
Scrapy專案部署到Gerapy分散式爬蟲框架流程
1 準備工作
(1)安裝Gerapy
通過pip install gerapy即可
(2)安裝Scrapyd
通過pip install scrapyd即可
(3)寫好的Scrapy專案,如:
2 開始部署
(1)在電腦任意位置新建一個資料夾,如:
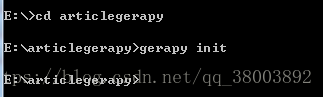
(2)開啟cmd,進入到這個資料夾下,輸入命令gerapy init
這時他會給我生成一個資料夾
在這個資料夾下還有一個資料夾

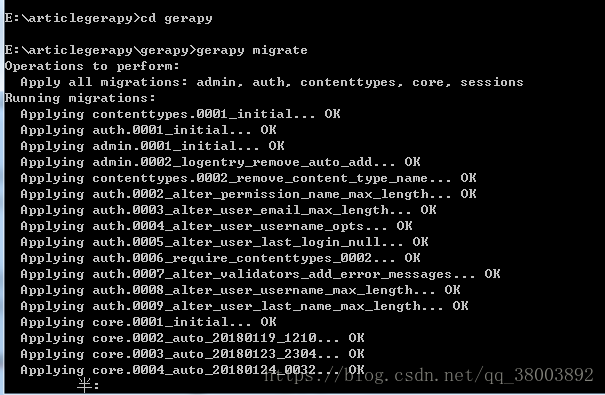
(3)進入到gerapy資料夾下,在輸入gerapy migrate完成gerapy初始化工作
(4)將scrapy專案放到projects目錄下
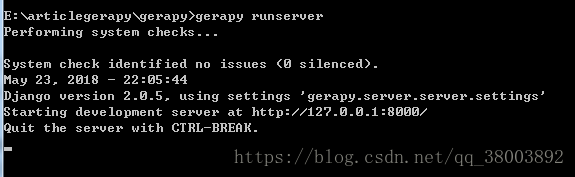
(5)利用gerapy runserver,啟動gerapy
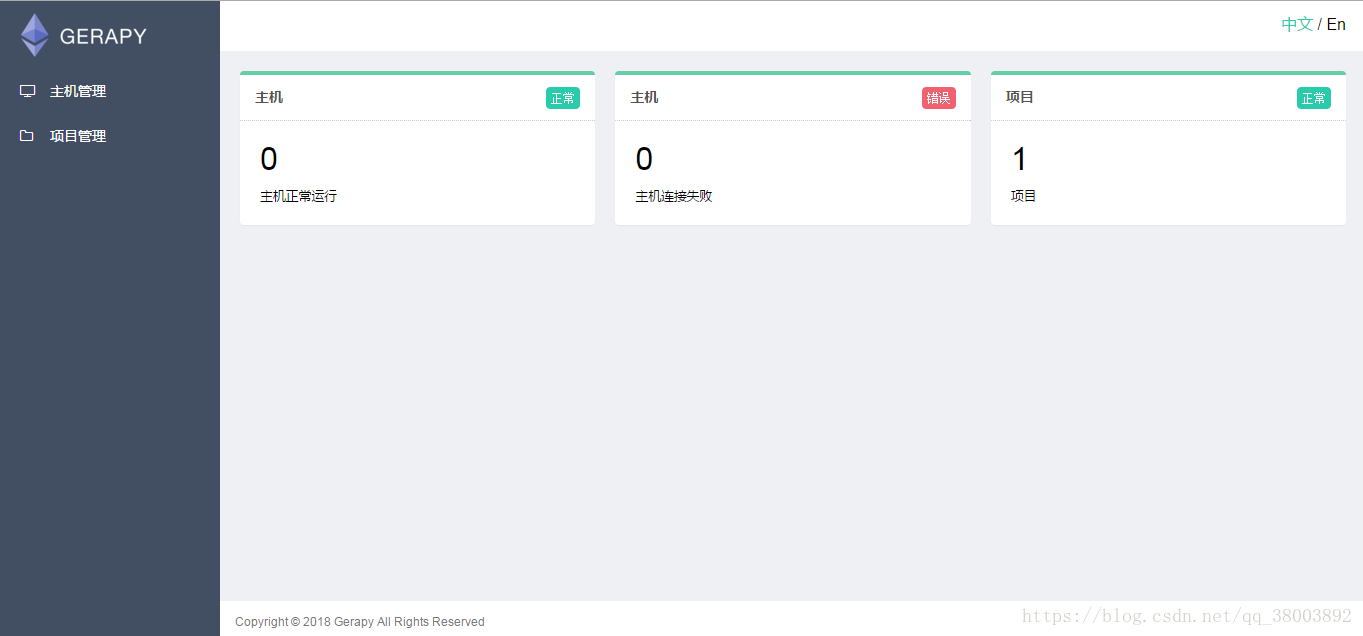
(6)開啟瀏覽器輸入127.0.0.1:8000
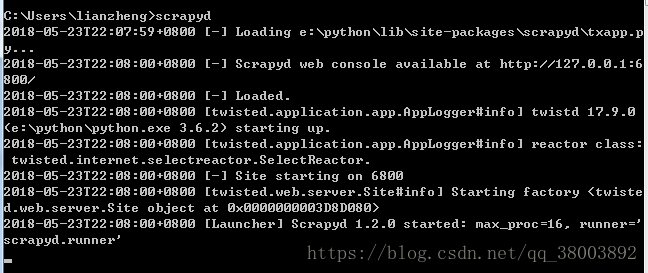
(7)另開啟一個新的cmd,輸入scrapyd,開啟scrapyd
(8)在gerapy中載入scrapyd伺服器

(9)填寫資訊
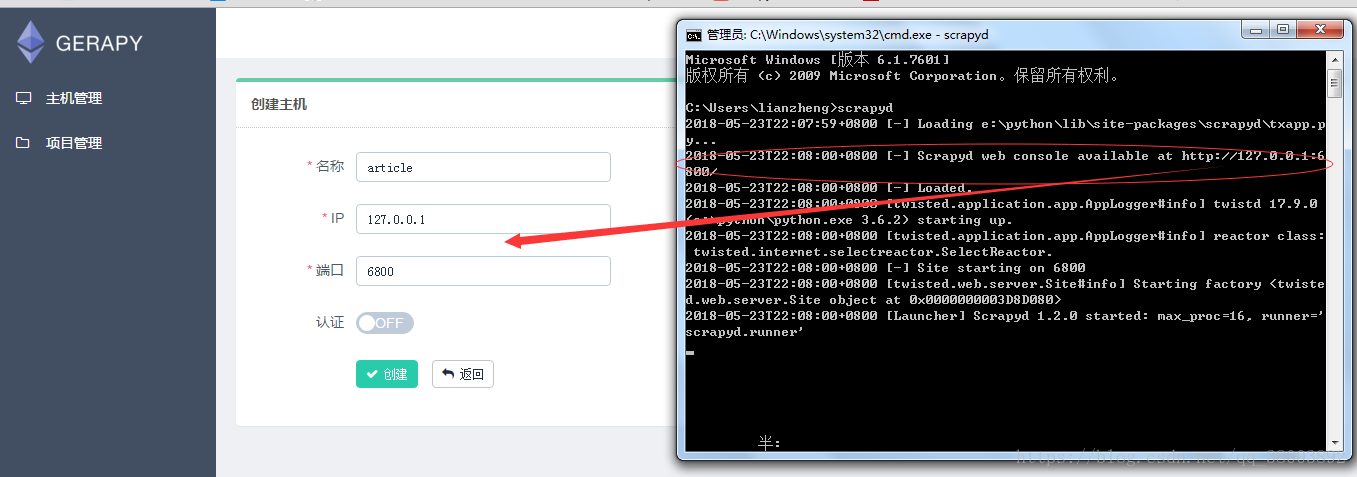
(10)打包部署專案
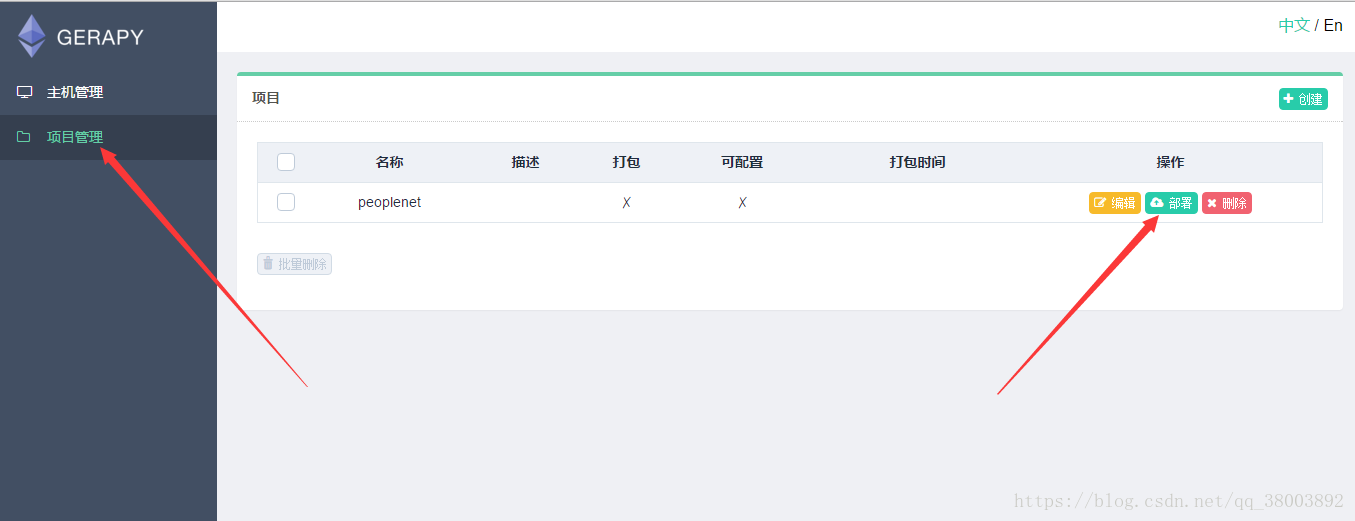
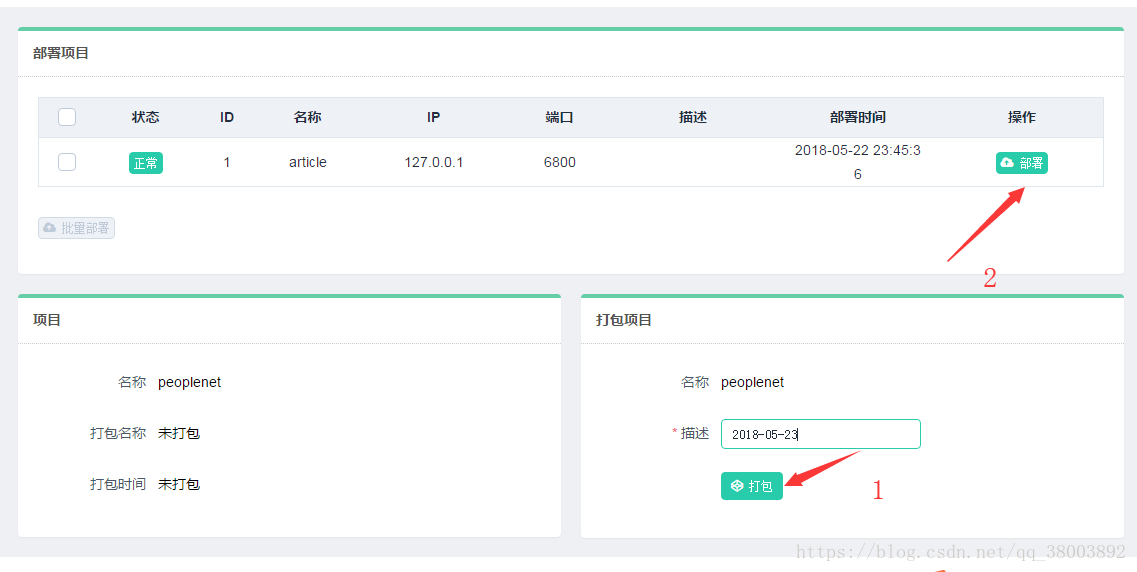
相關推薦
Scrapy專案部署到Gerapy分散式爬蟲框架流程
