方案是之前方案的一個逆向思維,不再做逆序分頁,因為逆序分頁總有最新的資料加進來影響資料總量和分頁的頁數,如果轉換思維做順序分頁,那麼可以保證之前的頁數不會變,只需要記錄第一次請求的時候資料庫資料總量,從而可以算出逆序分頁的頁數,然後去 ES 或者 DB 中取出資料,使用程式給資料做逆序顯示,從而可以保證資料的絕對不重複,並且資料的順序不會發生變化,而且每頁請求到的資料量與請求資料量一致(最後一頁可能會少一些)。
/*
* 虛擬碼
*/
getUsers(page, size, count){
//獲取第一次請求資料總量:動態資料 ==> 靜態資料
if(count == 0)
count = getCountFromDB()
//分頁入參重新計算,ES,DB 都變成順序查詢:降序頁數轉換成正向頁數
endIndex = count – (page - 1) * size;
startIndex = endIndex – size;
if(startIndex < 0)
startIndex = 0;
realSize = endIndex – startIndex;
//獲取順序分頁資料
pageList = getPageListFromESOrDB(startIndex, realSize);
//獲取反轉顯示資料
Collections.reverse(pageList);
//封裝出參:帶上 count
return (isLastPage, count, pageList)
}
最終上述程式碼成為我們最終的方案,並且在實踐中取得不錯的效果,保證了資料的絕對不重複,避免了因為資料重複或者順序不對引來的客戶投訴。
4. 總結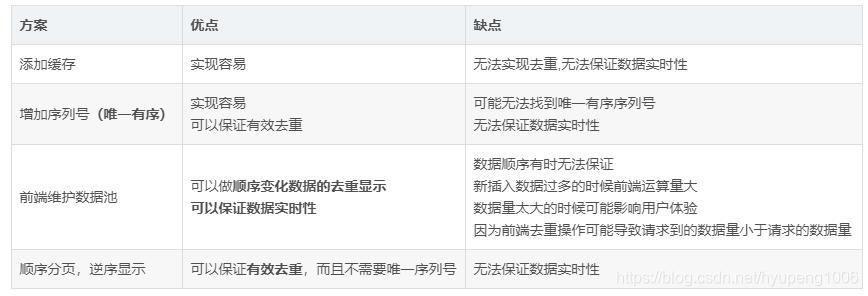
5. 思考
資料的實時性和重複性平衡點:
對於瀑布流分頁資料降序顯示問題,通過思考實踐我們總結出了上述四種方案,加快取、加序列號、順序分頁,逆序顯示方案的目的都是為了將動態資料轉換成靜態資料,保證了資料的不重複性,但是不能保證資料的實時性,最新的資料可能沒有辦法立即顯示出來,客戶端去重方案可以保證資料的實時性,但是卻不能絕對的保證資料的順序和不重複性,而且大量的去重運算放到前端也不是我們所推崇的。
所以無論是選擇哪種方案目前來看都沒有辦法同時保證資料的實時性和不重複性,那麼在方案的選擇時我們可以選擇多種方案的一個組合、或者通過增加新的功能。
比如今日頭條新聞客戶端,新聞資料量很大,需要分頁展示,但是新聞的資料跟作者名氣、點選人數等一系列引數有關,順序根本無法判斷,而且新聞還絕對不能重複顯示,那這種情況下需要將上述幾種方法進行一個結合。
我們可以使用順序分頁查詢、逆序顯示的方式處理瀑布流分頁,並且增加頂端下拉重新整理功能、或者客戶端去重功能,這樣可以保證下拉的過程中不會出現重複資料,頂端上拉重新整理可以顯示最新的資料,從而在資料的實時性和重複性之間找到一個平衡。