
搭建Hadoop叢集方法與經驗總結
(002)最近要研發一款資料傳輸服務的產品需要用到Hadoop叢集,之前搭建過後來長時間不用就給忘記了,這次搭好來記錄一下搭建方法與經驗總結
Hadoop叢集的搭建
原料:
- VM虛擬機器
- JDK1.8
- hadoop2.7.3
注:將jdk1.8.tar.gz和hadoop-2.7.3.tar.gz放在/opt/bigdata目錄下(沒有請自行建立) 附件:
設計叢集
以一主兩從為例搭建叢集環境,在VM虛擬機器中建立三個 具體設計如下: 192.168.225.100 -- master(主機),namenode, jobtracker -- master(主機名) 192.168.225.101 -- slave1(從機),datanode, tasktracker -- slave1(主機名) 192.168.225.102 -- slave2(從機),datanode,tasktracker -- slave2(主機名)
建立使用者
命令:
# useradd hadoop
# id hadoop
# passwd hadoop
注:我這裡設定的密碼是123456,需要打兩遍
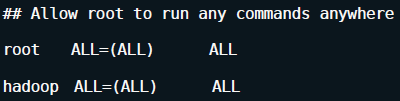
使hadoop使用者成為sudoers,以root使用者修改檔案/etc/sudoers,
命令:
# vim /etc/sudoers
 修改資料夾許可權
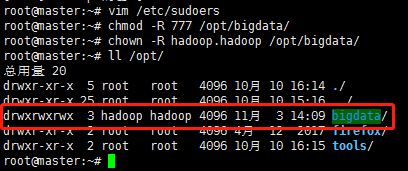
我未來準備將hadoop安裝到/opt/bigdata資料夾下,所以希望修改該資料夾許可權,使hadoop使用者能夠自由操作該資料夾下的所有檔案
修改資料夾許可權
我未來準備將hadoop安裝到/opt/bigdata資料夾下,所以希望修改該資料夾許可權,使hadoop使用者能夠自由操作該資料夾下的所有檔案
安裝JDK
解壓檔案
 移動資料夾
移動資料夾
 刪除資料夾
刪除資料夾
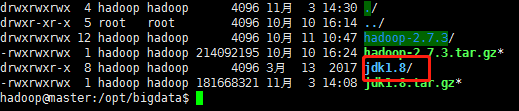
 注:移動資料夾和刪除資料夾這兩步可以不做,應該是我拿到這個jdk安裝包中間多打了兩層目錄,如果其他包沒有這個問題就不用做這兩步,最後做到如下圖目錄效果就可以了
