
常見的目標檢測演算法介紹
2018-12-05 21:12:15
一、滑動視窗目標檢測
首先通過卷積神經網路訓練一個分類器,然後使用不同尺度的視窗去裁剪輸入圖片進行分類。我們期望的結果是通過不同的視窗可以將需要檢測的物體完全覆蓋到,此時分類器輸出的置信值會大於閾值,這個時候我們就認為已經成功檢測到一個物體,並且得到了其位置資訊。
滑動視窗演算法的缺點是很明顯的就是計算量非常大,如果採用粗粒度的框進行框選,雖然可以減少計算量,但是毫無疑問會降低演算法精度。



二、R-CNN系列 - Two Stage目標檢測演算法
以上提到的滑動視窗演算法執行過慢的原因之一就是有很多裁剪下來的視窗是明顯不符合條件的視窗,而這些視窗也將被傳給分類器進行分類,為什麼我們不能對這些視窗先進行一下過濾再進行分類操作呢?
1)Region Proposal : R-CNN
R-CNN即Region CNN,就是不再對滑動視窗產生的所有圖片進行分類,而是隻在一些特定的候選框上進行分類操作。早期的R-CNN挑選候選框的方式是通過一些影象的特徵如顏色,紋理,邊緣等資訊來尋找可能存在目標物體的候選框,這些候選框被稱為ROI,即Region of Interest,大概會產生2000個感興趣的區域,然後使用分類器對這些ROIs進行分類操作。
R-CNN輸出為label + bounding box,也就是說這個網路並不直接使用ROI的box作為最後的區域座標,而是會對這個區域進行一次迴歸,得到預測的值。
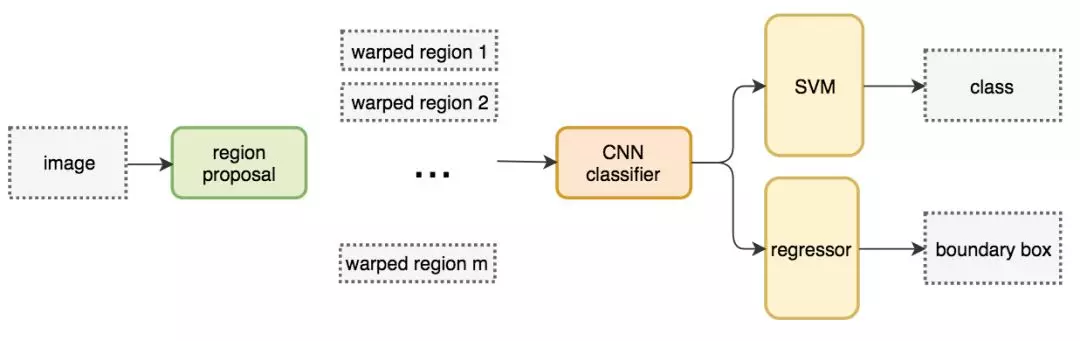
2)Fast RCNN
Fast R-CNN針對這兩個問題做了相應的改進。
- FCN,一次性對所有提取得到的圖片進行預測,大大提高了速度。
- ROI pooling層,使用ROI Pooling從而不需要對影象進行裁剪,很好的解決了這個問題。ROI pooling的思路是,如果最終我們要生成MxN的圖片,那麼先將特徵圖水平和豎直分為M和N份,然後每一份取最大值,輸出MxN的特徵圖。這樣就實現了固定尺寸的圖片輸出了。ROI pooling層位於卷積後,全連線前。
