
人工智慧(三):決策樹
前面介紹的SVM方法中都是針對樣本特徵為數量特徵的,但是在實際生活中,還有一些非數值特徵的問題,如何進行解決呢?非數值特徵具有離散,無法比較大小,無法比較相似性,只能比較相同或者不相同的特點。為了解決這個問題,可以採用把特徵轉化為實數特徵,但是這樣做可能會損失一部分資料特徵,也會加入一些人為的因素,因為我們無法完全用實數描述特徵;還可以採用非數值特徵分類,比如列出所有的屬性來代替實數向量,比如櫻桃資訊為{紅色,小,圓形,甜},但是我們如何用這些非數值特徵進行分類呢?
一、決策樹構造
在這裡引出了本文想要介紹的一種方法:決策樹。
1.1 介紹決策樹
決策樹(decision tree):是一種基本的分類與迴歸方法,此處主要討論分類的決策樹。

其中每一個內部節點代表一個屬性,每一個分支代表了相應屬性的值,每一個葉節點代表了分類結果。
決策樹學習的演算法通常是一個遞迴地選擇最優特徵,並根據該特徵對訓練資料進行分割,使得各個子資料集有一個最好的分類的過程。這一過程對應著對特徵空間的劃分,也對應著決策樹的構建。(我們以ID3演算法為例)
1) 開始:構建根節點,將所有訓練資料都放在根節點,選擇一個最優特徵,按著這一特徵將訓練資料集分割成子集,使得各個子集有一個在當前條件下最好的分類。
2) 如果這些子集已經能夠被基本正確分類,那麼構建葉節點,並將這些子集分到所對應的葉節點去。
3)如果還有子集不能夠被正確的分類,那麼就對這些子集選擇新的最優特徵,繼續對其進行分割,構建相應的節點,如果遞迴進行,直至所有訓練資料子集被基本正確的分類,或者沒有合適的特徵為止。
4)每個子集都被分到葉節點上,即都有了明確的類,這樣就生成了一顆決策樹。
舉個例子:假如我們已經選擇了一個分裂的屬性,那怎樣對資料進行分裂呢?
1、分裂屬性的資料型別分為離散型和連續性兩種情況,對於離散型的資料,按照屬性值進行分裂,每個屬性值對應一個分裂節點;對於連續性屬性,一般性的做法是對資料按照該屬性進行排序,再將資料分成若干區間,如[0,10]、[10,20]、[20,30]…,一個區間對應一個節點,若資料的屬性值落入某一區間則該資料就屬於其對應的節點。
例:
| 職業 |
年齡 |
是否貸款 |
| 白領 |
30 |
否 |
| 工人 |
40 |
否 |
| 工人 |
20 |
否 |
| 學生 |
15 |
否 |
| 學生 |
18 |
是 |
| 白領 |
42 |
是 |
(1)屬性1“職業”是離散型變數,有三個取值,分別為白領、工人和學生,根據三個取值對原始的資料進行分割,如下表所示:
表1.2 屬性1資料分割表
| 取值 |
貸款 |
不貸款 |
| 白領 |
1 |
1 |
| 工人 |
0 |
2 |
| 學生 |
1 |
1 |
表1.2可以表示成如下的決策樹結構:

(2)屬性2是連續性變數,這裡將資料分成三個區間,分別是[10,20]、[20,30]、[30,40],則每一個區間的分裂結果如下:
屬性1.3 資料分割表
| 區間 |
貸款 |
不貸款 |
| [0,20] |
1 |
2 |
| (20,40] |
0 |
2 |
| (40,—] |
1 |
0 |
表1.3可以表示成如下的決策樹結構:

1.2、分裂屬性的選擇
我們知道了分裂屬性是如何對資料進行分割的,那麼我們怎樣選擇分裂的屬性呢?