1 準備工作 (1)安裝Gerapy 通過pip install gerapy即可 (2)安裝Scrapyd 通過pip install scrapyd即可 (3)寫好的Scrapy專案,如: 2 開始部署 (1)在電腦任意位置新建一個資料夾,如: (2)開
scrapy入門教程()Gerapy分散式爬蟲管理框架
一、介紹: Gerapy 是一款分散式爬蟲管理框架,支援 Python 3,基於 Scrapy、Scrapyd、Scrapyd-Client、Scrapy-Redis、Scrapyd-API、Scrapy-Splash、Jinjia2、Django、Vue.js
功能比Scrapy強,卻使用最方便的Gerapy分散式爬蟲管理框架
向AI轉型的程式設計師都關注了這個號???大資料探勘DT資料分析 公眾號: datadw從
跟繁瑣的命令列說拜拜!Gerapy分散式爬蟲管理框架來襲!
背景 用 Python 做過爬蟲的小夥伴可能接觸過 Scrapy,GitHub:https://github.com/scrapy/scrapy。Scrapy 的確是一個非常強大的爬蟲框架,爬取效率高,擴充套件性好,基本上是使用 Python 開發爬蟲的必備利器。如果使用 Scrapy 做爬蟲,那麼在爬取時
初識Gerapy分散式爬蟲管理框架
一、介紹: Gerapy 是一款分散式爬蟲管理框架,支援 Python 3,基於 Scrapy、Scrapyd、Scrapyd-Client、Scrapy-Redis、Scrapyd-API、Scrapy-Splash、Jinjia2、Django、Vue.js
【個人專案】基於scrapy-redis的股票分散式爬蟲實現及其股票預測演算法研究
