
初窺Scrapy
初窺Scrapy
Scrapy是一個為了爬取網站資料,提取結構性資料而編寫的應用框架。 可以應用在包括資料探勘,資訊處理或儲存歷史資料等一系列的程式中。
其最初是為了 網路抓取 所設計的, 也可以應用在獲取API所返回的資料(例如 Amazon Associates Web Services 或者通用的網路爬蟲。
Scrapy 使用了 Twisted非同步網路庫來處理網路通訊。整體架構大致如下
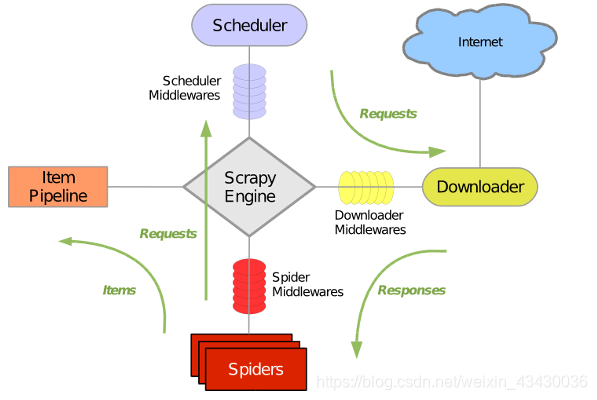
Scrapy主要包括了以下元件:
- 引擎(Scrapy) :用來處理整個系統的資料流, 觸發事務(框架核心)
- 排程器(Scheduler):用來接受引擎發過來的請求, 壓入佇列中, 並在引擎再次請求的時候返回. 可以想像成一個URL(抓取網頁的網址或者說是連結)的優先佇列, 由它來決定下一個要抓取的網址是什麼, 同時去除重複的網址
- 下載器(Downloader) :用於下載網頁內容, 並將網頁內容返回給蜘蛛(Scrapy下載器是建立在twisted這個高效的非同步模型上的)
- 爬蟲(Spiders) :爬蟲是主要幹活的, 用於從特定的網頁中提取自己需要的資訊, 即所謂的實體(Item)。使用者也可以從中提取出連結,讓Scrapy繼續抓取下一個頁面
- 專案管道(Pipeline) :負責處理爬蟲從網頁中抽取的實體,主要的功能是持久化實體、驗證實體的有效性、清除不需要的資訊。當頁面被爬蟲解析後,將被髮送到專案管道,並經過幾個特定的次序處理資料。
- 下載器中介軟體(Downloader Middlewares) :位於Scrapy引擎和下載器之間的框架,主要是處理Scrapy引擎與下載器之間的請求及響應。
- 爬蟲中介軟體(Spider Middlewares) :介於Scrapy引擎和爬蟲之間的框架,主要工作是處理蜘蛛的響應輸入和請求輸出。
- 排程中介軟體(Scheduler Middewares) :介於Scrapy引擎和排程之間的中介軟體,從Scrapy引擎傳送到排程的請求和響應。
Scrapy執行流程大概如下:
- 引擎從排程器中取出一個連結(URL)用於接下來的抓取
- 引擎把URL封裝成一個請求(Request)傳給下載器
- 下載器把資源下載下來,並封裝成應答包(Response)
- 爬蟲解析Response
- 解析出實體(Item),則交給實體管道進行進一步的處理
- 解析出的是連結(URL),則把URL交給排程器等待抓取
搭建Scrapy環境
新建虛擬環境
python3 -m venv /data/code/python/venv/venv_Scrapy
升級pip
/data/code/python/venv/venv_Scrapy/bin/pip3 install --upgrade pip
pip安裝Scrapy
/data/code/python/venv/venv_Scrapy/bin/pip3 install Scrapy
建立專案
新建Scrapy專案tutorial
#進入虛擬環境
cd /data/code/python/venv/venv_Scrapy/
#新建專案tutorial
./bin/python3 ./bin/scrapy startproject tutorial
tutorial專案結構
tutorial/
├── tutorial
│ ├── __init__.py
│ ├── items.py
│ ├── middlewares.py
│ ├── pipelines.py
│ ├── settings.py
│ └── spiders
│ └── __init__.py
└── scrapy.cfg
其中:
- scrapy.cfg : 專案配置檔案。
- settings.py : 該檔案定義了一些設定,如使用者代理,爬取延時等,詳細說明。
- items.py : 該檔案定義了待抓取域的模型,詳細說明。
- pipelines.py : 該檔案定義了資料的儲存方式(處理要抓取的域),可以是檔案,資料庫或者其他。詳細說明
- middlewares.py: 爬蟲中介軟體,該檔案可定義隨機切換ip或者使用者代理的函式。詳細說明
genspider命令新建爬蟲
genspider語法
- 語法:
scrapy genspider [-t template] <name> <domain>
新建百度爬蟲
#進入虛擬環境
cd /data/code/python/venv/venv_Scrapy/
#新建百度爬蟲
../bin/python3 ../bin/scrapy genspider -t basic baidu_search www.baidu.com
baidu_search.py
# -*- coding: utf-8 -*-
import scrapy
class BaiduSearchSpider(scrapy.Spider):
name = 'baidu_search'
allowed_domains = ['www.baidu.com']
start_urls = ['http://www.baidu.com/']
def parse(self, response):
pass
scrapy.Spider
class scrapy.spiders.Spider
Spider是最簡單的spider。每個其他的spider必須繼承自該類(包括Scrapy自帶的其他spider以及您自己編寫的spider)。 Spider並沒有提供什麼特殊的功能。 其僅僅提供了 start_requests()的預設實現,讀取並請求spider屬性中的 start_urls, 並根據返回的結果(resulting responses)呼叫spider的 parse方法。
-
name
定義spider名字的字串(string)。spider的名字定義了Scrapy如何定位(並初始化)spider,所以其必須是唯一的。 不過您可以生成多個相同的spider例項(instance),這沒有任何限制。 name是spider最重要的屬性,而且是必須的。
如果該spider爬取單個網站(single domain),一個常見的做法是以該網站(domain)(加或不加 字尾 )來命名spider。 例如,如果spider爬取 mywebsite.com ,該spider通常會被命名為 mywebsite 。 -
allowed_domains
可選。包含了spider允許爬取的域名(domain)列表(list)。 當 OffsiteMiddleware 啟用時, 域名不在列表中的URL不會被跟進。 -
start_urls
URL列表。當沒有指定特定的URL時,spider將從該列表中開始進行爬取。 因此,第一個被獲取到的頁面的URL將是該列表之一。 後續的URL將會從獲取到的資料中提取。
crawl開始爬蟲
- 語法:
scrapy crawl <spider>
#進入虛擬環境
cd /data/code/python/venv/venv_Scrapy/
#crawl開始爬蟲
../bin/python3 ../bin/scrapy crawl baidu_search
Forbidden by robots.txt
2018-12-05 13:15:04 [scrapy.utils.log] INFO: Scrapy 1.5.1 started (bot: tutorial)
