
全文檢索技術 && Lucene
1.全文檢索技術理論基礎
1.全文檢索技術的解決方案
原來的方法和實現搜尋功能的流程圖:
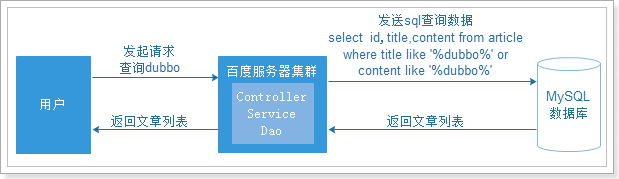
傳統的搜尋引擎技術,在一般資料庫資料量比較小,使用者量比較小的時候是比較常見的
但是在資料量增加到一定的量級的時候,資料庫的壓力就會變得很大,查詢的速度會很慢,我們需要更好的解決方案來分擔資料庫的壓力
使用全文檢索技術的解決方案:

為了解決資料庫的壓力和速度的問題,我們的資料庫變成了索引庫,我們通過Lucene的API來操作伺服器上的索引庫,這樣完全和資料庫進行了隔離,從索引庫中查詢資料非常的快,但是在建立索引庫的過程很慢,但是這個不影響我們在業務上的使用.
2.資料的查詢方法
- 順序掃描法
所謂順序掃描法,在Windows中磁碟搜尋框中搜索一個字串的時候使用的就是順序掃描法,開啟第一個資料夾把裡面的檔案從頭看到尾,再開啟第二個資料夾...這樣以此類推直到遍歷完磁碟中的所有檔案為止,就叫順序掃描法,這種搜尋方式如果資料量大速度很慢
- 倒排索引法
所謂倒排意思就是順序掃描法是先找文件從文件中找出搜尋項
倒排索引法是先在索引中找關鍵詞,再根據索引去找檔案,所以是倒序
Lucene會對文件建立倒排索引:
1.提取資源中的關鍵資訊,建立索引(目錄)
2.搜尋時,根據關鍵字(目錄),找到資源的位置
例如我們的新華字典查詢漢字,查字的時候先查目錄(索引),找到我想要找的字的頁數,在根據這個頁數去文件中找漢字
3.全文檢索的特點
- 做了相關度排序
- 對文字中的關鍵字進行高亮顯示
- 摘要擷取
- 搜尋效果更加精確,因為是基於單詞搜尋,比如搜尋java時不會搜尋出來JavaScript ,因為他們是兩個不同的單詞
- 只關注文字單詞,不關注語義
4.索引和搜尋的流程圖

建立索引流程:
- 原始文件:原始文件有三類:網頁,資料庫,磁碟中的檔案中獲取到需要搜尋的原始資訊
- 獲取文件:從網際網路上,資料庫中,檔案系統中獲取需要搜尋的原始資訊,
1.對於網際網路上的網頁,可以使用工具將網頁抓取到本地生成html檔案
2.資料庫中的資料,可以連線資料庫用select語句查詢
3.檔案系統中的某個檔案用I/O流的方式讀取檔案的內容
- 建立文件物件:獲取原始文件的目的就是為了索引,在索引前需要將原始內容建立成文件(Document),文件中包括一個一個的域,域中儲存內容
我們可以將資料庫中的一條記錄當成一個Document,在這個Document中資料庫中的列叫做Document中的域

