分散式協調服務-zookeeper初識與安裝
1、為什麼要使用zookeeper
zookeeper一般使用在分散式系統中,分散式存在的特點主要有:分佈性、併發性和無序性。程式執行過程中,併發性操作是很常見的。比如同一個分散式系統中的多個節點,同時訪問一個共享資源。資料庫、分散式儲存。程序之間的訊息通訊,會出現順序不一致問題。
分散式架構存在的問題:
1、網路通訊:網路本身的不可靠性,因此會涉及到一些網路通訊問題
2、網路分割槽:當網路發生異常導致分散式系統中部分節點之間的網路延時不斷增大,最終導致組成分散式架構的所有節點,只有部分節點能夠正常通訊
3、三態:在分散式架構裡面,介面呼叫成功、失敗,以及常見的超時
4、分散式事務
2、中心化與去中心化
中心化:冷備或者熱備
去中心化:分散式架構裡面,很多的架構思想採用的是:當叢集發生故障的時候,叢集中的人群會自動“選舉”出一個新的領導。最典型的是: zookeeper / etcd
3、經典的CAP/BASE理論
C、(一致性 Consistency): 所有節點上的資料,時刻保持一致
A、可用性(Availability):每個請求都能夠收到一個響應,無論響應成功或者失敗
P、分割槽容錯 (Partition-tolerance):表示系統出現腦裂以後,可能導致某些server與叢集中的其他機器失去聯絡
CP / AP
CAP理論僅適用於原子讀寫的Nosql場景,不適用於資料庫系統
BASE
基於CAP理論,CAP理論並不適用於資料庫事務(因為更新一些錯誤的資料而導致資料出現紊亂,無論什麼樣的資料庫高可用方案都是
徒勞) ,雖然XA事務可以保證資料庫在分散式系統下的ACID特性,但是會帶來效能方面的影響;
eBay嘗試了一種完全不同的套路,放寬了對事務ACID的要求。提出了BASE理論
Basically available : 資料庫採用分片模式, 把100W的使用者資料分佈在5個例項上。如果破壞了其中一個例項,仍然可以保證
80%的使用者可用
soft-state: 在基於client-server模式的系統中,server端是否有狀態,決定了系統是否具備良好的水平擴充套件、負載均衡、故障恢復等特性。
Server端承諾會維護client端狀態資料,這個狀態僅僅維持一小段時間, 這段時間以後,server端就會丟棄這個狀態,恢復正常狀態
Eventually consistent:資料的最終一致性
4、初步認識zookeeper
1、zookeeper是什麼
分散式資料一致性的解決方案
2、zookeeper能做什麼
資料的釋出/訂閱(配置中心:disconf) 、 負載均衡(dubbo利用了zookeeper機制實現負載均衡) 、命名服務、
master選舉(kafka、hadoop、hbase)、分散式佇列、分散式鎖
3、zookeeper的特性
順序一致性:從同一個客戶端發起的事務請求,最終會嚴格按照順序被應用到zookeeper中
原子性
所有的事務請求的處理結果在整個叢集中的所有機器上的應用情況是一致的,也就是說,要麼整個叢集中的所有機器都成功應用了某一事務、要麼全都不應用
可靠性
一旦伺服器成功應用了某一個事務資料,並且對客戶端做了響應,那麼這個資料在整個叢集中一定是同步並且保留下來的
實時性
一旦一個事務被成功應用,客戶端就能夠立即從伺服器端讀取到事務變更後的最新資料狀態;(zookeeper僅僅保證在一定時間內,近實時)
5、Zookeeper的安裝
單機環境安裝
1.下載zookeeper的安裝包
http://apache.fayea.com/zookeeper/stable/zookeeper-3.4.10.tar.gz
2.解壓zookeeper
tar -zxvf zookeeper-3.4.10.tar.gz,解壓後目錄資訊如下

3.cd 到 ZK_HOME/conf , copy一份zoo.cfg,
cp zoo_sample.cfg zoo.cfg
4.到bin目錄下檢視zkServer.sh指令碼,該指令碼可以攜帶這些引數:sh zkServer.sh {start|start-foreground|stop|restart|status|upgrade|print-cmd}
5.使用sh zkServer.sh start啟動zk。zk啟動的預設埠是2181


