
跟繁瑣的命令列說拜拜!Gerapy分散式爬蟲管理框架來襲!
背景
用 Python 做過爬蟲的小夥伴可能接觸過 Scrapy,GitHub:https://github.com/scrapy/scrapy。Scrapy 的確是一個非常強大的爬蟲框架,爬取效率高,擴充套件性好,基本上是使用 Python 開發爬蟲的必備利器。如果使用 Scrapy 做爬蟲,那麼在爬取時,我們當然完全可以使用自己的主機來完成爬取,但當爬取量非常大的時候,我們肯定不能在自己的機器上來執行爬蟲了,一個好的方法就是將 Scrapy 部署到遠端伺服器上來執行。
所以,這時候就出現了另一個庫 Scrapyd,GitHub:https://github.com/scrapy/scrapyd,有了它我們只需要在遠端伺服器上安裝一個 Scrapyd,啟動這個服務,就可以將我們寫的 Scrapy 專案部署到遠端主機上了,Scrapyd 還提供了各種操作 API,可以自由地控制 Scrapy 專案的執行,API 文件:http://scrapyd.readthedocs.io/en/stable/api.html,例如我們將 Scrapyd 安裝在 IP 為 88.88.88.88 的伺服器上,然後將 Scrapy 專案部署上去,這時候我們通過請求 API 就可以來控制 Scrapy 專案的運行了,命令如下:
curl http://88.88.88.88:6800/schedule.json -d project=myproject -d spider=somespider
這樣就相當於啟動了 myproject 專案的 somespider 爬蟲,而不用我們再用命令列方式去啟動爬蟲,同時 Scrapyd 還提供了檢視爬蟲狀態、取消爬蟲任務、新增爬蟲版本、刪除爬蟲版本等等的一系列 API,所以說,有了 Scrapyd,我們可以通過 API 來控制爬蟲的執行,擺脫了命令列的依賴。
另外爬蟲部署還是個麻煩事,因為我們需要將爬蟲程式碼上傳到遠端伺服器上,這個過程涉及到打包和上傳兩個過程,在 Scrapyd 中其實提供了這個部署的 API,叫做 addversion,但是它接受的內容是 egg 包檔案,所以說要用這個介面,我們必須要把我們的 Scrapy 專案打包成 egg 檔案,然後再利用檔案上傳的方式請求這個 addversion 接口才可以完成上傳,這個過程又比較繁瑣了,所以又出現了一個工具叫做 Scrapyd-Client,GitHub:https://github.com/scrapy/scrapyd-client,利用它的 scrapyd-deploy 命令我們便可以完成打包和上傳的兩個功能,可謂是又方便了一步。
這樣我們就已經解決了部署的問題,回過頭來,如果我們要想實時檢視伺服器上 Scrapy 的執行狀態,那該怎麼辦呢?像剛才說的,當然是請求 Scrapyd 的 API 了,如果我們想用 Python 程式來控制一下呢?我們還要用 requests 庫一次次地請求這些 API ?這就太麻煩了吧,所以為了解決這個需求,Scrapyd-API 又出現了,GitHub:https://github.com/djm/python-scrapyd-api,有了它我們可以只用簡單的 Python 程式碼就可以實現 Scrapy 專案的監控和執行:
from scrapyd_api import ScrapydAPI
scrapyd = ScrapydAPI('http://88.888.88.88:6800')
scrapyd.list_jobs('project_name')
這樣它的返回結果就是各個 Scrapy 專案的執行情況。
例如:
{
'pending': [
],
'running': [
{
'id': u'14a65...b27ce',
'spider': u'spider_name',
'start_time': u'2018-01-17 22:45:31.975358'
},
],
'finished': [
{
'id': '34c23...b21ba',
'spider': 'spider_name',
'start_time': '2018-01-11 22:45:31.975358',
'end_time': '2018-01-17 14:01:18.209680'
}
]
}
這樣我們就可以看到 Scrapy 爬蟲的執行狀態了。
所以,有了它們,我們可以完成的是:
-
通過 Scrapyd 完成 Scrapy 專案的部署
-
通過 Scrapyd 提供的 API 來控制 Scrapy 專案的啟動及狀態監控
-
通過 Scrapyd-Client 來簡化 Scrapy 專案的部署
-
通過 Scrapyd-API 來通過 Python 控制 Scrapy 專案
是不是方便多了?