Fast R-CNN 的訓練速度是 R-CNN 的 10 倍,推斷速度是後者的 150 倍。
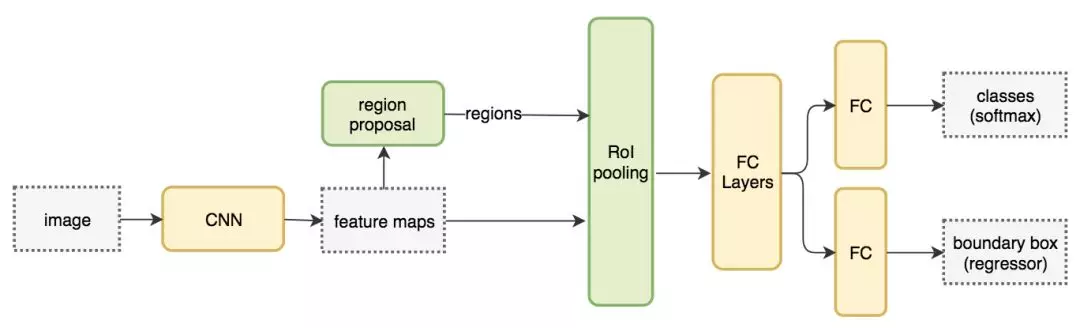
3)Faster R-CNN : Fast R-CNN 依賴於外部候選區域方法,如選擇性搜尋。但這些演算法在 CPU 上執行且速度很慢。在測試中,Fast R-CNN 需要 2.3 秒來進行預測,其中 2 秒用於生成 2000 個 ROI。Faster R-CNN 採用與 Fast R-CNN 相同的設計,只是它用內部深層網路代替了候選區域方法。新的候選區域網路(RPN)在生成 ROI 時效率更高,並且以每幅影象 10 毫秒的速度執行。
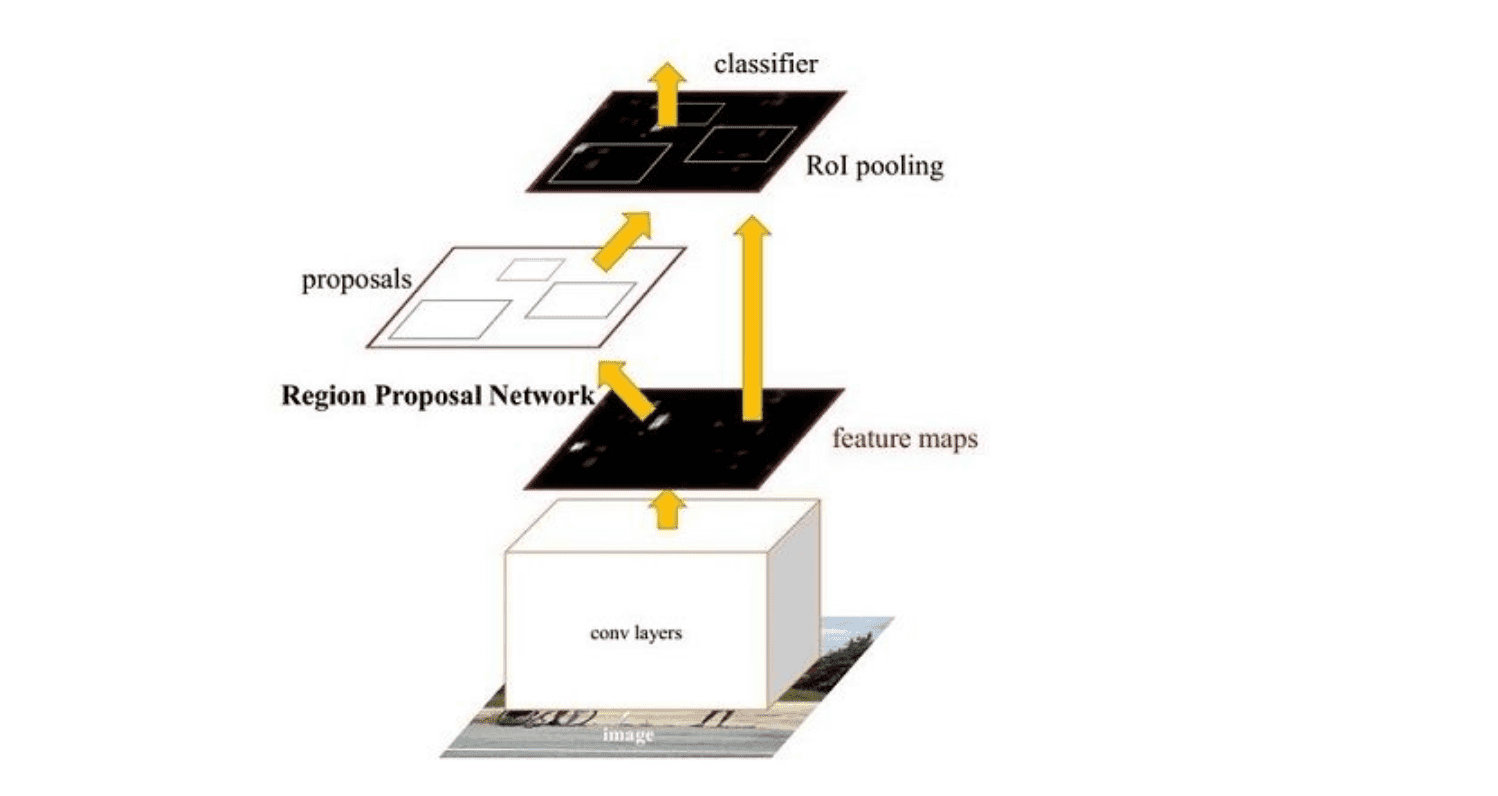
主要分為四個步驟
-
卷積層。原始圖片先經過conv-relu-pooling的多層卷積神經網路,提取出特徵圖。供後續的RPN網路和全連線層使用。faster R-CNN不像R-CNN需要對每個子圖進行卷積層特徵提取,它只需要對全圖進行一次提取就可以了,從而大大減小了計算時間。
-
RPN層,region proposal networks。RPN層用於生成候選框,並利用softmax判斷候選框是前景還是背景,從中選取前景候選框(因為物體一般在前景中),並利用bounding box regression調整候選框的位置,從而得到特徵子圖,稱為proposals。
-
ROI層,fast R-CNN中已經講過了ROI層了,它將大小尺寸不同的proposal池化成相同的大小,然後送入後續的全連線層進行物體分類和位置調整迴歸
-
分類層。利用ROI層輸出的特徵圖proposal,判斷proposal的類別,同時再次對bounding box進行regression從而得到精確的形狀和位置。
