
Python 爬蟲基礎學習--網路爬蟲與資訊提取
阿新 • • 發佈:2018-12-05
Python 爬蟲基礎學習
Requests庫的安裝
Win平臺: “以管理員身份執行”cmd,執行 pip install requests
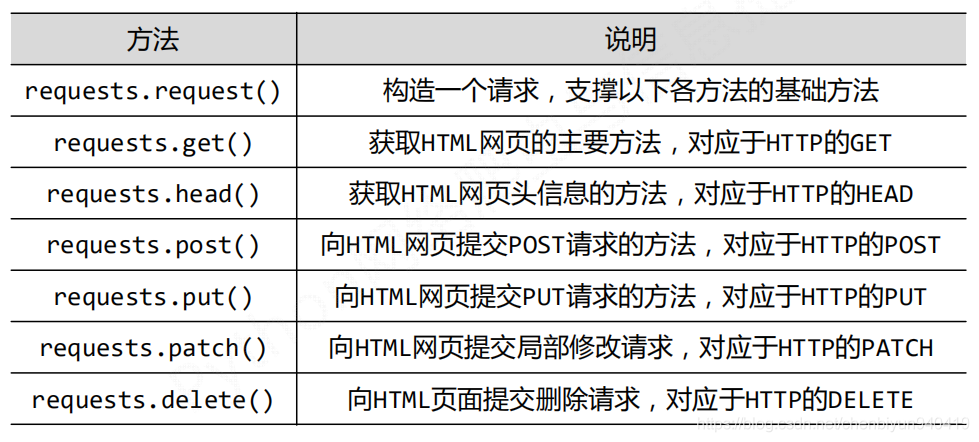
Requests庫的7個主要的方法


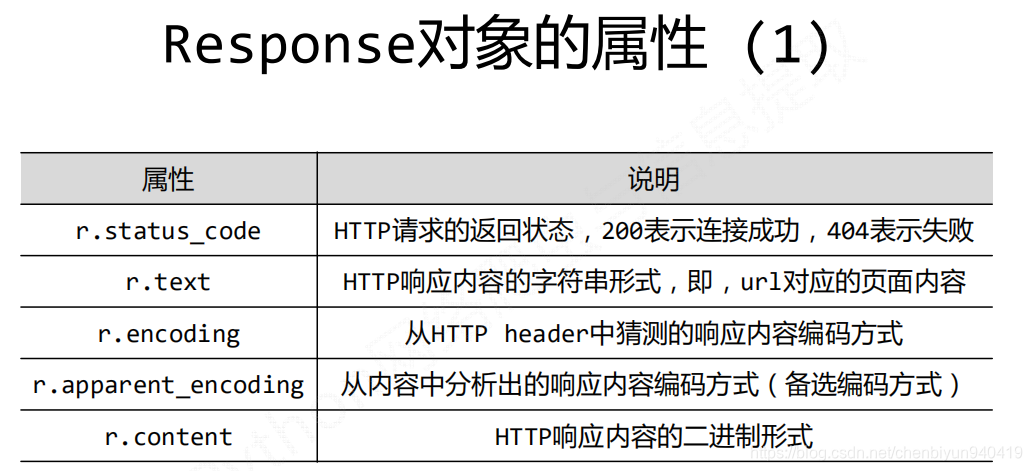
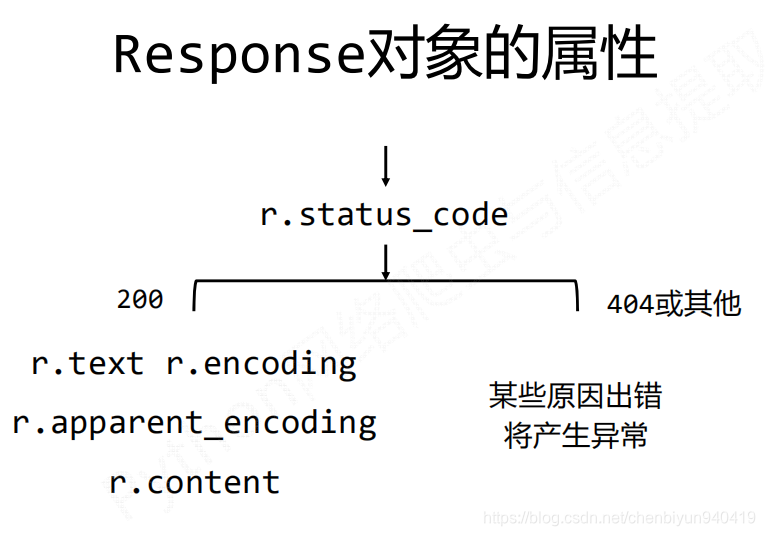
Requests庫中2個重要的物件:Request和Response
Response物件包含爬蟲返回的內容,也包含請求的Request資訊。