可是?真的達到最方便了嗎?肯定沒有!如果這一切的一切,從 Scrapy 的部署、啟動到監控、日誌檢視,我們只需要滑鼠鍵盤點幾下就可以完成,那豈不是美滋滋?更或者說,連 Scrapy 程式碼都可以幫你自動生成,那豈不是爽爆了?
有需求就有動力,沒錯,Gerapy 就是為此而生的,GitHub:https://github.com/Gerapy/Gerapy。
本節我們就來簡單瞭解一下 Gerapy 分散式爬蟲管理框架的使用方法。
安裝
Gerapy 是一款分散式爬蟲管理框架,支援 Python 3,基於 Scrapy、Scrapyd、Scrapyd-Client、Scrapy-Redis、Scrapyd-API、Scrapy-Splash、Jinjia2、Django、Vue.js 開發,Gerapy 可以幫助我們:
-
更方便地控制爬蟲執行
-
更直觀地檢視爬蟲狀態
-
更實時地檢視爬取結果
-
更簡單地實現專案部署
-
更統一地實現主機管理
-
更輕鬆地編寫爬蟲程式碼
安裝非常簡單,只需要執行 pip3 命令即可:
pip3 install gerapy
安裝完成之後我們就可以使用 gerapy 命令了,輸入 gerapy 便可以獲取它的基本使用方法:
gerapy
Usage:
gerapy init [--folder=<folder>]
gerapy migrate
gerapy createsuperuser
gerapy runserver [<host:port>]
gerapy makemigrations
如果出現上述結果,就證明 Gerapy 安裝成功了。
初始化