決策樹採用貪婪思想進行分裂,即選擇可以得到最優分裂結果的屬性進行分裂。那麼怎樣才算是最優的分裂結果?最理想的情況當然是能找到一個屬性剛好能夠將不同類別分開,但是大多數情況下分裂很難一步到位,我們希望每一次分裂之後孩子節點的資料儘量”純”,以下圖為例:
從圖1.1和圖1.2可以明顯看出,屬性2分裂後的孩子節點比屬性1分裂後的孩子節點更純:屬性1分裂後每個節點的兩類的數量還是相同,跟根節點的分類結果相比完全沒有提高;按照屬性2分裂後每個節點各類的數量相差比較大,可以很大概率認為第一個孩子節點的輸出結果為類1,第2個孩子節點的輸出結果為2。
選擇分裂屬性是要找出能夠使所有孩子節點資料最純的屬性,決策樹使用資訊增益或者資訊增益率作為選擇屬性的依據。
- 資訊增益
用資訊增益表示分裂前後跟的資料複雜度和分裂節點資料複雜度的變化值,計算公式表示為: 其中Gain表示節點的複雜度,Gain越高,說明覆雜度越高。資訊增益說白了就是分裂前的資料複雜度減去孩子節點的資料複雜度的和,資訊增益越大,分裂後的複雜度減小得越多,分類的效果越明顯。
節點的複雜度可以用以下兩種不同的計算方式:
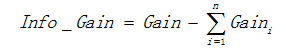
1)熵
熵描述了資料的混亂程度,熵越大,混亂程度越高,也就是純度越低;反之,熵越小,混亂程度越低,純度越高。 熵的計算公式如下所示:

其中Pi表示類i的數量佔比。以二分類問題為例,如果兩類的數量相同,此時分類節點的純度最低,熵等於1;如果節點的資料屬於同一類時,此時節點的純度最高,熵等於0。
舉例程式碼如下:
from math import log
"""
函式說明:建立測試資料集
Parameters:無
Returns:
dataSet:資料集
labels:分類屬性
"""
def creatDataSet():
# 資料集
dataSet=[[0, 0, 0, 0, 'no'],
[0, 0, 0, 1, 'no'],
[0, 1, 0, 1, 'yes'],
[0, 1, 1, 0, 'yes'],
[0, 0, 0, 0, 'no'],
[1, 0, 0, 0, 'no'],
[1, 0, 0, 1, 'no'],
[1, 1, 1, 1, 'yes'],
[1, 0, 1, 2, 'yes'],
[1, 0, 1, 2, 'yes'],
[2, 0, 1, 2, 'yes'],
[2, 0, 1, 1, 'yes'],
[2, 1, 0, 1, 'yes'],
[2, 1, 0, 2, 'yes'],
[2, 0, 0, 0, 'no']]
#分類屬性
labels=['年齡','有工作','有自己的房子','信貸情況']
#返回資料集和分類屬性
return dataSet,labels
"""
函式說明:計算給定資料集的經驗熵(夏農熵)
Parameters:
dataSet:資料集
Returns:
shannonEnt:經驗熵
"""
def calcShannonEnt(dataSet):
#返回資料集行數
numEntries=len(dataSet)
#儲存每個標籤(label)出現次數的字典
labelCounts={}
#對每組特徵向量進行統計
for featVec in dataSet:
currentLabel=featVec[-1] #提取標籤資訊
if currentLabel not in labelCounts.keys(): #如果標籤沒有放入統計次數的字典,新增進去
labelCounts[currentLabel]=0
labelCounts[currentLabel]+=1 #label計數
shannonEnt=0.0 #經驗熵
#計算經驗熵
for key in labelCounts:
prob=float(labelCounts[key])/numEntries #選擇該標籤的概率
shannonEnt-=prob*log(prob,2) #利用公式計算
return shannonEnt #返回經驗熵
#main函式
if __name__=='__main__':
dataSet,features=creatDataSet()
print("該資料集的經驗熵為:%.3f" % (calcShannonEnt(dataSet)))結果如下:

b)基尼值
基尼值計算公式如下:
其中Pi表示類i的數量佔比。其同樣以上述熵的二分類例子為例,當兩類數量相等時,基尼值等於0.5 ;當節點資料屬於同一類時,基尼值等於0 。基尼值越大,資料越不純。