作者:紫衣仙女
連結:https://www.imooc.com/article/37757
來源:慕課網
主要分為四個步驟
- 卷積層,原始圖片先經過conv-relu-pooling的多層卷積神經網路,提取出特徵圖。供後續的RPN網路和全連線層使用。faster R-CNN不像R-CNN需要對每個子圖進行卷積層特徵提取,它只需要對全圖進行一次提取就可以了,從而大大減小了計算時間。
- RPN層,region proposal networks。RPN層用於生成候選框,並利用softmax判斷候選框是前景還是背景,從中選取前景候選框(因為物體一般在前景中),並利 bounding box regression調整候選框的位置,從而得到特徵子圖,稱為proposals。
- ROI層,fast R-CNN中已經講過了ROI層了,它將大小尺寸不同的proposal池化成相同的大小,然後送入後續的全連線層進行物體分類和位置調整迴歸
- 分類層,利用ROI層輸出的特徵圖proposal,判斷proposal的類別,同時再次對bounding box進行regression從而得到精確的形狀和位置。
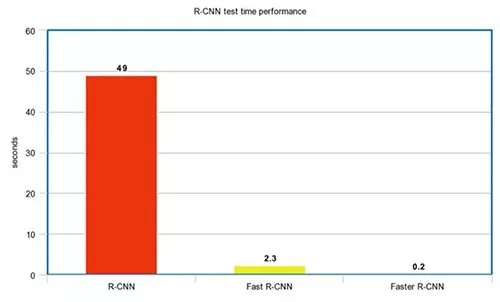
R-CNN系列的效能圖:
三、YOLO、SSD - One Stage目標檢測演算法
由於CNN網路的輸入影象尺寸必須是固定的某一個大小(否則全連線時沒法計算),故R-CNN中對大小形狀不同的候選框,進行了裁剪和縮放,使得他們達到相同的尺寸。這個操作既浪費時間,又容易導致影象資訊丟失和形變。fast R-CNN在全連線層之前插入了ROI pooling層,從而不需要對影象進行裁剪,很好的解決了這個問題。
作者:紫衣仙女
連結:https://www.imooc.com/article/37757
來源:慕課網