接下來我們來開始使用 Gerapy,首先利用如下命令進行一下初始化,在任意路徑下均可執行如下命令:
gerapy init
執行完畢之後,本地便會生成一個名字為 gerapy 的資料夾,接著進入該資料夾,可以看到有一個 projects 資料夾,我們後面會用到。
緊接著執行資料庫初始化命令:
cd gerapy
gerapy migrate
這樣它就會在 gerapy 目錄下生成一個 SQLite 資料庫,同時建立資料庫表。
接著我們只需要再執行命令啟動服務就好了:
gerapy runserver
這樣我們就可以看到 Gerapy 已經在 8000 埠上運行了。
全部的操作流程截圖如下:
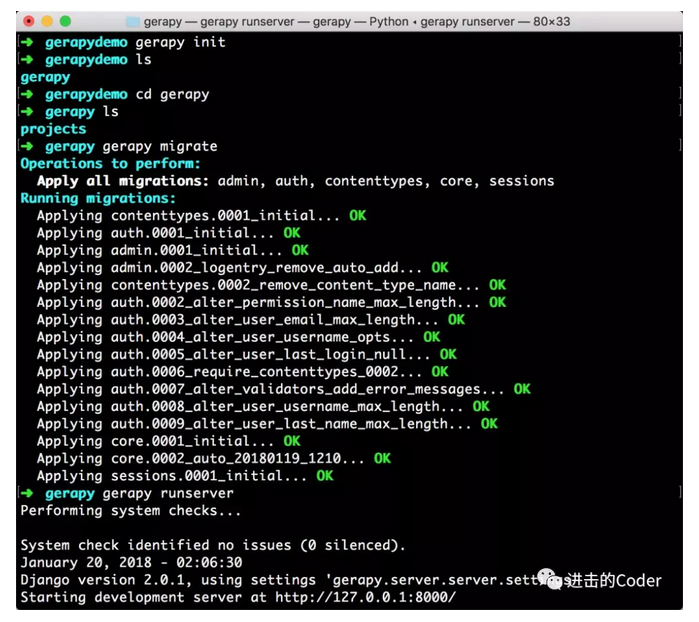
接下來我們在瀏覽器中開啟 http://localhost:8000/,就可以看到 Gerapy 的主介面了:
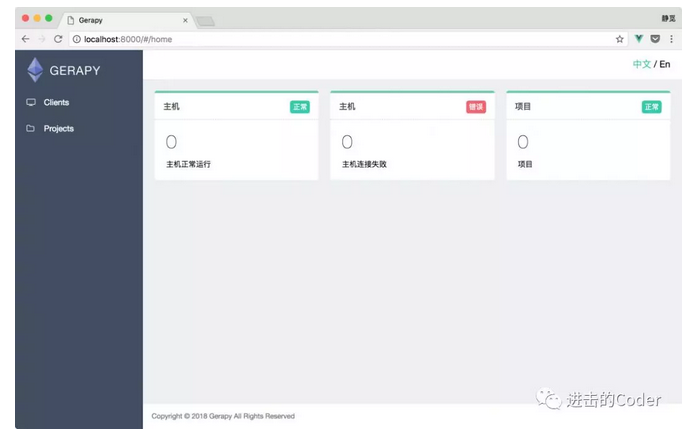
這裡顯示了主機、專案的狀態,當然由於我們沒有新增主機,所以所有的數目都是 0。
如果我們可以正常訪問這個頁面,那就證明 Gerapy 初始化都成功了。
主機管理
接下來我們可以點選左側 Clients 選項卡,即主機管理頁面,新增我們的 Scrapyd 遠端服務,點選右上角的建立按鈕即可新增我們需要管理的 Scrapyd 服務:
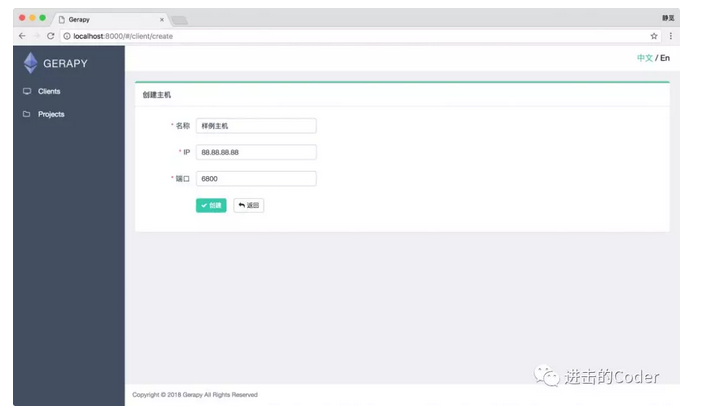
需要新增 IP、埠,以及名稱,點選建立即可完成新增,點選返回即可看到當前新增的 Scrapyd 服務列表,樣例如下所示:

這樣我們可以在狀態一欄看到各個 Scrapyd 服務是否可用,同時可以一目瞭然當前所有 Scrapyd 服務列表,另外我們還可以自由地進行編輯和刪除。