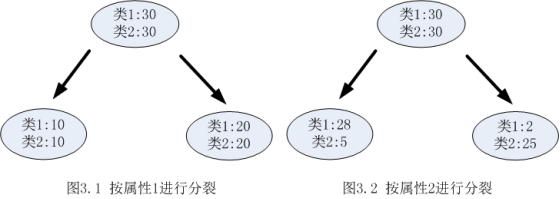
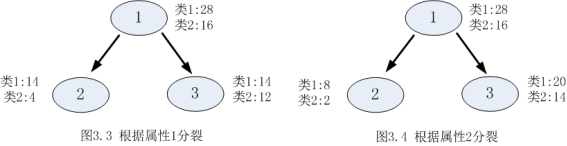
以熵作為節點複雜度的統計量,分別求出下面例子的資訊增益,圖3.1表示節點選擇屬性1進行分裂的結果,圖3.2表示節點選擇屬性2進行分裂的結果,通過計算兩個屬性分裂後的資訊增益,選擇最優的分裂屬性。
屬性1:

屬性2:

由於 ,![]() 所以屬性1與屬性2相比是更優的分裂屬性,故選擇屬性1作為分裂的屬性。
所以屬性1與屬性2相比是更優的分裂屬性,故選擇屬性1作為分裂的屬性。
1.3、資訊增益率
使用資訊增益作為選擇分裂的條件有一個不可避免的缺點:傾向選擇分支比較多的屬性進行分裂。為了解決這個問題,引入了資訊增益率這個概念。資訊增益率是在資訊增益的基礎上除以分裂節點資料量的資訊增益(聽起來很拗口),其計算公式如下:
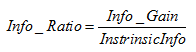
其中 表示資訊增益, 表示分裂子節點資料量的資訊增益,其計算公式為:
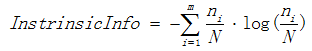
其中m表示子節點的數量,![]() 表示第i個子節點的資料量,N表示父節點資料量,說白了,
表示第i個子節點的資料量,N表示父節點資料量,說白了,![]() 其實是分裂節點的熵,如果節點的資料鏈越接近,
其實是分裂節點的熵,如果節點的資料鏈越接近,![]() 越大,如果子節點越大,
越大,如果子節點越大,![]() 越大,而
越大,而![]() 就會越小,能夠降低節點分裂時選擇子節點多的分裂屬性的傾向性。資訊增益率越高,說明分裂的效果越好。
就會越小,能夠降低節點分裂時選擇子節點多的分裂屬性的傾向性。資訊增益率越高,說明分裂的效果越好。
還是資訊增益中提及的例子為例:
屬性1的資訊增益率:
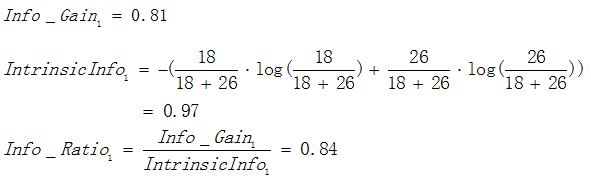
屬性2的資訊增益率:
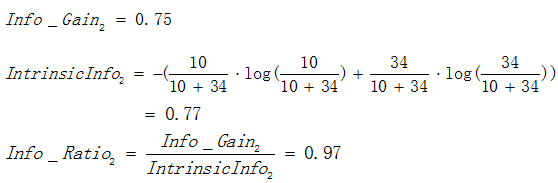
由於 ,故選擇屬性2作為分裂的屬性。
程式碼演示如下:
from math import log
"""
函式說明:建立測試資料集
Parameters:無
Returns:
dataSet:資料集
labels:分類屬性
"""
def creatDataSet():
# 資料集
dataSet=[[0, 0, 0, 0, 'no'],
[0, 0, 0, 1, 'no'],
[0, 1, 0, 1, 'yes'],
[0, 1, 1, 0, 'yes'],
[0, 0, 0, 0, 'no'],
[1, 0, 0, 0, 'no'],
[1, 0, 0, 1, 'no'],
[1, 1, 1, 1, 'yes'],
[1, 0, 1, 2, 'yes'],
[1, 0, 1, 2, 'yes'],
[2, 0, 1, 2, 'yes'],
[2, 0, 1, 1, 'yes'],
[2, 1, 0, 1, 'yes'],
[2, 1, 0, 2, 'yes'],
[2, 0, 0, 0, 'no']]
#分類屬性
labels=['年齡','有工作','有自己的房子','信貸情況']
#返回資料集和分類屬性
return dataSet,labels
"""
函式說明:計算給定資料集的經驗熵(夏農熵)
Parameters:
dataSet:資料集
Returns:
shannonEnt:經驗熵
"""
def calcShannonEnt(dataSet):
#返回資料集行數
numEntries=len(dataSet)
#儲存每個標籤(label)出現次數的字典
labelCounts={}
#對每組特徵向量進行統計
for featVec in dataSet:
currentLabel=featVec[-1] #提取標籤資訊
if currentLabel not in labelCounts.keys(): #如果標籤沒有放入統計次數的字典,新增進去
labelCounts[currentLabel]=0
labelCounts[currentLabel]+=1 #label計數
shannonEnt=0.0 #經驗熵
#計算經驗熵
for key in labelCounts:
prob=float(labelCounts[key])/numEntries #選擇該標籤的概率
shannonEnt-=prob*log(prob,2) #利用公式計算
return shannonEnt #返回經驗熵
"""
函式說明:資訊增益最大特徵的索引值