前言 都說做計算機的,專案實踐是最能帶給人成長的。之前學習了很多的大資料和AI的知識,但是從來沒有自己做過一個既包含大資料又包含AI的專案。後來就決定做了個大資料+AI的分散式爬蟲系統。下面筆者會講述整個專案的架構,以及所用到技術點的些許介紹。 專案介紹 這個專
Scrapy基於scrapy_redis實現分散式爬蟲部署
準備工作1.安裝scrapy_redis包,開啟cmd工具,執行命令pip install scrapy_redis2.準備好一個沒有BUG,沒有報錯的爬蟲專案3.準備好redis主伺服器還有跟程式相關的mysql資料庫前提mysql資料庫要開啟允許遠端連線,因為mysql安
Gerapy分散式爬蟲管理框架
介紹: Gerapy 是一款分散式爬蟲管理框架,支援 Python 3,基於 Scrapy、Scrapyd、Scrapyd-Client、Scrapy-Redis、Scrapyd-API、Scrapy-Splash、Jinjia2、Django、Vue.js 開發。 g
akka分散式爬蟲框架(一)——設計思路與demo
最近在學習akka,在讀了一下解析actor model的文章以及熟悉了一下官方文件的例子的後 我覺得需要一個專案來幫我進一步熟悉akka與scala程式設計,進過一番思索,我覺得akka可以用來 實現一個分散式爬蟲框架。 設計思路 1. 依賴的庫, http
python下使用scrapy-redis模組分散式爬蟲的爬蟲專案部署詳細教程————————gerapy
1.使用gerapy進行分散式爬蟲管理 準備工作: 首先將你使用scrapy-redis寫的分散式爬蟲全部完善 模組準備: 安裝: pip install pymongo【依賴模組】 pip install gerapy 2.在本地建立部署專案的資料夾
Gerapy 部署分散式爬蟲專案詳解