注:移動資料夾和刪除資料夾這兩步可以不做,應該是我拿到這個jdk安裝包中間多打了兩層目錄,如果其他包沒有這個問題就不用做這兩步,最後做到如下圖目錄效果就可以了
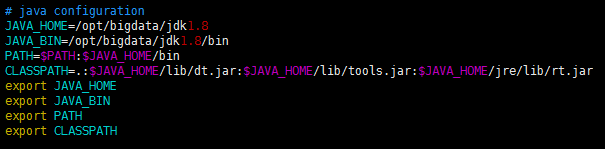
 配置JDK環境變數(以root身份配置)
配置JDK環境變數(以root身份配置)
 使profile檔案生效
使profile檔案生效
 使用java命令檢視jdk版本以驗證是否安裝成功
使用java命令檢視jdk版本以驗證是否安裝成功

搭建Hadoop叢集
解壓檔案
 檢視目錄列表
檢視目錄列表
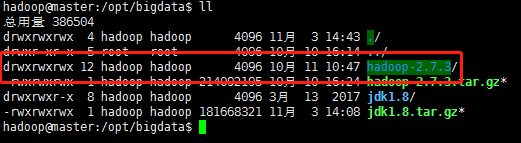 在hadoop目錄下建立tmp目錄,並將許可權設定為777
命令:
$ mkdir tmp
$ chmod 777 tmp
$ mkdir dfs
$ mkdir dfs/name
$ mkdir dfs/data
修改hadoop配置檔案
待修改清單:
在hadoop目錄下建立tmp目錄,並將許可權設定為777
命令:
$ mkdir tmp
$ chmod 777 tmp
$ mkdir dfs
$ mkdir dfs/name
$ mkdir dfs/data
修改hadoop配置檔案
待修改清單:
- core-site.xml
- hdfs-site.xml
- mapred-stie.xml
- yarn-site.xml
- masters
- slaves
進入hadoop配置檔案目錄
修改 hadoop-env.sh

 修改 mapred-env.sh
修改 mapred-env.sh
 修改 yarn-env.sh
修改 yarn-env.sh
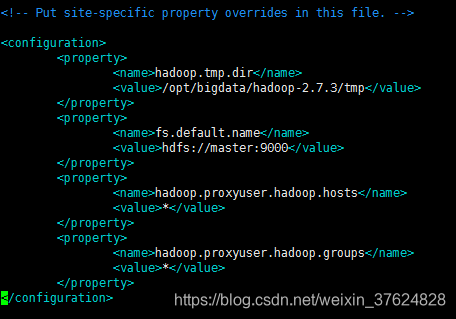
 修改 core-site.xml
修改 core-site.xml
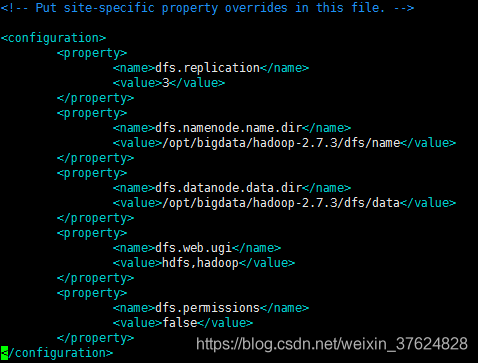
 修改 hdfs-site.xml
修改 hdfs-site.xml
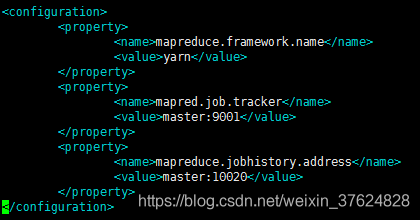
 修改 mapred-site.xml
修改 mapred-site.xml
 修改 yarn-site.xml
修改 yarn-site.xml
