
全文檢索技術學習(三)——Lucene支援中文分詞
分析器(Analyzer)的執行過程
如下圖是語彙單元的生成過程:

從一個Reader字元流開始,建立一個基於Reader的Tokenizer分詞器,經過三個TokenFilter生成語彙單元Token。
要看分析器的分析效果,只需要看TokenStream中的內容就可以了。每個分析器都有一個方法tokenStream,返回的是一個TokenStream物件。
標準分析器的分詞效果
之前我們建立索引庫的時候,就用到了官方推薦的標準分析器——org.apache.lucene.analysis.standard.StandardAnalyzer。現在我們就來看看其分詞效果,可在LuenceFirst單元測試類中編寫如下方法:
public class LuenceFirst {
// 檢視分析器的分詞效果
@Test
public void testAnanlyzer() throws IOException {
// 1、建立一個分析器物件
Analyzer analyzer = new StandardAnalyzer(); // 官方推薦的標準分析器
// 2、從分析器物件中獲得tokenStream物件
// 引數1:域的名稱,可以為null,或者是""
// 引數2:要分析的文字
TokenStream tokenStream = analyzer.tokenStream("" 執行以上方法,Eclipse控制檯列印:

從上圖中我們可以清楚地看到當前的關鍵詞,以及該關鍵詞的起始位置和結束位置。
中文分析器分析
Lucene自帶中文分詞器
Lucene自帶的中文分詞器有:
- StandardAnalyzer
單字分詞,就是按照中文一個字一個字地進行分詞。如:“我愛中國”,效果:“我”、“愛”、“中”、“國”。 - CJKAnalyzer
二分法分詞,按兩個字進行切分。如:“我是中國人”,效果:“我是”、“是中”、“中國”、“國人”。
上邊這兩個分詞器一看就無法滿足需求。 - SmartChineseAnalyzer
對中文支援較好,但擴充套件性差,擴充套件詞庫,禁用詞庫和同義詞庫等不好處理。
現在我們來看看第三個中文分析器的分析效果,相比前兩個中文分析器,SmartChineseAnalyzer絕對要勝出一籌。為了觀看其分析效果,我們可將LuenceFirst單元測試類中的testAnanlyzer方法改造為:
public class LuenceFirst {
// 檢視分析器的分詞效果
@Test
public void testAnanlyzer() throws IOException {
// 1、建立一個分析器物件
Analyzer analyzer = new SmartChineseAnalyzer(); // 智慧中文分析器
// 2、從分析器物件中獲得tokenStream物件
// 引數1:域的名稱,可以為null,或者是""
// 引數2:要分析的文字
TokenStream tokenStream = analyzer.tokenStream("", "資料庫中儲存的資料是結構化資料,即行資料java,可以用二維表結構來邏輯表達實現的資料。");
// 3、設定一個引用(相當於指標),這個引用可以是多種型別,可以是關鍵詞的引用,偏移量的引用等等
CharTermAttribute charTermAttribute = tokenStream.addAttribute(CharTermAttribute.class); // charTermAttribute物件代表當前的關鍵詞
// 偏移量(其實就是關鍵詞在文件中出現的位置,拿到這個位置有什麼用呢?因為我們將來可能要對該關鍵詞進行高亮顯示,進行高亮顯示要知道這個關鍵詞在哪?)
OffsetAttribute offsetAttribute = tokenStream.addAttribute(OffsetAttribute.class);
// 4、呼叫tokenStream的reset方法,不呼叫該方法,會丟擲一個異常
tokenStream.reset();
// 5、使用while迴圈來遍歷單詞列表
while (tokenStream.incrementToken()) {
System.out.println("start→" + offsetAttribute.startOffset()); // 關鍵詞起始位置
// 6、列印單詞
System.out.println(charTermAttribute);
System.out.println("end→" + offsetAttribute.endOffset()); // 關鍵詞結束位置
}
// 7、關閉tokenStream物件
tokenStream.close();
}
}執行以上方法,Eclipse控制檯列印:

雖然SmartChineseAnalyzer分析器對中文支援較好,但擴充套件性差,擴充套件詞庫,禁用詞庫和同義詞庫等不好處理。故實際開發中我們也是棄用的,取而代之的是第三方中文分析器。
第三方中文分析器
第三方中文分析器有:
- paoding:庖丁解牛最新版在https://code.google.com/p/paoding/ ,其最多隻支援Lucene3.0,且最新提交的程式碼在2008-06-03,在svn中最新也是2010年提交,已經過時,不予考慮。
- IK-analyzer:最新版在https://code.google.com/p/ik-analyzer/上,支援Lucene4.10,從2006年12月推出1.0版開始,IKAnalyzer已經推出了4個大版本。最初,它是以開源專案Luence為應用主體的,結合詞典分詞和文法分析演算法的中文分片語件。從3.0版本開始,IK發展為面向Java的公用分片語件,獨立於Lucene項,同時提供了對Lucene的預設優化實現。在2012版本中,IK實現了簡單的分詞歧義排除演算法,標誌著IK分詞器從單純的詞典分詞向模擬語義分詞衍化。但是也就在2012年12月後沒有再更新了。
- ansj_seg:最新版本在[https://github.com/NLPchina/ansj_seg tags](https://github.com/NLPchina/ansj_seg tags),僅有1.1版本,從2012年到2014年更新了大小6次,但是作者本人在2014年10月10日說明:“可能我以後沒有精力來維護ansj_seg了”,現在由”nlp_china”管理。2014年11月有更新。並未說明是否支援Lucene,是一個由CRF(條件隨機場)演算法所做的分詞演算法。
- imdict-chinese-analyzer:最新版在https://code.google.com/p/imdict-chinese-analyzer/,最新更新也在2009年5月,可下載原始碼,不支援Lucene4.10。它是利用HMM(隱馬爾科夫鏈)演算法。
- Jcseg:最新版本在git.oschina.net/lionsoul/jcseg,支援Lucene 4.10,作者有較高的活躍度。其利用的是mmseg演算法。
但在這裡,我使用的是IK-analyzer,所以下面的講解也是圍繞著該中文分析器來進行的。下面是我下載的IK-analyzer:
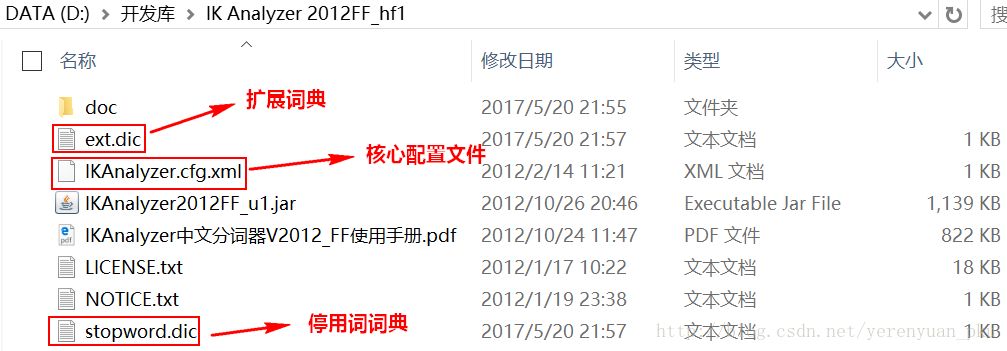
解壓縮之後,其目錄結構是:
IK-analyzer中文分析器的使用
IK-analyzer中文分析器的使用步驟:
- 把IKAnalyzer2012FF_u1.jar包新增到工程中。
- 把配置檔案和擴充套件詞典和停用詞詞典新增到classpath下。
注意:擴充套件詞典和停用詞詞典這兩個檔案的字符集一定要保證是UTF-8字符集,注意是無BOM的UTF-8編碼,嚴禁使用Windows的記事本編輯。
下面我們來看看IK-analyzer這個第三方中文分析器的分析效果。現在隨著網際網路的日趨發展,網路用語層出不窮,例如“高富帥”,“白富美”等等,像這樣的網路用語是不需要進行分詞的,而是當作一個整體的關鍵詞, 這樣像這種不用分詞的網路用語就應該儲存在擴充套件詞典中。為了清楚地觀看IK-analyzer這個第三方中文分析器的分析效果,在擴充套件詞典新增“高富帥”。如下:

接著將LuenceFirst單元測試類中的testAnanlyzer方法改造為:
public class LuenceFirst {
// 檢視分析器的分詞效果
@Test
public void testAnanlyzer() throws IOException {
// 1、建立一個分析器物件
Analyzer analyzer = new IKAnalyzer(); // 智慧中文分析器
// 2、從分析器物件中獲得tokenStream物件
// 引數1:域的名稱,可以為null,或者是""
// 引數2:要分析的文字
TokenStream tokenStream = analyzer.tokenStream("", "資料庫中儲存的資料是結構化資料高富帥,即行資料java,可以用二維表結構來邏輯表達實現的資料。");
// 3、設定一個引用(相當於指標),這個引用可以是多種型別,可以是關鍵詞的引用,偏移量的引用等等
CharTermAttribute charTermAttribute = tokenStream.addAttribute(CharTermAttribute.class); // charTermAttribute物件代表當前的關鍵詞
// 偏移量(其實就是關鍵詞在文件中出現的位置,拿到這個位置有什麼用呢?因為我們將來可能要對該關鍵詞進行高亮顯示,進行高亮顯示要知道這個關鍵詞在哪?)
OffsetAttribute offsetAttribute = tokenStream.addAttribute(OffsetAttribute.class);
// 4、呼叫tokenStream的reset方法,不呼叫該方法,會丟擲一個異常
tokenStream.reset();
// 5、使用while迴圈來遍歷單詞列表
while (tokenStream.incrementToken()) {
System.out.println("start→" + offsetAttribute.startOffset()); // 關鍵詞起始位置
// 6、列印單詞
System.out.println(charTermAttribute);
System.out.println("end→" + offsetAttribute.endOffset()); // 關鍵詞結束位置
}
// 7、關閉tokenStream物件
tokenStream.close();
}
}執行以上方法,Eclipse控制檯列印:

從上圖可清楚地看出“高富帥”並沒有分詞,這正是我們所期望的結果。
除此之外,對於一些敏感的詞,如“習近平”,像這樣的敏感詞彙就不應該出現在單詞列表中,所以可將這種敏感詞彙儲存在停用詞詞典中,如下:

接著將LuenceFirst單元測試類中的testAnanlyzer方法改造為:
public class LuenceFirst {
// 檢視分析器的分詞效果
@Test
public void testAnanlyzer() throws IOException {
// 1、建立一個分析器物件
Analyzer analyzer = new IKAnalyzer(); // 智慧中文分析器
// 2、從分析器物件中獲得tokenStream物件
// 引數1:域的名稱,可以為null,或者是""
// 引數2:要分析的文字
TokenStream tokenStream = analyzer.tokenStream("", "資料庫習近平中儲存的資料是結構化資料高富帥,即行資料java,可以用二維表結構來邏輯表達實現的資料。");
// 3、設定一個引用(相當於指標),這個引用可以是多種型別,可以是關鍵詞的引用,偏移量的引用等等
CharTermAttribute charTermAttribute = tokenStream.addAttribute(CharTermAttribute.class); // charTermAttribute物件代表當前的關鍵詞
// 偏移量(其實就是關鍵詞在文件中出現的位置,拿到這個位置有什麼用呢?因為我們將來可能要對該關鍵詞進行高亮顯示,進行高亮顯示要知道這個關鍵詞在哪?)
OffsetAttribute offsetAttribute = tokenStream.addAttribute(OffsetAttribute.class);
// 4、呼叫tokenStream的reset方法,不呼叫該方法,會丟擲一個異常
tokenStream.reset();
// 5、使用while迴圈來遍歷單詞列表
while (tokenStream.incrementToken()) {
System.out.println("start→" + offsetAttribute.startOffset()); // 關鍵詞起始位置
// 6、列印單詞
System.out.println(charTermAttribute);
System.out.println("end→" + offsetAttribute.endOffset()); // 關鍵詞結束位置
}
// 7、關閉tokenStream物件
tokenStream.close();
}
}執行以上方法,Eclipse控制檯列印:

從上圖可知,像“習近平”這樣的敏感詞彙並沒有出現在單詞列表中。
分析器的應用場景
索引時使用Analyzer
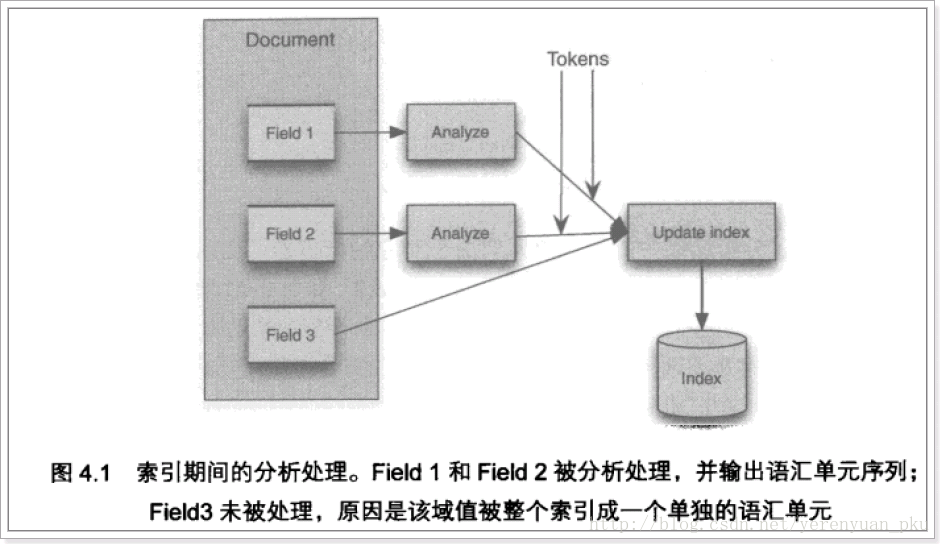
輸入關鍵字進行搜尋,當需要讓該關鍵字與文件域內容所包含的詞進行匹配時需要對文件域內容進行分析,需要經過Analyzer分析器處理生成語彙單元(Token)。分析器分析的物件是文件中的Field域。當Field的屬性tokenized(是否分詞)為true時會對Field值進行分析,如下圖:
對於一些Field可以不用分析:
- 不作為查詢條件的內容,比如檔案路徑
- 不是匹配內容中的詞而匹配Field的整體內容,比如訂單號、身份證號等
搜尋時使用Analyzer
對搜尋關鍵字進行分析和索引分析一樣,使用Analyzer對搜尋關鍵字進行分析、分詞處理,使用分析後的每個詞語進行搜尋。比如:搜尋關鍵字:spring web,經過分析器進行分詞,得出:spring web,拿詞去索引詞典表查詢 ,找到索引連結到Document,解析Document內容。
對於匹配整體Field域的查詢可以在搜尋時不分析,比如根據訂單號、身份證號查詢等。
注意:搜尋使用的分析器要和索引使用的分析器最好保持一致。