Gerapy簡介 根據說明,Gerapy 應當是一款國人開發的是一款分散式爬蟲管理框架(有中文介面) 。支援 Python 3,基於 Scrapy、Scrapyd、Scrapyd-Client、Scrapy-Redis、Scrapyd-API、Scrapy-Sp
python分散式爬蟲scrapyd部署以及gerapy的使用流程
新建虛擬環境(方便管理),也可以直接執行第一步。注意:windows系統和虛擬環境要分清,進入指定的環境下進行操作,否則會出現錯誤 1、開啟命令列工具執行pip install scrapyd 2、 等待安裝完成 , 輸入scrapyd啟動s
Gerapy部署scrapy爬蟲框架
Gerapy 是一款分散式爬蟲管理框架,支援 Python 3,基於 Scrapy、Scrapyd、Scrapyd-Client、Scrapy-Redis、Scrapyd-API、Scrapy-Splash、Jinjia2、Django、Vue.js 開發。 gera
如何通過Scrapy簡單高效地部署和監控分散式爬蟲專案!這才是大牛
動圖展示 叢集多節點部署和執行爬蟲專案: 進群:960410445 即可獲取數十套PDF! 安裝和配置 私信菜鳥 菜鳥帶你玩爬蟲!007即可. 訪問 Web UI 通過
gerapy框架爬蟲專案部署
開啟cmd終端視窗 輸入命令下載gerpay 框架 (pip install genapy)等待下載完成。 在非c盤下建立一個資料夾,進入這個資料夾(這個資料夾是存放部署的專案)。 使用cmd命令,進入自己在非c盤下建立的資料夾,在cmd下輸入命令(gerapy init)初始化。 這個時候可以看到自己建立
Python 和 Scrapy 爬蟲框架部署