2018-12-05 13:15:04 [scrapy.utils.log] INFO: Versions: lxml 4.2.5.0, libxml2 2.9.8, cssselect 1.0.3, parsel 1.5.1, w3lib 1.19.0, Twisted 18.9.0, Python 3.7.0 (v3.7.0:1bf9cc5093, Jun 26 2018, 23:26:24) - [Clang 6.0 (clang-600.0.57)], pyOpenSSL 18.0.0 (OpenSSL 1.1.0j 20 Nov 2018), cryptography 2.4.2, Platform Darwin-16.7.0-x86_64-i386-64bit
2018-12-05 13:15:04 [scrapy.crawler] INFO: Overridden settings: {'BOT_NAME': 'tutorial', 'DUPEFILTER_CLASS': 'scrapy_splash.SplashAwareDupeFilter', 'HTTPCACHE_STORAGE': 'scrapy_splash.SplashAwareFSCacheStorage', 'NEWSPIDER_MODULE': 'tutorial.spiders', 'ROBOTSTXT_OBEY': True, 'SPIDER_MODULES': ['tutorial.spiders']}
2018-12-05 13:15:04 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.memusage.MemoryUsage',
'scrapy.extensions.logstats.LogStats']
2018-12-05 13:15:04 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware',
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy_splash.SplashCookiesMiddleware',
'scrapy_splash.SplashMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2018-12-05 13:15:04 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy_splash.SplashDeduplicateArgsMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2018-12-05 13:15:04 [scrapy.middleware] INFO: Enabled item pipelines:
['tutorial.pipelines.QQVideoCommentPipeline']
2018-12-05 13:15:04 [scrapy.core.engine] INFO: Spider opened
2018-12-05 13:15:04 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2018-12-05 13:15:04 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023
2018-12-05 13:15:04 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.baidu.com/robots.txt> (referer: None)
2018-12-05 13:15:04 [scrapy.downloadermiddlewares.robotstxt] DEBUG: Forbidden by robots.txt: <GET http://www.baidu.com/>
2018-12-05 13:15:05 [scrapy.core.engine] INFO: Closing spider (finished)
2018-12-05 13:15:05 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/exception_count': 1,
'downloader/exception_type_count/scrapy.exceptions.IgnoreRequest': 1,
'downloader/request_bytes': 281,
'downloader/request_count': 1,
'downloader/request_method_count/GET': 1,
'downloader/response_bytes': 677,
'downloader/response_count': 1,
'downloader/response_status_count/200': 1,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2018, 12, 5, 5, 15, 5, 55729),
'log_count/DEBUG': 3,
'log_count/INFO': 7,
'memusage/max': 53755904,
'memusage/startup': 53755904,
'response_received_count': 1,
'scheduler/dequeued': 1,
'scheduler/dequeued/memory': 1,
'scheduler/enqueued': 1,
'scheduler/enqueued/memory': 1,
'start_time': datetime.datetime(2018, 12, 5, 5, 15, 4, 737516)}
2018-12-05 13:15:05 [scrapy.core.engine] INFO: Spider closed (finished)
首次開啟爬蟲,可能會遇到Forbidden by robots.txt
robots協議
Robots協議(也稱為爬蟲協議、機器人協議等)的全稱是“網路爬蟲排除標準”(Robots Exclusion Protocol),網站通過Robots協議告訴搜尋引擎哪些頁面可以抓取,哪些頁面不能抓取。
訪問一下 https://www.baidu.com/robots.txt
最後我們可以看見
.....
User-agent: *
Disallow: /
簡單來說,就是百度禁止一切爬蟲。當然,尊不遵守君子協定就看你個人了。我們這裡先到 settings.py 禁止掉
ROBOTSTXT_OBEY
編輯 settings.py 修改以下設定
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
爬取百度首頁
這裡我們修改 baidu_search.py 列印百度首頁
# -*- coding: utf-8 -*-
import scrapy
class BaiduSearchSpider(scrapy.Spider):
name = 'baidu_search_'
allowed_domains = ['www.baidu.com']
start_urls = ['http://www.baidu.com/']
def parse(self, response):
print(response.text)
再次執行,就可以看到我們已經拿到了百度的首頁了
../bin/python3 ../bin/scrapy crawl baidu_search