由於CNN網路的輸入影象尺寸必須是固定的某一個大小(否則全連線時沒法計算),故R-CNN中對大小形狀不同的候選框,進行了裁剪和縮放,使得他們達到相同的尺寸。這個操作既浪費時間,又容易導致影象資訊丟失和形變。fast R-CNN在全連線層之前插入了ROI pooling層,從而不需要對影象進行裁剪,很好的解決了這個問題。
作者:紫衣仙女
連結:https://www.imooc.com/article/37757
來源:慕課網
基於區域的檢測器是很準確的,但需要付出效能的代價。採用One Stage的演算法的效率往往要好於two stage演算法,因為one stage可以一次性得到邊界框和類別。
1)YOLO : You Only Look Once
針對於two-stage目標檢測演算法普遍存在的運算速度慢的缺點,yolo創造性的提出了one-stage。也就是將物體分類和物體定位在一個步驟中完成。yolo直接在輸出層迴歸bounding box的位置和bounding box所屬類別,從而實現one-stage。通過這種方式,yolo可實現45幀每秒的運算速度,完全能滿足實時性要求
作者:紫衣仙女
連結:https://www.imooc.com/article/37757
來源:慕課網
針對於two-stage目標檢測演算法普遍存在的運算速度慢的缺點,yolo創造性的提出了one-stage。也就是將物體分類和物體定位在一個步驟中完成。yolo直接在輸出層迴歸bounding box的位置和bounding box所屬類別,從而實現one-stage。通過這種方式,yolo可實現45幀每秒的運算速度,完全能滿足實時性要求。其網路結構如下:
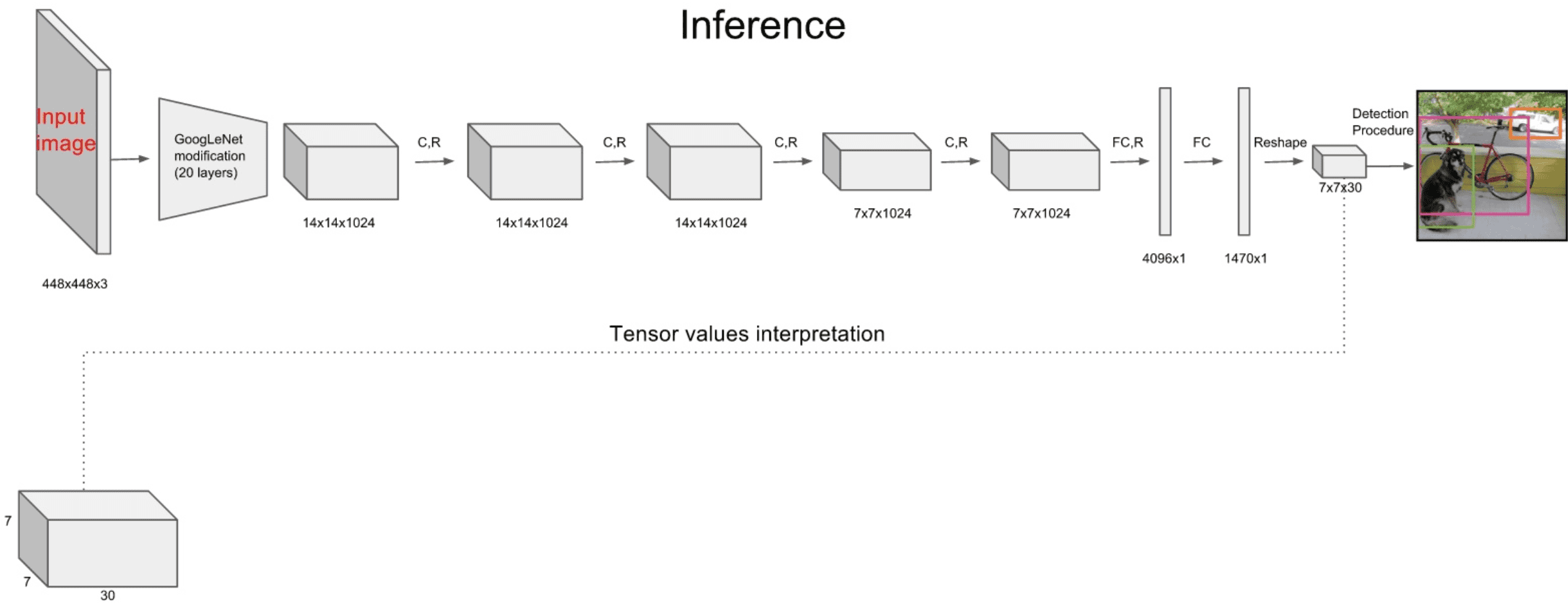
YOLO主要分為三個部分:卷積層,目標檢測層,NMS篩選層。
卷積層:採用Google inceptionV1網路,對應到上圖中的第一個階段,共20層。這一層主要是進行特徵提取,從而提高模型泛化能力。但作者對inceptionV1進行了改造,他沒有使用inception module結構,而是用一個1x1的卷積,並聯一個3x3的卷積來替代。(可以認為只使用了inception module中的一個分支,應該是為了簡化網路結構)
