
Python網路爬蟲與資訊提取(五)資訊標記與資訊提取的一般方法
目前國際公認的資訊標記種類共有如下三種:
| 名稱 | 方式 | 例項 |
| XML(eXtensible Markup Language) | 基於HTML的用有名稱與屬性的標籤進行標記的方式 | <name>...</name> <name /> <!-- --> |
| JSON(JavaScript Object Notation) | 可直接作為JS程式的一部分的用有型別的鍵值對進行標記的方式 | "key" : "value" "key" : ["value1", "value2"] "key" : {"subkey" : "subvalue"} |
| YAML(YAML Ain't Markup Language) | 用無型別鍵值對進行標記的方法 | key : value key : #Comment -value1 -value2 key : subkey : subvalue |
對於想要提取的資訊,我們既可以通過完整解析資訊的標記形式,再提取關鍵資訊;又可以無視標記形式,直接搜尋關鍵資訊。
第一種方法對於資訊的解析較為準確並可以對整個資訊的結構有較為清楚的認識,但隨之而來的是提取過程繁瑣、對於大量資訊的提取效率較低的問題;第二種方法較為快速,但其提取結果的準確性與資訊內容相關,對於過於複雜的資訊則可能提取錯誤。所以通常情況下我們是將這兩種方法結合起來使用,即先通過解析標記形式確定要提取的資訊的大致範圍再在這範圍中直接搜尋與提取相關資訊。
下面我們用例項來講解一下
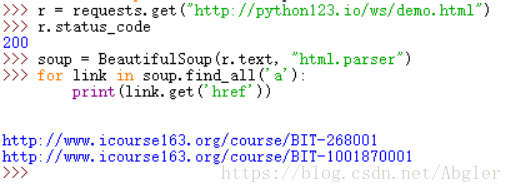
find_all()方法,故名思意即是對整個文件中的資訊進行解析與查詢,而第二個get方法則是直接在我們規定的<a>標籤範圍內對href進行搜尋。
find_all方法的完整形式為:
| name | 對標籤名稱的檢索字串 |
| attrs | 對標籤屬性值的檢索字串,可標註屬性檢索 |
| recursive | 是否對子孫全部檢索,預設為True |
| string | <>...</>中字串區域的檢索字串 |
若其中某個引數需輸入多個值時可用列表來實現,如:
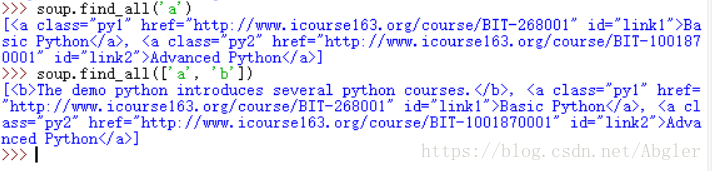
若name的值為True,則會現實當前文件的所有標籤資訊。
我們不僅可直接查詢文字中具有相應屬性的標籤,也可以對屬性進行規定再進行查詢:

需要注意的是,find_all方法的所有引數必須為HTML文件中已含有的欄位的全稱,如上圖中若將"link1"改為"link"則find_all將無法找到對應的標籤,若想在不知道欄位全稱的情況下進行查詢則需要用到正則表示式庫(import re),這個庫的相應用法我們將在以後具體例項中進行講解。
因為find_all是bs4庫中最常用的方法,所以可以直接使用<tag>(...)來代替<tag>.find_all(...),此外find_all()方法還有七個擴充套件方法:
| 方法 | 說明 |
| <>.find() | 搜尋且只返回一個結果,字串型別,同.find_all()引數 |
| <>.find_parents() | 在先輩節點中搜索,返回列表型別,同.find_all()參數 |
| <>.find_parent() | 在先輩節點中返回一個結果,字串型別,同.find_all()引數 |
| <>.find_next_siblings() | 在後續平行節點中搜索,返回列表型別,同.find_all()引數 |
| <>.find_next_sibling() | 在後續平行節點中返回一個結果,字串型別,同.find_all()引數 |
| <>.find_previous_siblings() | 在前序平行節點中搜索,返回列表型別,同.find_all()引數 |
| <>.find_previous_sibling() | 在前序平行節點中返回一個結果,字串型別,同.find_all()引數 |