
Zookeeper叢集的搭建與經驗總結
阿新 • • 發佈:2018-12-06
(003)最近用到了Zookeeper來構建一個分散式的應用服務,順便就把自己的操作方法記錄了下來
在Hadoop生態系統中Zookeeper還是比較容易安裝部署的
Zookeeper叢集的搭建
原料:
- 三臺伺服器(我用的是三臺虛擬機器)
- zookeeper-3.4.13.tar.gz
附件:
連結:https://pan.baidu.com/s/1TG86uDKkhpz3LCtoamKj5Q
提取碼:pkio
叢集的劃分
我是這樣劃分叢集的
192.168.225.100 – master
192.168.225.101 – slave1
192.168.225.102 – slave2
安裝步驟
1.將安裝包上傳到master主機上(我這裡放在了/opt/bigdata目錄下了)
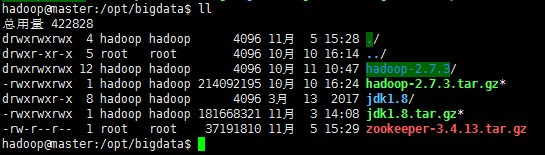
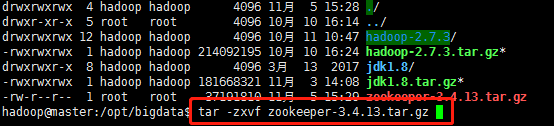
2.解壓安裝包
3.新增環境變數(使用root使用者新增,用hadoop使用者使之生效)

注:(slave1和slave2做出同樣的修改)
4.使用source /etc/profile命令使之生效

5.修改配置檔案(zoo.cfg)
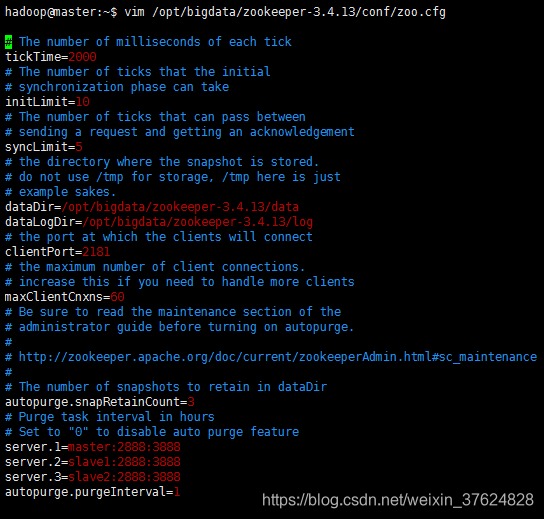
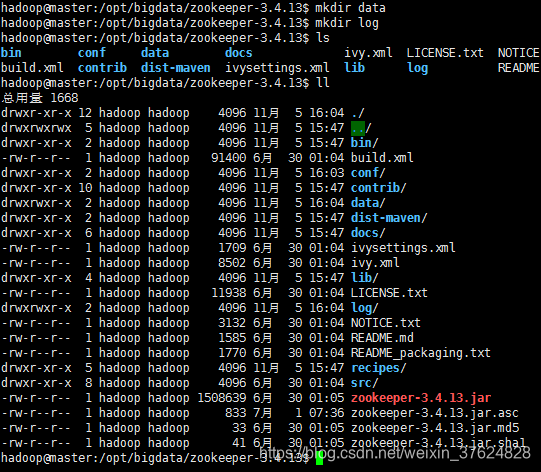
6.在/opt/bigdata/zookeeper-3.4.13目錄下建立data和log目錄
7.將zookeeper-3.4.13資料夾傳送到slave1和slave2節點上
命令:
$ scp -r /opt/bigdata/zookeeper-3.4.13/ [email protected]
$ scp -r /opt/bigdata/zookeeper-3.4.13/ [email protected]:/opt/bigdata/


8.新增myid(slave1和slave2做同樣的操作)
定位到/opt/bigdata/zookeeper-3.4.13/data目錄下,輸入如下命令建立名為myid的新檔案,建立完成後儲存。
$ vim myid



Zookeeper的啟動與驗證
啟動(每個節點都要啟動)
$ zkServer.sh start

驗證
1.jps命令驗證
命令:
$ jps

2.狀態驗證


總結(踩過的坑)
1.如果一遍沒有配置成功,修改配置啟動之前需要把之前產生的臨時檔案刪除
例如:zookeeper_server.pid檔案

2.關閉防火牆保證各個節點可以互訪
3.配置檔案中不能出現空格