
爬蟲之字型反爬(一)起點網
阿新 • • 發佈:2018-12-06
今天為大家帶來的是爬蟲之反爬措施中字型反爬的一個案例,起點網。具體來看下面的分析與程式碼。
首先參考的網站:https://www.qidian.com/all?&page=1
從網站中可以觀察到,它的反爬是這樣的:
再從網頁原始碼中觀察,發現又是這樣的:
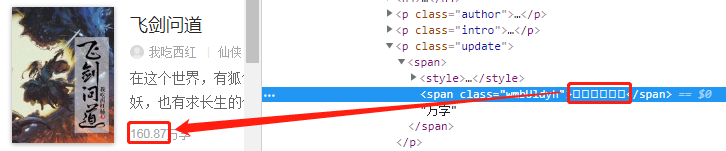
在觀察網頁後發現重複出現了一個較為特殊的標籤 <style>,點開之後如下圖所示:
發現原來這就是傳說中的字型反爬!!ttf結尾的就是相應的字型檔案。


好了,那麼接下來就是觀察字型檔案,檢視具體的數字是怎樣的對應關係。
檢視字型檔案可下載fontcreater(自行百度。。),字型檔案中顯示如下:
哇。。so easy,這不就是英文字母對應其數字嗎,所以先自定義一個字典(單詞與數字的對應關係),用來對映該網站的其他字型庫。
接下來,通過python庫fonttools工具包,找出字型檔案中包含的對映關係,程式碼如下:
from fontTools.ttLib import TTFont from io import BytesIO url_ziti = '字型檔案地址'. ziti = requests.get(url_ziti) # 下載ttf字型檔案,然後通過BytesIO轉化為記憶體檔案,使用TTFont處理 font = TTFont(BytesIO(ziti.content)) cmap = font.getBestCmap() cmap對映關係如下圖所示:
可以發現,上圖中字典的鍵值與網頁原始碼中的值是一致的,於是就可以通過相互對映的關係,找出這些原始碼最終代表的是那幾個數字,我把兩張圖放在一起,方便大家理解:
可以看到100156對應數字1,100158對應數字6,依此類推,最後得到的數字是160.87,發現與網頁中顯示的一致。





這個案例到這就結束啦,總結一下:這裡的反爬呢就是相互之間的對映關係,關鍵點在於尋找發現這種關係,主要通過兩個工具,fontcreater和fonttools包,其次只需要映射出網頁原始碼與真實數字即可。