Parameters:
dataSet:資料集
Returns:
shannonEnt:資訊增益最大特徵的索引值
"""
def chooseBestFeatureToSplit(dataSet):
#特徵數量
numFeatures = len(dataSet[0]) - 1 #計數資料集的夏農熵
baseEntropy = calcShannonEnt(dataSet) #資訊增益
bestInfoGain = 0.0 #最優特徵的索引值
bestFeature = -1 #遍歷所有特徵
for i in range(numFeatures): # 獲取dataSet的第i個所有特徵
featList = [example[i] for example in dataSet]
#建立set集合{},元素不可重複
uniqueVals = set(featList) #經驗條件熵
newEntropy = 0.0 #計算資訊增益
for value in uniqueVals:
#subDataSet劃分後的子集
subDataSet = splitDataSet(dataSet, i, value)
#計運算元集的概率
prob = len(subDataSet) / float(len(dataSet))
#根據公式計算經驗條件熵
newEntropy += prob * calcShannonEnt((subDataSet))
#資訊增益
infoGain = baseEntropy - newEntropy
#列印每個特徵的資訊增益
print("第%d個特徵的增益為%.3f" % (i, infoGain))
#計算資訊增益
if (infoGain > bestInfoGain):
#更新資訊增益,找到最大的資訊增益
bestInfoGain = infoGain
#記錄資訊增益最大的特徵的索引值
bestFeature = i
#返回資訊增益最大特徵的索引值
return bestFeature
"""
函式說明:按照給定特徵劃分資料集
Parameters:
dataSet:待劃分的資料集
axis:劃分資料集的特徵
value:需要返回的特徵的值
Returns:
shannonEnt:經驗熵
"""
def splitDataSet(dataSet,axis,value):
retDataSet=[]
for featVec in dataSet:
if featVec[axis]==value:
reducedFeatVec=featVec[:axis]
reducedFeatVec.extend(featVec[axis+1:])
retDataSet.append(reducedFeatVec)
return retDataSet
#main函式
if __name__=='__main__':
dataSet,features=creatDataSet()
# print(dataSet)
# print(calcShannonEnt(dataSet))
print("最優索引值:"+str(chooseBestFeatureToSplit(dataSet)))
二、 決策樹的生成和修剪:
我們已經學習了從資料集構造決策樹演算法所需要的子功能模組,包括經驗熵的計算和最優特徵的選擇,其工作原理如下:得到原始資料集,然後基於最好的屬性值劃分資料集,由於特徵值可能多於兩個,因此可能存在大於兩個分支的資料集劃分。第一次劃分之後,資料集被向下傳遞到樹的分支的下一個結點。在這個結點上,我們可以再次劃分資料。因此我們可以採用遞迴的原則處理資料集。
構建決策樹的演算法有很多,比如C4.5、ID3和CART,這些演算法在執行時並不總是在每次劃分資料分組時都會消耗特徵。由於特徵數目並不是每次劃分資料分組時都減少,因此這些演算法在實際使用時可能引起一定的問題。目前我們並不需要考慮這個問題,只需要在演算法開始執行前計算列的數目,檢視演算法是否使用了所有屬性即可。
決策樹生成演算法遞迴地產生決策樹,直到不能繼續下去未為止。這樣產生的樹往往對訓練資料的分類很準確,但對未知的測試資料的分類卻沒有那麼準確,即出現過擬合現象。過擬合的原因在於學習時過多地考慮如何提高對訓練資料的正確分類,從而構建出過於複雜的決策樹。解決這個問題的辦法是考慮決策樹的複雜度,對已生成的決策樹進行簡化。
2.1 ID3演算法
ID3程式碼虛擬碼:

1)從根結點(root node)開始,對結點計算所有可能的特徵的資訊增益,選擇資訊增益最大的特徵作為結點的特徵。