python scrapy 爬蟲框架 Scrapy 是采用Python 開發的一個快速可擴展的抓取WEB 站點內容的爬蟲框架。安裝依賴 yum install gcc gcc-c++ openssl mysql mysql-server libffi* libxml* libxml2 l
Scrapy+Scrapy-redis+Scrapyd+Gerapy 分布式爬蟲框架整合
sta 端口 pro ron 配置文件 詳情 pre 流程 .py 簡介:給正在學習的小夥伴們分享一下自己的感悟,如有理解不正確的地方,望指出,感謝~ 首先介紹一下這個標題吧~ 1. Scrapy:是一個基於Twisted的異步IO框架,有了這個框架,我們就不需要等待當前U
如何通過 Scrapyd + ScrapydWeb 簡單高效地部署和監控分散式爬蟲專案
需求分析 初級使用者: 只有一臺開發主機 能夠通過 Scrapyd-client 打包和部署 Scrapy 爬蟲專案,以及通過 Scrapyd JSON API 來控制爬蟲,感覺命令列操作太麻煩,希望能夠通過瀏覽器直接部署和執行專案 專業使用者:
如何簡單高效地部署和監控分散式爬蟲專案
需求分析 初級使用者: 只有一臺開發主機 能夠通過 Scrapyd-client 打包和部署 Scrapy 爬蟲專案,以及通過 Scrapyd JSON API 來控制爬蟲,感覺命令列操作太麻煩,希望能夠通過瀏覽器直接部署和執行專案 專業使用者: 有 N 臺雲主
Scrapy爬蟲框架 使用流程、框架、儲存模式介紹
Scrapy特色 建議 使用 xpath 進行解析 (因為Scrapy集成了xpath介面) 高效能爬蟲、多執行緒、資料解析、持久化儲存 自動攜帶cookie無需單獨操作 安裝 mac下 pip install scrapy 使用流程 終