採用Google inceptionV1網路,對應到上圖中的第一個階段,共20層。這一層主要是進行特徵提取,從而提高模型泛化能力。但作者對inceptionV1進行了改造,他沒有使用inception module結構,而是用一個1x1的卷積,並聯一個3x3的卷積來替代。(可以認為只使用了inception module中的一個分支,應該是為了簡化網路結構)
作者:紫衣仙女
連結:https://www.imooc.com/article/37757
來源:慕課網
主要分為三個部分:卷積層,目標檢測層,NMS篩選層
作者:紫衣仙女
連結:https://www.imooc.com/article/37757
來源:慕課網
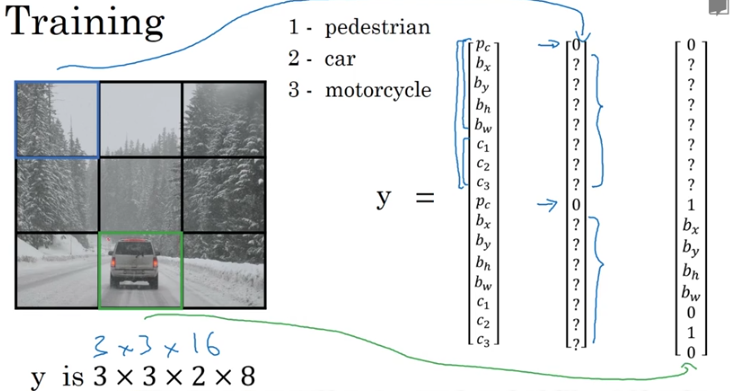
目標檢測層:先經過4個卷積層和2個全連線層,最後生成7x7x30的輸出。先經過4個卷積層的目的是為了提高模型泛化能力。yolo將一副448x448的原圖分割成了7x7個網格,每個網格要預測兩個bounding box的座標(x,y,w,h)和box內包含物體的置信度confidence,以及物體屬於20類別中每一類的概率(yolo的訓練資料為voc2012,它是一個20分類的資料集)。所以一個網格對應的引數為(4x2+2+20) = 30。如下圖:

NMS篩選層:篩選層是為了在多個結果中(多個bounding box)篩選出最合適的幾個,這個方法和faster R-CNN 中基本相同。都是先過濾掉score低於閾值的box,對剩下的box進行NMS非極大值抑制,去除掉重疊度比較高的box(NMS具體演算法可以回顧上面faster R-CNN小節)。這樣就得到了最終的最合適的幾個box和他們的類別。
