
目標檢測演算法中的常見trick
轉自:https://zhuanlan.zhihu.com/p/39262769
目標檢測演算法中的常見trick
最近忙著打比賽,感覺看論文也很難靜下心來了。基本上看得相當匆忙,主要還是以應用為主。上週壓力比較大,沒有來得及更新,感覺再不更就說不過去了。
因為比賽比較追求performance,所以想著把以前看到的一些trick或者還不夠了解的trick稍作整理,以後發現新的就更新到這裡。像BN和dropout的使用或者align、fpn這些常見的or偏向演算法層面的就不提了。主要還是探討一些DL演算法以外的東西吧。
另外因為個人還是見識不夠,所以希望大家能在評論裡多多留言補充討論。
目錄如下:
- Data Augmentation
- OHEM
- Soft NMS
- Multi Scale Training/Testing
Data Augmentation
中文來說叫資料增廣,資料增廣可以增加資料集的數量和多樣性,從而提升演算法的最終效果。卷積具有平移不變性,因此資料增廣一般使用的是更為複雜的策略,例如翻轉、旋轉或者裁切、放縮。下面說的Multi Scale Training其實也可以看做資料增廣的一種。
考慮到實現的方便性,目前比較常見的實現一般是隨機對影象進行翻轉,網路允許的話,也會加入一些隨機放縮到一組特定尺寸中的某個。
裁切倒是在SSD裡看過,但是據說這部分原始碼實現比較混亂,有興趣的不妨研究下。
OHEM
即online hard example mining,從名字也可以看出它和Hard Negative Mining有一定的關係。這裡給出R-FCN論文中對它的描述:

概況地說,OHEM不是隨機選擇正負樣本,而是會對所有RoIs的損失進行評估,選擇那些loss大的樣本來優化網路。
Soft NMS
NMS想必大家都很熟悉了,對於下圖這種情況,NMS可以有效篩除多餘的檢測框,讓結果更加精準

但是另一些情況,NMS會把重疊、貼近的目標篩掉,比如下圖中的人和馬因為貼的太近,很容易被NMS排除掉一個框……
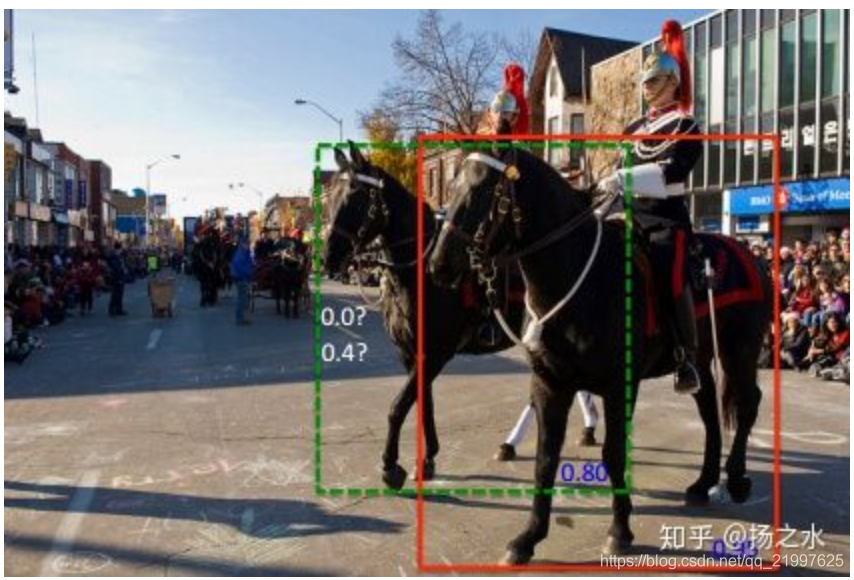
在這種情況下,Soft NMS就提出了,它們兩種演算法的區別在於:

可以看到,NMS演算法本身是先對得分進行排序,然後從輸出結果挑出其中得分最高的放入最終輸出的檢測結果的部分,接著遍歷剩下的框,如果IoU重疊超過某個閾值,就直接排除掉這個框;遍歷一次之後,再從剩下的框裡按得分排序,挑出得分最高的加入最終輸出的結果……如此不斷迴圈直到最後輸出結果裡所有的框都被挑出來或者排除掉……
Soft NMS本質上只改變了一步,就是IoU如果超過某個閾值,不再是直接排除掉這個框,而是降低它的得分。得分如果低到一定程度就會被排除,但是如果降低後仍然比較高,就有保留下來的機會。
降低分數的方法有線性和高斯:
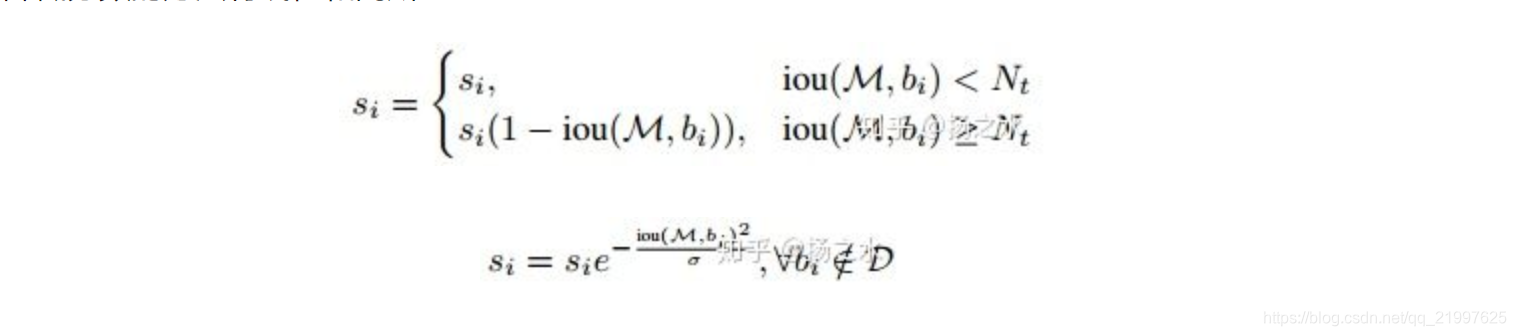
個人 感覺softnms對遮擋嚴重情況處理較好,否則效果不一定好不好
圖識別ining/Testing
很多網路並不關注輸入影象的size,在這種情況下,可以在訓練的時候將一張影象隨機resize到多個尺寸中的一個進行訓練,而測試的時候可以將影象resize各個尺寸,得到不同尺度的框做NMS,思路和影象金字塔比較像。
前者可以有效增加資料的多樣性,提高網路的效能。而即使沒有使用Multi Scale Training也一樣可以使用Multi Scale Testing,一般來說對提升performance也有幫助。