2)由該特徵的不同取值建立子節點,再對子結點遞迴地呼叫以上方法,構建決策樹;直到所有特徵的資訊增益均很小或沒有特徵可以選擇為止;
3)最後得到一個決策樹。
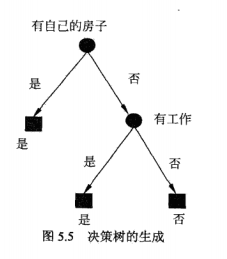
上面已經求得,特徵A3(有自己的房子)的資訊增益最大,所以選擇A3為根節點的特徵,它將訓練集D劃分為兩個子集D1(A3取值為“是”)D2(A3取值為“否”)。由於D1只有同一類的樣本點,所以它成為一個葉結點,結點的類標記為“是”。
對D2則需要從特徵A1(年齡),A2(有工作)和A4(信貸情況)中選擇新的特徵,計算各個特徵的資訊增益:
Gain(D2,A1)=Entropy(D2)-E(A1)=0.251 Gain(D2,A2)=Entropy(D2)-E(A2)=0.918
Gain(D2,A4)=Entropy(D2)-E(A4)=0.474
根據計算,選擇資訊增益最大的A2作為節點的特徵,由於其有兩個取值可能,所以引出兩個子節點:
①對應“是”(有工作),包含三個樣本,屬於同一類,所以是一個葉子節點,類標記為“是”。
②對應“否”(無工作),包含六個樣本,輸入同一類,所以是一個葉子節點,類標記為“否”。
這樣就生成一個決策樹,該樹只用了兩個特徵(有兩個內部節點),生成的決策樹如下圖所示:
3.2 C4.5生成演算法
C4.5算是ID3的演算法改進,將資訊增益率(GainRatio)來加以改進方法,選取有最大的分割變數作為準則,這種方法可以處理連續的數值特徵,其思想是用二(多)分法將連續的數值特徵離散化,對於每一種離散方案,計算資訊增益率,選取資訊增益率最大的方案來離散連續的數值特徵。
from math import log
import operator
"""
函式說明:計算給定資料集的經驗熵(夏農熵)
Parameters:
dataSet:資料集
Returns:
shannonEnt:經驗熵
"""
def calcShannonEnt(dataSet):
#返回資料集行數
numEntries=len(dataSet)
#儲存每個標籤(label)出現次數的字典
labelCounts={}
#對每組特徵向量進行統計
for featVec in dataSet:
currentLabel=featVec[-1] #提取標籤資訊
if currentLabel not in labelCounts.keys(): #如果標籤沒有放入統計次數的字典,新增進去
labelCounts[currentLabel]=0
labelCounts[currentLabel]+=1 #label計數
shannonEnt=0.0 #經驗熵
#計算經驗熵
for key in labelCounts:
prob=float(labelCounts[key])/numEntries #選擇該標籤的概率
shannonEnt-=prob*log(prob,2) #利用公式計算
return shannonEnt #返回經驗熵
"""
函式說明:建立測試資料集
Parameters:無
Returns:
dataSet:資料集
labels:分類屬性
"""
def createDataSet():
# 資料集
dataSet=[[0, 0, 0, 0, 'no'],
[0, 0, 0, 1, 'no'],
[0, 1, 0, 1, 'yes'],
[0, 1, 1, 0, 'yes'],
[0, 0, 0, 0, 'no'],
[1, 0, 0, 0, 'no'],
[1, 0, 0, 1, 'no'],
[1, 1, 1, 1, 'yes'],
[1, 0, 1, 2, 'yes'],
[1, 0, 1, 2, 'yes'],
[2, 0, 1, 2, 'yes'],
[2, 0, 1, 1, 'yes'],
[2, 1, 0, 1, 'yes'],
[2, 1, 0, 2, 'yes'],
[2, 0, 0, 0, 'no']]
#分類屬性
labels=['年齡','有工作','有自己的房子','信貸情況']
#返回資料集和分類屬性
return dataSet,labels
"""
函式說明:按照給定特徵劃分資料集
Parameters:
dataSet:待劃分的資料集
axis:劃分資料集的特徵
value:需要返回的特徵值
Returns:
無
"""
def splitDataSet(dataSet,axis,value):
#建立返回的資料集列表
retDataSet=[]
#遍歷資料集
for featVec in dataSet:
if featVec[axis]==value:
#去掉axis特徵
reduceFeatVec=featVec[:axis]
#將符合條件的新增到返回的資料集
reduceFeatVec.extend(featVec[axis+1:])
retDataSet.append(reduceFeatVec)
#返回劃分後的資料集
return retDataSet
"""
函式說明:計算資訊增益以及資訊增益最大特徵的索引值
Parameters:
dataSet:資料集
Returns:
shannonEnt:資訊增益最大特徵的索引值
"""
def chooseBestFeatureToSplit(dataSet):
#特徵數量
numFeatures = len(dataSet[0]) - 1
#計數資料集的夏農熵
baseEntropy = calcShannonEnt(dataSet)
#資訊增益
bestInfoGain = 0.0
#最優特徵的索引值
bestFeature = -1
#遍歷所有特徵
for i in range(numFeatures):
# 獲取dataSet的第i個所有特徵
featList = [example[i] for example in dataSet]
#建立set集合{},元素不可重複
uniqueVals = set(featList)
#經驗條件熵
newEntropy = 0.0
#計算資訊增益
for value in uniqueVals:
#subDataSet劃分後的子集
subDataSet = splitDataSet(dataSet, i, value)
#計運算元集的概率
prob = len(subDataSet) / float(len(dataSet))
#根據公式計算經驗條件熵
newEntropy += prob * calcShannonEnt((subDataSet))
#資訊增益
infoGain = baseEntropy - newEntropy
#列印每個特徵的資訊增益
print("第%d個特徵的增益為%.3f" % (i, infoGain))
#計算資訊增益
if (infoGain > bestInfoGain):
#更新資訊增益,找到最大的資訊增益
bestInfoGain = infoGain
#記錄資訊增益最大的特徵的索引值
bestFeature = i
#返回資訊增益最大特徵的索引值
return bestFeature
"""
函式說明:統計classList中出現次數最多的元素(類標籤)
Parameters:
classList:類標籤列表
Returns:
sortedClassCount[0][0]:出現次數最多的元素(類標籤)
"""
def majorityCnt(classList):
classCount={}
#統計classList中每個元素出現的次數
for vote in classList:
if vote not in classCount.keys():
classCount[vote]=0
classCount[vote]+=1
#根據字典的值降序排列 sortedClassCount=sorted(classCount.items(),key=operator.itemgetter(1),reverse=True)
return sortedClassCount[0][0]
"""
函式說明:建立決策樹
Parameters:
dataSet:訓練資料集
labels:分類屬性標籤
featLabels:儲存選擇的最優特徵標籤
Returns:
myTree:決策樹
"""
def createTree(dataSet,labels,featLabels):
#取分類標籤(是否放貸:yes or no)
classList=[example[-1] for example in dataSet]
#如果類別完全相同,則停止繼續劃分
if classList.count(classList[0])==len(classList):
return classList[0]
#遍歷完所有特徵時返回出現次數最多的類標籤
if len(dataSet[0])==1:
return majorityCnt(classList) #選擇最優特徵
bestFeat=chooseBestFeatureToSplit(dataSet) #最優特徵的標籤
bestFeatLabel=labels[bestFeat]
featLabels.append(bestFeatLabel) #根據最優特徵的標籤生成樹