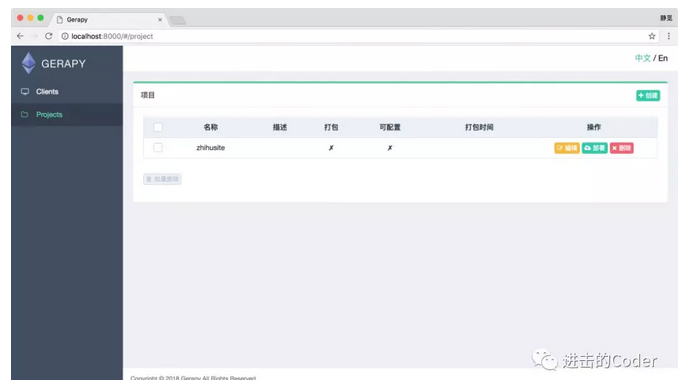
專案管理
Gerapy 的核心功能當然是專案管理,在這裡我們可以自由地配置、編輯、部署我們的 Scrapy 專案,點選左側的 Projects ,即專案管理選項,我們可以看到如下空白的頁面:
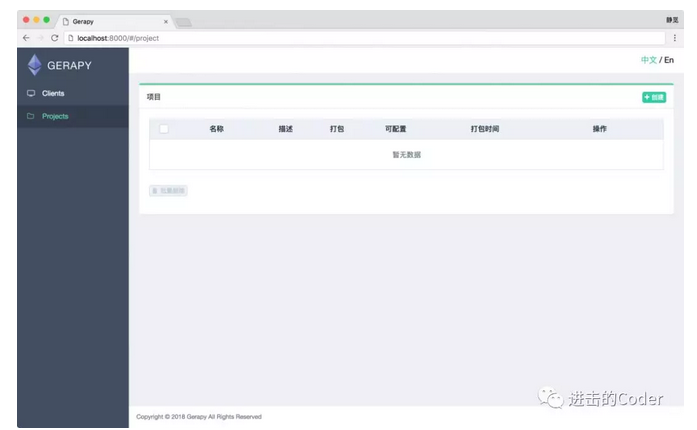
假設現在我們有一個 Scrapy 專案,如果我們想要進行管理和部署,還記得初始化過程中提到的 projects 資料夾嗎?這時我們只需要將專案拖動到剛才 gerapy 執行目錄的 projects 資料夾下,例如我這裡寫好了一個 Scrapy 專案,名字叫做 zhihusite,這時把它拖動到 projects 資料夾下:
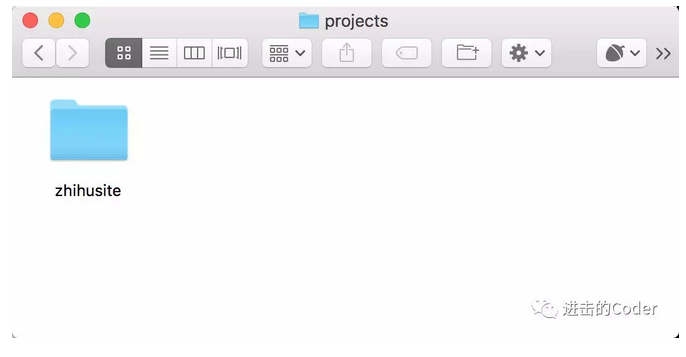
這時重新整理頁面,我們便可以看到 Gerapy 檢測到了這個專案,同時它是不可配置、沒有打包的:
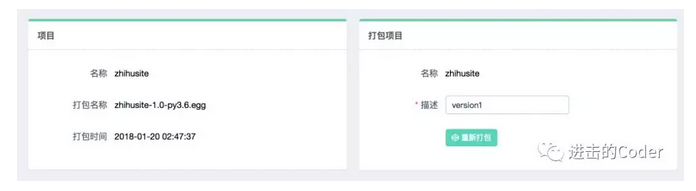
這時我們可以點選部署按鈕進行打包和部署,在右下角我們可以輸入打包時的描述資訊,類似於 Git 的 commit 資訊,然後點選打包按鈕,即可發現 Gerapy 會提示打包成功,同時在左側顯示打包的結果和打包名稱:
打包成功之後,我們便可以進行部署了,我們可以選擇需要部署的主機,點選後方的部署按鈕進行部署,同時也可以批量選擇主機進行部署,示例如下:
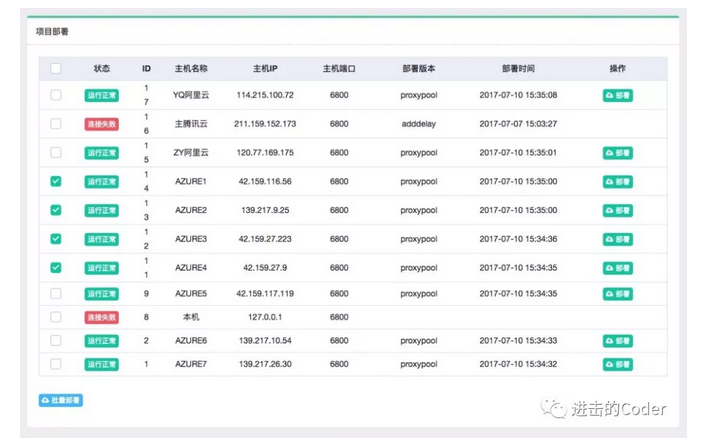