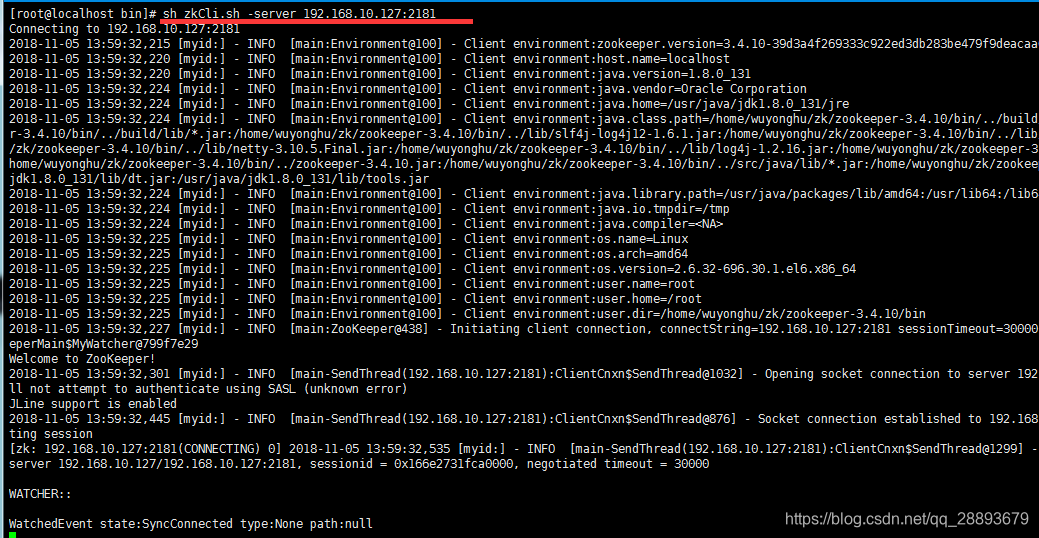
6.如果需要從客戶端連線zk,可以使用如下命令:sh zkCli.sh -server ip:port
叢集環境
說明:
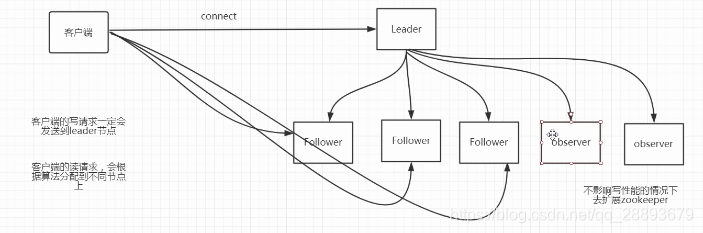
1、zookeeper叢集, 包含三種角色: leader / follower /observer
2、leader/follower:leader即領導、follower為跟隨者。
3、observer:observer 是一種特殊的zookeeper節點。可以幫助解決zookeeper的擴充套件性(如果大量客戶端訪問我們zookeeper叢集,需要增加zookeeper叢集機器數量。從而增加zookeeper叢集的效能。 導致zookeeper寫效能下降, zookeeper的資料變更需要半數以上伺服器投票通過。造成網路消耗增加投票成本) observer不參與投票。 只接收投票結果 .不屬於zookeeper的關鍵部位。
環境準備:
三臺虛擬機器,分別是192.168.10.125、192.168.10.127和192.168.10.128

安裝部署步驟:
1、在每臺伺服器上單機安裝zookeeper,不啟動。
2、在每臺伺服器的config/zoo.cfg檔案中新增如下配置:
serveri.id=ip:port1:port2
id表示每個服務在叢集裡面的唯一表示,取值範圍為1-255
port1:zk的埠號,節點之間通訊的埠號,不能是2181,因為客戶端會使用該介面
port2:表示leader選舉的埠號

3、建立myid:每個節點的唯一標識。
在每個節點伺服器的dataDir目錄下建立一個myid的檔案,檔案內容裡面為每個節點id的數字。
如:192.168.10.127:dataDir為/tmp/zookeeper,id為1

則在/tmp/zookeeper目錄下建立myid的檔案,檔案內容為1即可。

4、分別登入到每臺伺服器,使用sh zkServer.sh start命令啟動zk即可。
6、zookeeper流程
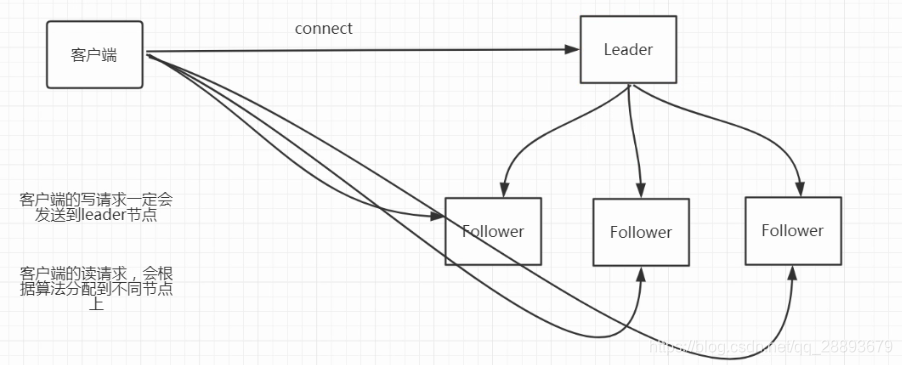
7、observer的作用
當叢集的節點需要動態擴充的時候,就可以新增observer的方式來進行新增