myTree={bestFeatLabel:{}} #刪除已經使用的特徵標籤
del(labels[bestFeat]) #得到訓練集中所有最優特徵的屬性值
featValues=[example[bestFeat] for example in dataSet]
#去掉重複的屬性值
uniqueVls=set(featValues) #遍歷特徵,建立決策樹
for value in uniqueVls:
myTree[bestFeatLabel][value]=createTree(splitDataSet(dataSet,bestFeat,value),labels,featLabels)
return myTree
if __name__=='__main__':
dataSet,labels=createDataSet()
featLabels=[]
myTree=createTree(dataSet,labels,featLabels)
print(myTree)結果如下:

2.2決策樹剪枝
決策樹生成演算法遞迴的產生決策樹,直到不能繼續下去為止,這樣產生的樹往往對訓練資料的分類很準確,但對未知測試資料的分類卻沒有那麼精確,即會出現過擬合(也稱過學習)現象。過擬合產生的原因在於在學習時過多的考慮如何提高對訓練資料的正確分類,從而構建出過於複雜的決策樹,解決方法是考慮決策樹的複雜度,對已經生成的樹進行簡化。這裡介紹奧卡姆剃刀準則:
- 選擇最簡單的方法(假設最少)來解釋實際問題
- 當你有兩個處於競爭地位的理論能得到同樣的結論時,那麼簡單的那個更好。
即假設越少,越不像巧合。
ID3/C4.5就是在選擇更小的樹,因為資訊增益越高的屬性越接近根部,樹很快就變純,符合奧卡姆剃刀準則。
即可以通過剪枝來實現:剪枝(pruning),從已經生成的樹上裁掉一些子樹或葉節點,並將其根節點或父節點作為新的葉子節點,從而簡化分類樹模型,極小化決策樹整體的損失函式或代價函式來實現。
決策樹學習的損失函式定義為:
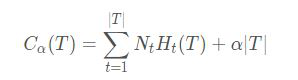
其中,T表示這棵子樹的葉子節點;H(T)表示第t個葉子的熵;Nt表示該葉子所含的訓練樣例的個數;α表示懲罰係數。
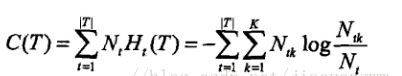
所以:![]()
其中C(T)表示模型對訓練資料的預測誤差,即模型與訓練資料的擬合程度;α表示引數>=0控制兩者之間的影響控制兩者之間的影響,較大的α促使選擇較簡單的模型(樹),較小的α促使選擇較複雜的模型(樹),α=0意味著只考慮模型與訓練資料的擬合程度,不考慮模型的複雜度。
剪枝就是當α確定時,選擇損失函式最小的模型,即損失函式最小的子樹。
當α值確定時,子樹越大,往往與訓練資料的擬合越好,但是模型的複雜度越高;子樹越小,模型的複雜度就越低,但是往往與訓練資料的擬合不好;損失函式正好表示了對兩者的平衡。
損失函式認為對於每個分類終點(葉子節點)的不確定性程度就是分類的損失因子,而葉子節點的個數是模型的複雜程度,作為懲罰項,損失函式的第一項是樣本的訓練誤差,第二項是模型的複雜度。如果一棵子樹的損失函式值越大,說明這棵子樹越差,因此我們希望讓每一棵子樹的損失函式值儘可能得小,損失函式最小化就是用正則化的極大似然估計進行模型選擇的過程。
決策樹的剪枝過程(泛化過程)就是從葉子節點開始遞迴,記其父節點將所有子節點回縮後的子樹為Tb(分類值取類別比例最大的特徵值),未回縮的子樹為,如果說明回縮後使得損失函式減小了,那麼應該使這棵子樹回縮,遞迴直到無法回縮為止,這樣使用“貪心”的思想進行剪枝可以降低損失函式值,也使決策樹得到泛化。可以看出,決策樹的生成只是考慮通過提高資訊增益對訓練資料進行更好的擬合,而決策樹剪枝通過優化損失函式還考慮了減小模型複雜度。公式定義的損失函式的極小化等價於正則化的極大似然估計,剪枝過程示意圖:

樹的剪枝演算法:
輸入:生成演算法產生整個樹T,引數;
輸出:修剪後的子樹;
- 計算每個結點的資訊熵
- 遞迴地從樹的葉結點向上回縮;
剪枝分為先剪枝與後剪枝。
先剪枝是指在決策樹的生成過程中,對每個節點在劃分前先進行評估,若當前的劃分不能帶來泛化效能的提升,則停止劃分,並將當前節點標記為葉節點。但因為決策樹是貪婪演算法,缺乏後效性考慮,可能導致決策樹提前停止。
後剪枝是指先從訓練集生成一顆完整的決策樹,然後自底向上對非葉節點進行考察,若將該節點對應的子樹替換為葉節點,能帶來泛化效能的提升,則將該子樹替換為葉節點。後剪枝在實際應用更為成功,因為資訊利用充分,缺點是可能計算代價大。