可以發現此方法相比 Scrapyd-Client 的命令列式部署,簡直不能方便更多。
監控任務
部署完畢之後就可以回到主機管理頁面進行任務排程了,任選一臺主機,點選排程按鈕即可進入任務管理頁面,此頁面可以檢視當前 Scrapyd 服務的所有專案、所有爬蟲及執行狀態:

我們可以通過點選新任務、停止等按鈕來實現任務的啟動和停止等操作,同時也可以通過展開任務條目檢視日誌詳情:

另外我們還可以隨時點選停止按鈕來取消 Scrapy 任務的執行。
這樣我們就可以在此頁面方便地管理每個 Scrapyd 服務上的 每個 Scrapy 專案的運行了。
專案編輯
同時 Gerapy 還支援專案編輯功能,有了它我們不再需要 IDE 即可完成專案的編寫,我們點選專案的編輯按鈕即可進入到編輯頁面,如圖所示:

這樣即使 Gerapy 部署在遠端的伺服器上,我們不方便用 IDE 開啟,也不喜歡用 Vim 等編輯軟體,我們可以藉助於本功能方便地完成程式碼的編寫。
程式碼生成
上述的專案主要針對的是我們已經寫好的 Scrapy 專案,我們可以藉助於 Gerapy 方便地完成編輯、部署、控制、監測等功能,而且這些專案的一些邏輯、配置都是已經寫死在程式碼裡面的,如果要修改的話,需要直接修改程式碼,即這些專案都是不可配置的。
在 Scrapy 中,其實提供了一個可配置化的爬蟲 CrawlSpider,它可以利用一些規則來完成爬取規則和解析規則的配置,這樣可配置化程度就非常高,這樣我們只需要維護爬取規則、提取邏輯就可以了。如果要新增一個爬蟲,我們只需要寫好對應的規則即可,這類爬蟲就叫做可配置化爬蟲。
Gerapy 可以做到:我們寫好爬蟲規則,它幫我們自動生成 Scrapy 專案程式碼。