先經過4個卷積層和2個全連線層,最後生成7x7x30的輸出。先經過4個卷積層的目的是為了提高模型泛化能力。yolo將一副448x448的原圖分割成了7x7個網格,每個網格要預測兩個bounding box的座標(x,y,w,h)和box內包含物體的置信度confidence,以及物體屬於20類別中每一類的概率(yolo的訓練資料為voc2012,它是一個20分類的資料集)。所以一個網格對應的引數為(4x2+2+20) = 30。如下圖
作者:紫衣仙女
連結:https://www.imooc.com/article/37757
來源:慕課網
YOLO演算法的缺點:
對於圖片中比較小的物體,效果很差。這其實是所有目標檢測演算法的通病,SSD對它有些優化,我們後面再看。
作者:紫衣仙女
連結:https://www.imooc.com/article/37757
來源:慕課網
- 每個網格只對應兩個bounding box,當物體的長寬比不常見(也就是訓練資料集覆蓋不到時),效果很差。
- 原始圖片只劃分為7x7的網格,當兩個物體靠的很近時,效果很差。
- 最終每個網格只對應一個類別,容易出現漏檢(物體沒有被識別到)。
- 對於圖片中比較小的物體,效果很差。這其實是所有目標檢測演算法的通病,SSD對它有些優化,我們後面再看。
2)SSD : Single Shot MultiBox Detector
Single Shot MultiBox Detector
作者:紫衣仙女
連結:https://www.imooc.com/article/37757
來源:慕課網
Faster R-CNN準確率mAP較高,漏檢率recall較低,但速度較慢。而yolo則相反,速度快,但準確率和漏檢率不盡人意。SSD綜合了他們的優缺點,對輸入300x300的影象,在voc2007資料集上test,能夠達到58 幀每秒( Titan X 的 GPU ),72.1%的mAP。
SSD網路結構如下圖:
SSD網路結構如下圖
作者:紫衣仙女