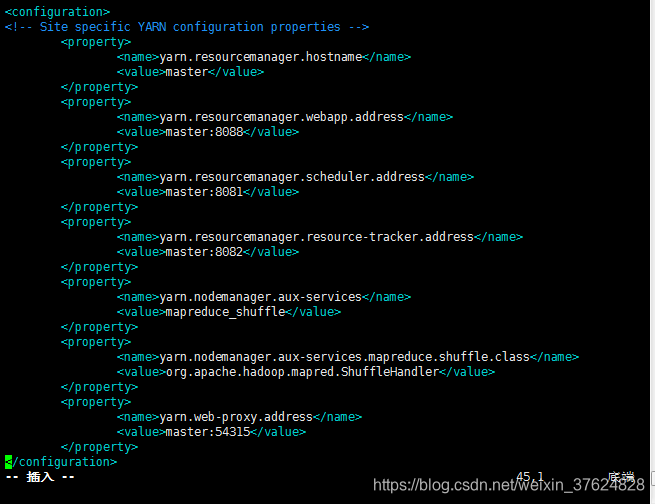 修改 slaves (master、slave1和slave2均作為datanode)
修改 slaves (master、slave1和slave2均作為datanode)
 配置系統變數
命令:
$ sudo su - root
123456
配置系統變數
命令:
$ sudo su - root
123456
vim /etc/profile
 使配置生效(切換回hadoop使用者)
命令:
$ source /etc/profile
將hadoop、jdk、以及配置檔案傳送到slave1、slave2節點
命令:(以slave1為例,slave2同理)
$ scp -r /opt/bigdata/hadoop-2.7.3 [email protected]:/opt/bigdata/
$ scp -r /opt/bigdata/jdk1.8 [email protected]:/opt/bigdata/
注:slave1和slave2的/etc/profile檔案按照master/etc/profile重新配置一遍(我是利用xftp從master下載並分別上傳至slave1和slave2中的)
修改hosts檔案(使用root使用者)
為了使外部應用可以訪問到服務(slave1和salve2同理)
命令:
使配置生效(切換回hadoop使用者)
命令:
$ source /etc/profile
將hadoop、jdk、以及配置檔案傳送到slave1、slave2節點
命令:(以slave1為例,slave2同理)
$ scp -r /opt/bigdata/hadoop-2.7.3 [email protected]:/opt/bigdata/
$ scp -r /opt/bigdata/jdk1.8 [email protected]:/opt/bigdata/
注:slave1和slave2的/etc/profile檔案按照master/etc/profile重新配置一遍(我是利用xftp從master下載並分別上傳至slave1和slave2中的)
修改hosts檔案(使用root使用者)
為了使外部應用可以訪問到服務(slave1和salve2同理)
命令:
vim /etc/hosts
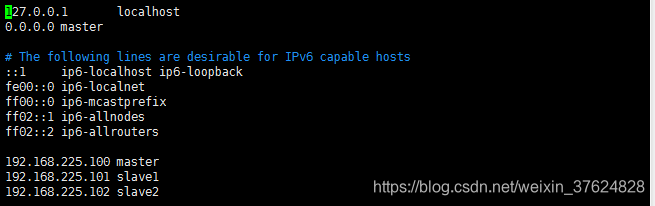
