
Spark Streaming實時流處理筆記(2)—— 實時處理介紹
1 實時和離線計算對比
1.1 資料來源
- 離線:HDFS 歷史資料,資料量較大
- 實時:訊息佇列(Kafka)
1.2 處理過程
- 離線:Mapreduce
- 實時:Spark(DStream/SS)
1.3 處理速度
- 離線:慢
- 實時:快速
1.4 程序
- 離線:啟動,銷燬
- 實時:7x24小時
2 實時流處理框架
- Apache Storm
- Apache Spark Streaming
- IBM Stream
- Yahoo! S4
- LinkedIn Kafka
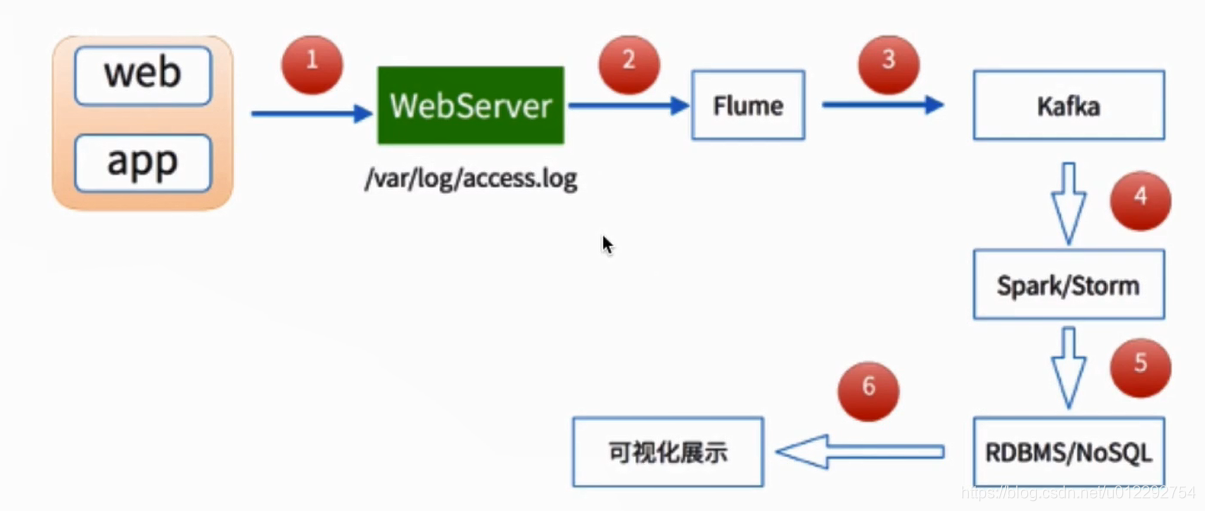
相關推薦
Spark Streaming實時流處理筆記(2)—— 實時處理介紹
1 實時和離線計算對比 1.1 資料來源 離線:HDFS 歷史資料,資料量較大 實時:訊息佇列(Kafka) 1.2 處理過程 離線:Mapreduce 實時:Spark(DStream/SS) 1.3 處理速度 離
Apache 流框架 Flink,Spark Streaming,Storm對比分析(2)
此文已由作者嶽猛授權網易雲社群釋出。 歡迎訪問網易雲社群,瞭解更多網易技術產品運營經驗。 2.Spark Streaming架構及特性分析 2.1 基本架構 基於是spark core的spark streaming架構。 Spark Streaming是將流式計算分解成一系列短小的批處理作業。這裡的批處
Spark Streaming實時流處理筆記(1)——Spark-2.2.0原始碼編譯
1 下載原始碼 https://spark.apache.org/downloads.html 解壓 2 編譯原始碼 參考 https://www.imooc.com/article/18419 https://spark.apache.org/docs/2.2.2/bu
Spark Streaming實時流處理筆記(6)—— Kafka 和 Flume的整合
1 整體架構 2 Flume 配置 https://flume.apache.org/releases/content/1.6.0/FlumeUserGuide.html 啟動kafka kafka-server-start.sh $KAFKA_HOME/config/se
Spark Streaming實時流處理筆記(5)—— Kafka API 程式設計
1 新建 Maven工程 pom檔案 <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLo
Spark Streaming實時流處理筆記(4)—— 分散式訊息佇列Kafka
1 Kafka概述 和訊息系統類似 1.1 訊息中介軟體 生產者和消費者 1.2 Kafka 架構和概念 producer:生產者(生產饅頭) consumer:消費者(吃饅頭) broker:籃子 topic : 主題,給饅頭帶一個標籤,(
Spark Streaming實時流處理筆記(3)——日誌採集Flume
1 Flume介紹 1.1 設計目標 可靠性 擴充套件性 管理性 1.2 同類產品 Flume: Cloudera/Apache,Java Scribe: Facebook ,C/C++(不維護了) Chukwa: Yahoo
大資料實時計算Spark學習筆記(2)—— Spak 叢集搭建
1 Spark 叢集模式 local: spark-shell --master local,預設的 standlone 1.複製 spark 目錄到其他主機 2.配置其他主機的環境變數 3.配置 master 節點的 slaves 檔案 4.啟動 spark
學習筆記(2)---Matlab 圖像處理相關函數命令大全
緩沖 操作 .... 命令 tor ace trac cati msh Matlab 圖像處理相關函數命令大全 一、通用函數: colorbar 顯示彩色條 語法:colorbar \ colorbar(‘vert‘) \ colorbar(‘horiz‘) \ co
Django筆記(2)Json字段處理