連結:https://www.imooc.com/article/37757
來源:慕課網
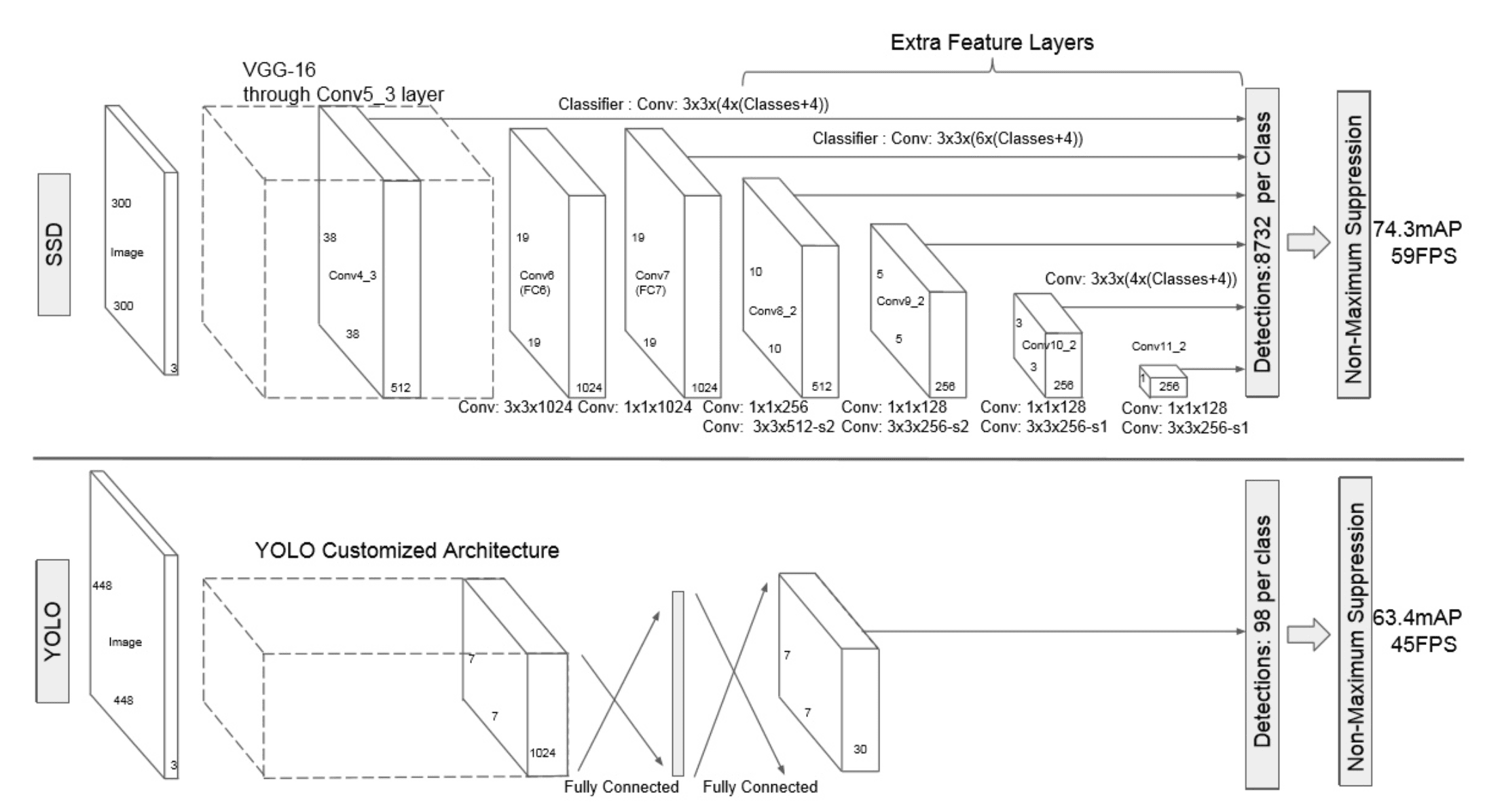
卷積層:SSD論文采用了VGG16的基礎網路,其實這也是幾乎所有目標檢測神經網路的慣用方法。先用一個CNN網路來提取特徵,然後再進行後續的目標定位和目標分類識別。
目標檢測層:這一層由5個卷積層和一個平均池化層組成。去掉了最後的全連線層。SSD認為目標檢測中的物體,只與周圍資訊相關,它的感受野不是全域性的,故沒必要也不應該做全連線。SSD的特點如下:
- 多尺寸feature map上進行目標檢測。每一個卷積層,都會輸出不同大小感受野的feature map。在這些不同尺度的feature map上,進行目標位置和類別的訓練和預測,從而達到多尺度檢測的目的,可以克服yolo對於寬高比不常見的物體,識別準確率較低的問題。而yolo中,只在最後一個卷積層上做目標位置和類別的訓練和預測。這是SSD相對於yolo能提高準確率的一個關鍵所在。
- 多個anchors,每個anchor對應4個位置引數和21個類別引數。
NMS篩選層:和yolo的篩選層基本一致,同樣先過濾掉類別概率低於閾值的default box,再採用NMS非極大值抑制,篩掉重疊度較高的。只不過SSD綜合了各個不同feature map上的目標檢測輸出的default box。
和yolo的篩選層基本一致,同樣先過濾掉類別概率低於閾值的default box,再採用NMS非極大值抑制,篩掉重疊度較高的。只不過SSD綜合了各個不同feature map上的目標檢測輸出的default box。
作者:紫衣仙女
連結:https://www.imooc.com/article/37757
來源:慕課網
Single Shot MultiBox Detector
作者:紫衣仙女
連結:https://www.imooc.com/article/37757
來源:慕課網