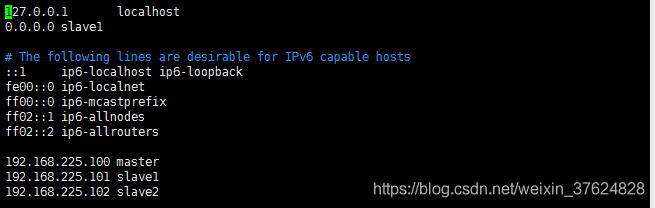
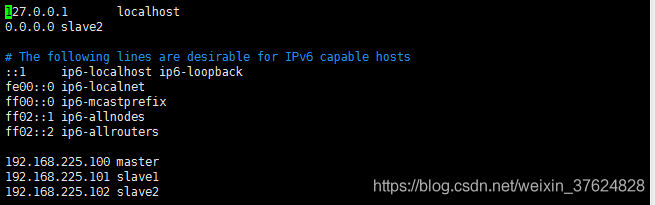 修改由於拷貝造成的datanodeid重複
命令:(slave1和slave2同理)
$ vim /opt/bigdata/hadoop-2.7.3/dfs/data/current/VERSION
master:
修改由於拷貝造成的datanodeid重複
命令:(slave1和slave2同理)
$ vim /opt/bigdata/hadoop-2.7.3/dfs/data/current/VERSION
master:
 slave1:
slave1:
 slave2:
slave2:
 注:我這裡改動了datanodeUuid的後兩位
授權(hadoop使用者,目錄定位到home目錄即:~)
master給自己和salve1,slave2發證書
命令:(初次授權一路回車)
$ ssh-keygen
$ ssh-copy-id -i .ssh/id_rsa.pub [email protected]
$ ssh-copy-id -i .ssh/id_rsa.pub [email protected]
$ ssh-copy-id -i .ssh/id_rsa.pub [email protected]
注:我這裡改動了datanodeUuid的後兩位
授權(hadoop使用者,目錄定位到home目錄即:~)
master給自己和salve1,slave2發證書
命令:(初次授權一路回車)
$ ssh-keygen
$ ssh-copy-id -i .ssh/id_rsa.pub [email protected]
$ ssh-copy-id -i .ssh/id_rsa.pub [email protected]
$ ssh-copy-id -i .ssh/id_rsa.pub [email protected]
slave1給master發證書(基礎狀態和master一致) $ ssh-keygen $ ssh-copy-id -i .ssh/id_rsa.pub [email protected]