我們可以點選專案頁面的右上角的建立按鈕,增加一個可配置化爬蟲,接著我們便可以在此處新增提取實體、爬取規則、抽取規則了,例如這裡的解析器,我們可以配置解析成為哪個實體,每個欄位使用怎樣的解析方式,如 XPath 或 CSS 解析器、直接獲取屬性、直接新增值等多重方式,另外還可以指定處理器進行資料清洗,或直接指定正則表示式進行解析等等,通過這些流程我們可以做到任何欄位的解析。
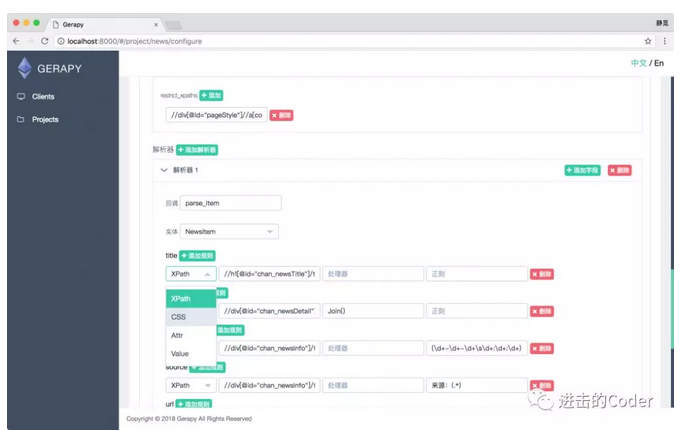
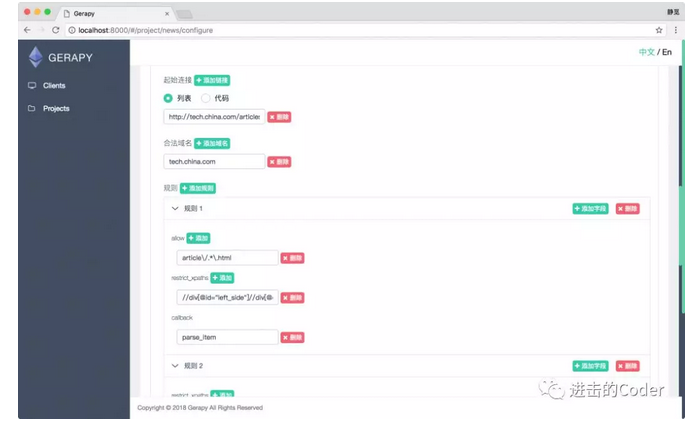
再比如爬取規則,我們可以指定從哪個連結開始爬取,允許爬取的域名是什麼,該連結提取哪些跟進的連結,用什麼解析方法來處理等等配置。通過這些配置,我們可以完成爬取規則的設定。
最後點選生成按鈕即可完成程式碼的生成。
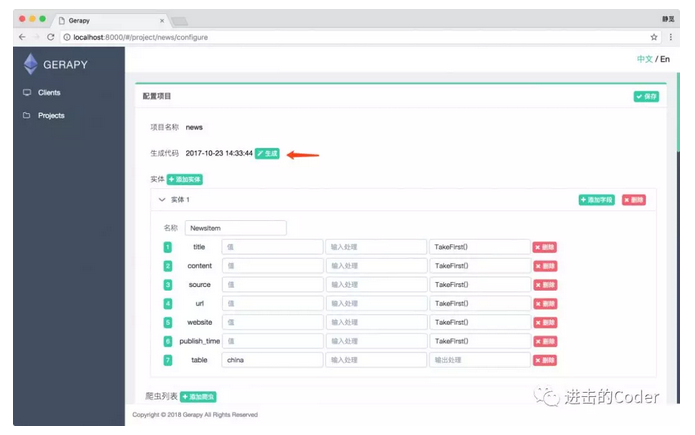
生成的程式碼示例結果如圖所示,可見其結構和 Scrapy 程式碼是完全一致的。
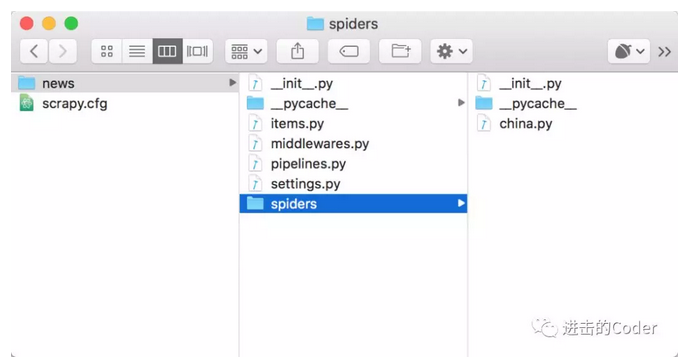
生成程式碼之後,我們只需要像上述流程一樣,把專案進行部署、啟動就好了,不需要我們寫任何一行程式碼,即可完成爬蟲的編寫、部署、控制、監測。
結語
以上便是 Gerapy 分散式爬蟲管理框架的基本用法,如需瞭解更多,可以訪問其 GitHub:https://github.com/Gerapy/Gerapy。
如果覺得此框架有不足的地方,歡迎提 Issue,也歡迎發 Pull Request 來貢獻程式碼,如果覺得 Gerapy 有所幫助,還望賜予一個 Star!非常感謝!