注意:每個Document都可以有多個Filed(資料庫中一條記錄有多個欄位),不同的Document可以有不同的Field(資料庫中不同的記錄有不同的欄位),同一個Document可以有相同的Field(資料庫中一條記錄中允許有兩個Id)(域名和域值都相同)
- 分析文件(分詞)
將原始內容建立為包含域(Filed)的文件(Document),需要在對域中的內容進行分析,分析成一個個的單詞
比如:源文件的內容:
Lucene is a Java full-text search engine. Lucene is not a complete
application, but rather a code library and API that can easily be used
to add search capabilities to applications.
分析後得到的詞:
lucene、java、full、search、engine。。。。
- 建立索引
對文件分析(分詞)後得到的詞彙進行索引,索引的目的是為了搜尋,最終要實現只搜尋被索引的詞彙從而找到Document文件
查詢索引流程:
搜尋就是使用者輸入關鍵字,根據關鍵字搜尋索引,根據索引找到對應的文件,從而找到要搜尋的內容
2.Lucene介紹
1.什麼是Lucene
- Lucene是一套用於全文檢索和搜尋的開源程式庫,由Apache軟體基金會支援和提供
- 是一個開放原始碼的全文檢索引擎工具包,以方便在目標系統中實現全文檢索功能
- Lucene只能夠對文字型別的資料建立索引,其他格式的不行,所以你想要把其他格式的檔案進行索引的話需要先把檔案轉換成文字型別之後在建立索引
2.Lucene,全文檢索技術與搜尋引擎的區別:
- 全文檢索技術:一個文件,事先掃描程式會掃描文件中的每一個詞,對每一個詞建立一個索引,指明該詞在文件中出現的位置和次數,當用戶查詢的時候,檢索程式根據事先建立好的索引庫進行查詢,根據索引找到這個詞的檢索方式叫做全文檢索技術.
- 搜尋引擎:搜尋引擎是全文檢索技術最主要的一個應用,搜尋引擎是一個用於提供全文檢索服務的軟體,是一個單獨執行的軟體系統,包括建立索引,處理查詢返回結果,增加索引,優化索引等功能.例如:百度搜索,淘寶商品搜尋等
- Lucene:Lucene是一個用來實現全文檢索技術的類庫,是一套用Java語言寫的全文索引的工具包,為應用程式提供了多個API介面去呼叫,簡單理解是一套能夠實現全文檢索技術的類庫,通過全文檢索技術才能實現一個完整的搜尋引擎.
3.Field域型別
Field是文件中的域,包括Field名和Field值兩部分,一個文件可以包含多個Field,Document只是Field的一個承載體,Field值即為要索引的內容,也是要搜尋的內容
Field屬性:
- 是否分詞
是:做分詞處理,即將Field值進行分詞,分詞的目的是為了索引
比如:商品名稱,商品描述等,這些內容使用者要輸入關鍵字搜尋,但是原文的格式大內容多,需要分詞之後將每一個詞彙進行索引
否:不分詞
比如:商品id,身份證號,訂單號
- 是否索引
是:進行索引,將Field分詞後的詞進行索引,索引的目的是為了搜尋
比如:商品名稱,商品描述 分詞後進行索引,訂單號,身份證號不用分詞但也要索引,這些將來都會作為查詢條件
否:不索引
比如:圖片路徑,檔案路徑,不用作為查詢條件的不用索引
- 是否儲存
是:將Field值儲存在文件域中,儲存在文件域中的Field才能從Document中獲取
比如:商品名稱,訂單號,凡是將來要從Document中獲取的Field都要儲存
否:不儲存Field值
比如:商品描述,內容較大的不用儲存,如果要向用戶戰術商品描述可以從系統的關係資料庫中獲取
Field常用型別:
| Field類 |
資料型別 |
Analyzed 是否分詞 |
Indexed 是否索引 |
Stored 是否儲存 |
說明 |
| StringField(FieldName, FieldValue,Store.YES)) |
字串 |
N |
Y |
Y或N |
這個Field用來構建一個字串Field,但是不會進行分詞,會將整個串儲存在索引中,比如(訂單號,身份證號等) 是否儲存在文件中用Store.YES或Store.NO決定 |
| LongField(FieldName, FieldValue,Store.YES) |
Long型 |
Y |
Y |
Y或N |
這個Field用來構建一個Long數字型Field,進行分詞和索引,比如(價格) 是否儲存在文件中用Store.YES或Store.NO決定 |
| StoredField(FieldName, FieldValue) |
過載方法,支援多種型別 |
N |
N |
Y |
這個Field用來構建不同型別Field 不分析,不索引,但要Field儲存在文件中 |
| TextField(FieldName, FieldValue, Store.NO) 或 TextField(FieldName, reader) |
字串 或 流 |
Y |
Y |
Y或N |
如果是一個Reader, lucene猜測內容比較多,會採用Unstored的策略. |