slave2給master發證書(基礎狀態和master一致) $ ssh-keygen $ ssh-copy-id -i .ssh/id_rsa.pub [email protected] 測試 使用ssh從master登入到slave1,然後再從slave1登入到master,接著從master登入到slave2,最後從salve2登入到master 命令:(從master主機開始) $ ssh slave1 $ ssh master $ ssh slave2 $ ssh master
啟動叢集
啟動叢集有兩種方法,一種是全部啟動,一種是分步啟動
方法一(全部啟動):
定位到/opt/bigdata/hadoop-2.7.3/sbin/目錄下,輸入./start-all.sh命令
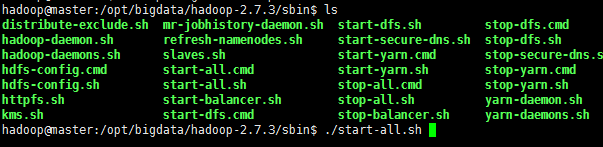 方法二(分佈啟動)
啟動HDFS
命令:
$ ./start-hdfs.sh
啟動YARN
$ ./start-yarn.sh
方法二(分佈啟動)
啟動HDFS
命令:
$ ./start-hdfs.sh
啟動YARN
$ ./start-yarn.sh
驗證
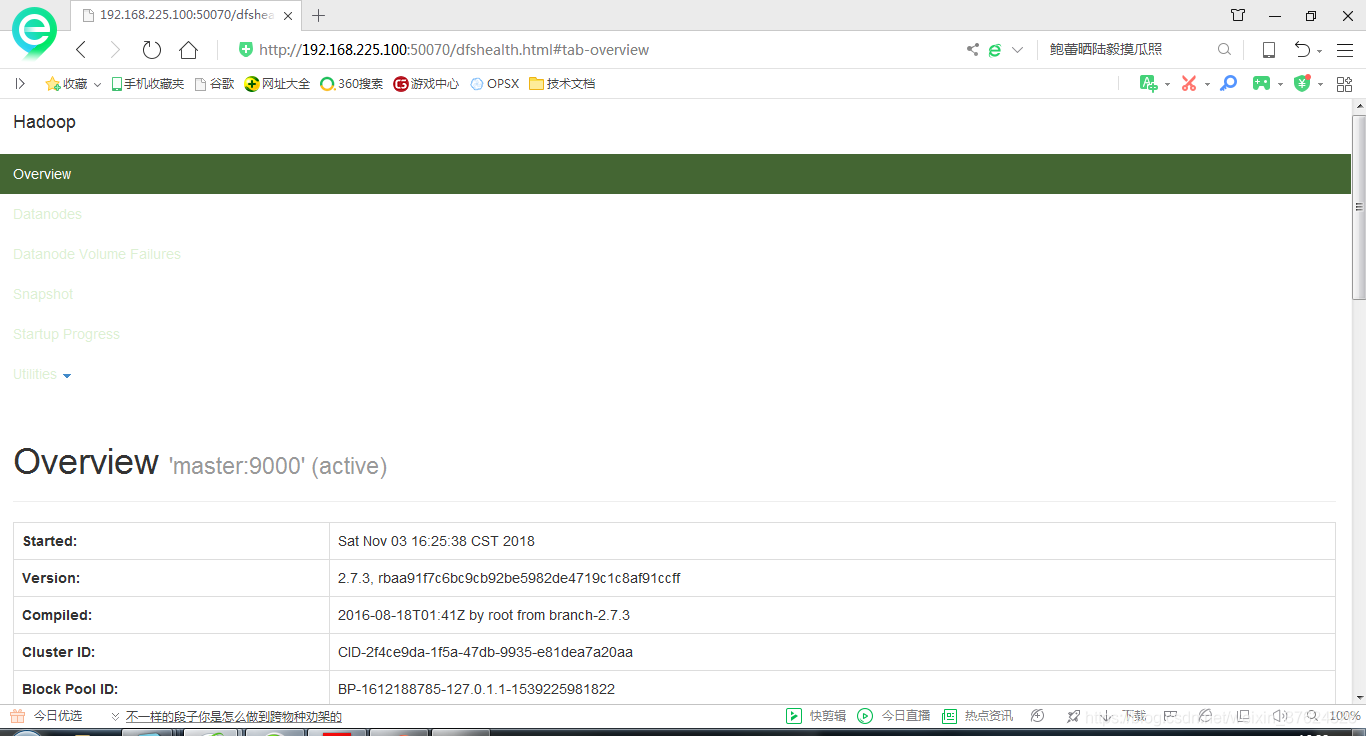
web介面
在瀏覽器中輸入 http://192.168.225.100:50070
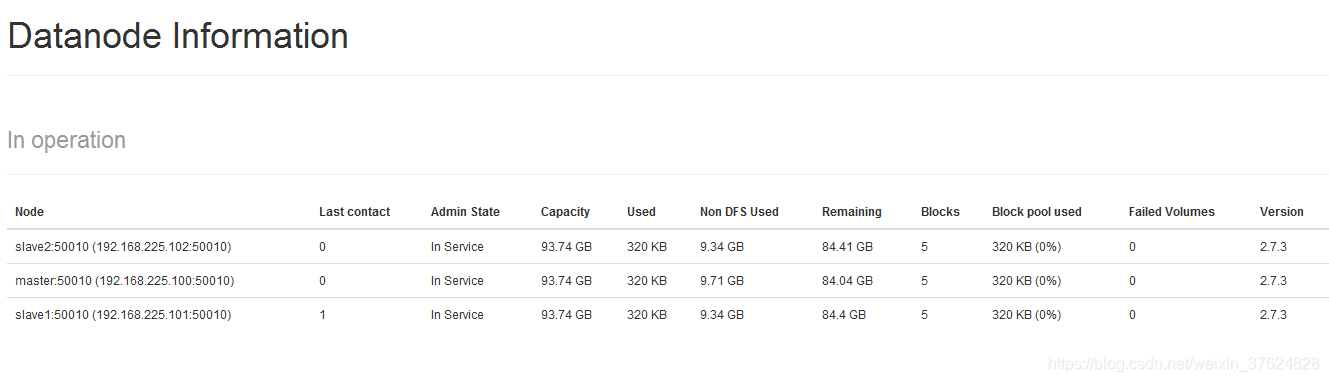
 點選Datanodes頁面
點選Datanodes頁面
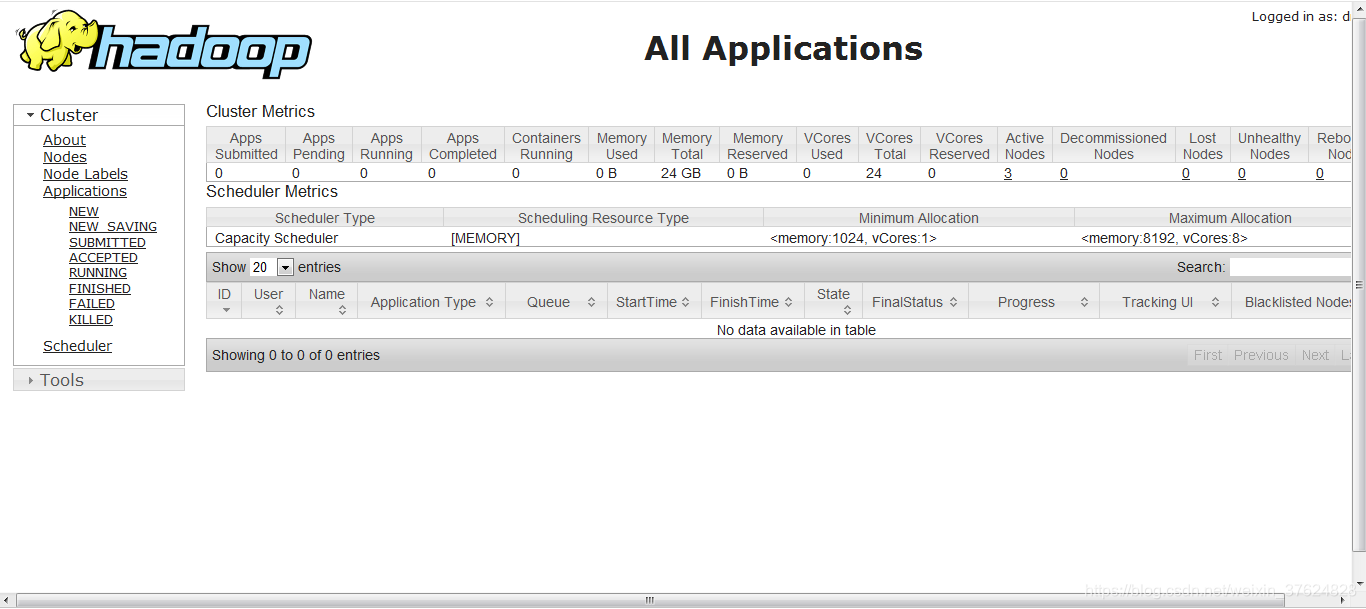
 在瀏覽器中輸入http://192.168.225.100:8088
在瀏覽器中輸入http://192.168.225.100:8088
 測試程式
在叢集上執行一個小程式來測試一下我們的叢集有沒有問題
以wordcount程式為例
使用hadoop命令建立一個測試目錄
測試程式
在叢集上執行一個小程式來測試一下我們的叢集有沒有問題
以wordcount程式為例
使用hadoop命令建立一個測試目錄
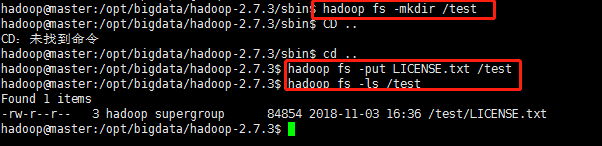 執行如下命令:
執行如下命令:
 檢視結果:
$ hadoop fs -cat /test/part-r-00000
檢視結果:
$ hadoop fs -cat /test/part-r-00000
 注:部分結果。
注:部分結果。
總結
一個完美的叢集是很需要花時間和心思研究它的每一個細節的……