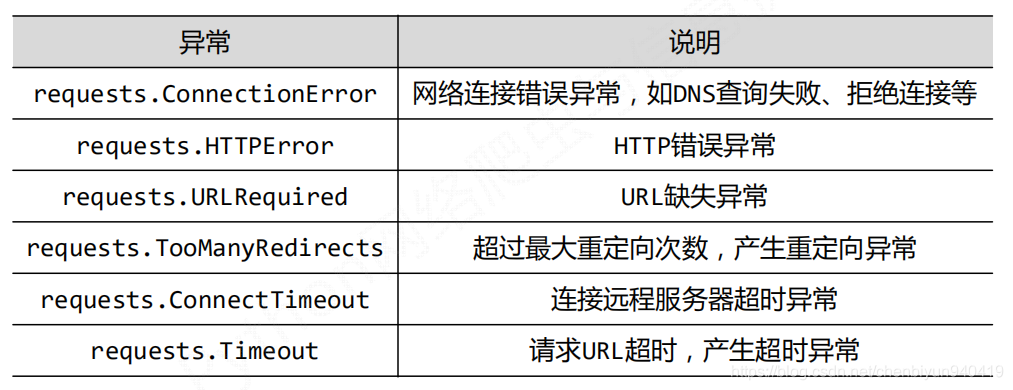
Requests庫的異常
Requests對網頁進行訪問時時時刻刻都會出現一些問題,那麼出現問題就需要相關的異常處理來解決。
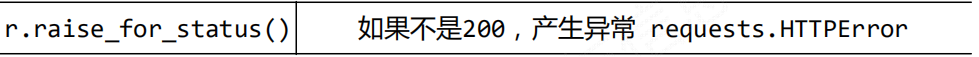
爬取網頁的通用框架為:

下面介紹一下HTTP協議,以此來了解url:
HTTP協議是超文字傳輸協議,基於“請求與響應”模式的,無狀態的應用層協議,採用URL作為定位網路資源的標識,URL的格式如下:
![**http://host[:port][path]**](https://img-blog.csdnimg.cn/20181205114603866.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2NoZW5iaXl1bjk0MDQxOQ==,size_16,color_FFFFFF,t_70)
對於URL的理解:
URL是通過HTTP協議存取資源的Internet路徑,一個URL對應一個數據資源


Request請求
requests.request(method, url, **kwargs)
method : 請求方式,對應get/put/post等7種
url : 擬獲取頁面的url連結
**kwargs: 控制訪問的引數,共13個
**kwargs:控制訪問的引數,均為可選項
params:字典或位元組序列,作為引數增加到URL中
data:字典、位元組序列或檔案物件,作為Request的內容
json:JSON格式的資料,作為Requet的內容
headers:字典,HTTP定製頭
cookies:字典或CookieJar,Request中的cookie
auth:元組,支援HTTP認證功能
files:字典型別,傳輸檔案
timeout:設定超時時間,秒為單位。
proxies:字典型別,設定訪問代理伺服器,可以增加登入認證。
allow_redirects :True或False,預設為True,重定向開關。
stream:True或False,預設為True,認證SSL證書開關
cert:本地SSL證書路徑