chang class float 類型 asc con keyword gen uri 1) Django裏面讓Model用於JSON字段,添加一個JSONField自動類型如下: [python] view plain copy class JSONField(
Kafka:ZK+Kafka+Spark Streaming集群環境搭建(三)安裝spark2.2.1
node word clas 執行 選擇 dir clust 用戶名 uil 如何配置centos虛擬機請參考《Kafka:ZK+Kafka+Spark Streaming集群環境搭建(一)VMW安裝四臺CentOS,並實現本機與它們能交互,虛擬機內部實現可以上網。》 如
Kafka:ZK+Kafka+Spark Streaming集群環境搭建(十三)定義一個avro schema使用comsumer發送avro字符流,producer接受avro字符流並解析
finall ges records ring ack i++ 一個 lan cde 參考《在Kafka中使用Avro編碼消息:Consumer篇》、《在Kafka中使用Avro編碼消息:Producter篇》 pom.xml <depende
影象處理基本概念筆記(2)
作者:cvvision 連結:http://www.cvvision.cn/8907.html 二、 22、均值濾波 均值濾波是典型的線性濾波演算法,它是指在影象上對目標畫素給一個模板,該模板包括了其周圍的臨近畫素(以目標象素為中心的周圍8個畫素,構成一個濾波模板,即去掉目標畫素本身),再用模
Apache 流框架 Flink,Spark Streaming,Storm對比分析(二)
本文由 網易雲 釋出2.Spark Streaming架構及特性分析2.1 基本架構基於是spark core的spark streaming架構。Spark Streaming是將流式計算分解成一系列短小的批處理作業。這裡的批處理引擎是Spark,也就是把Spark Str
Apache 流框架 Flink,Spark Streaming,Storm對比分析(一)
本文由 網易雲 釋出1.Flink架構及特性分析Flink是個相當早的專案,開始於2008年,但只在最近才得到注意。Flink是原生的流處理系統,提供high level的API。Flink也提供 API來像Spark一樣進行批處理,但兩者處理的基礎是完全不同的。Flink把
ROS學習筆記(2):在ROS中使用OpenCV進行簡單的影象處理---程式碼實現篇
再上一篇blog中,筆者總結了ROS系統中使用OpenCV庫的進行簡單影象處理的原理、系統相關的設定和程式包的下載。在這篇部落格中,筆者將從程式碼層面介紹如何實現在ROS系統中讀取圖片,並使用OpenCV進行影象處理,在返回結果。 例項:從ROS中讀取圖象,轉換後將彩色圖象
精通flink讀書筆記(2)——用DataStreamAPI處理資料
涉及的部分包括: 一 Execution environment flink支援的環境建立方式有: get一個已經存在的flink環境 方式為getExecutionEnvironment()create一個local環境 createLocalEnvi
Javascript高級編程學習筆記(58)—— 事件(2)事件處理程序
三個參數 ner load 對象 高級 方法 條件 只需要 結果 事件處理程序 事件處理程序即響應某個事件的函數 事件處理程序以 “on” 開頭 如“onclick”,“onload” HTML事件處理程序 某個元素支持的每種事件都可以使用一個與響應的事件處理程序同名的
Pandas學習筆記(2)資料的處理方法
準備工作 建立一個6X4的DataFrame,行索引為時間序列,列索引為字母 dates = pd.date_range('20180205',periods=6) df = pd.DataFrame(np.arange(24).reshape((6,4))
從零開始理解JAVA事件處理機制(2)
extend nds 接下來 htm ref param 簡單 tostring ansi 第一節中的示例過於簡單《從零開始理解JAVA事件處理機制(1)》,簡單到讓大家覺得這樣的代碼簡直毫無用處。但是沒辦法,我們要繼續寫這毫無用處的代碼,然後引出下一階段真正有益的代碼。